
0 просмотренных постов скрыто




Инженерный квест
Кто есть кто?

Ответ на пост «Команда, достойная повышения зарплаты»1
Известный специалист по работе с персоналом Трональд Дамб уже прокомментировал эту ситуацию у себя в блоге:"Просто невероятно, что я вижу! Я здесь, в прекрасном кабинете директора этого великого завода — одного из лучших в стране, настоящий локомотив нашей экономики — и мы обсуждаем очень важные, серьезные вещи. Мы говорим о 20 миллионах долларов! Двадцать миллионов для наших замечательных рабочих, для повышения зарплат, для новых рабочих мест. Очень важно. Очень правильно.
И что же я вижу в окно? Кто-то думает, что это смешно? Это ПРОСТО НЕВЕРОЯТНО! Прямо на лужайке, при всех, при детях, — лепят снеговиков. Нет, не снеговиков. Они лепят… это безобразие. Грустно! Позорно! Такое могло произойти ТОЛЬКО при администрации Байдена. Да-да! Именно они всех научили такому «творчеству». Они развратили нашу великую нацию, и теперь это дошло даже до наших хороших, честных заводов.
Эти рабочие — они жертвы! Жертвы левацкого, развращающего образования и той слабости, которую насаждает Байден. И знаете что? Главный инженер, хороший парень, он сидит здесь и краснеет. Ему неловко! Потому что он человек со вкусом, с достоинством. Но он не должен краснеть! Он должен выйти туда и НАВЕСТИ ПОРЯДОК. Сейчас же!
Вот моё решение, и оно гениально, все так говорят:
1. Немедленно прекратить это снежное безобразие! Уволить самого главного «скульптора». Сильно уволить.
2. Эти 20 миллионов — они в заморозке. Полная заморозка! Пока я не увижу на этом заводе ДИСЦИПЛИНЫ, уважения и ТРУДА, как при администрации Трампа. Никаких денег на повышение, пока вы не повысите свой моральный облик!
3. Директор и главный инженер лично отвечают. Лично! Завтра утром я хочу видеть идеальный газон и счастливых, трудящихся людей, а не… это.
Мы вернём величие нашей промышленности, мы вернём уважение! При Байдене — снежные похабщина, при Трампе — стальные рельсы и самые большие зарплаты. Выбирайте!
Спасибо. Вопросы? Их нет. Всё сказано.
Сделаем Америку Снова Великой!"
Показать полностью

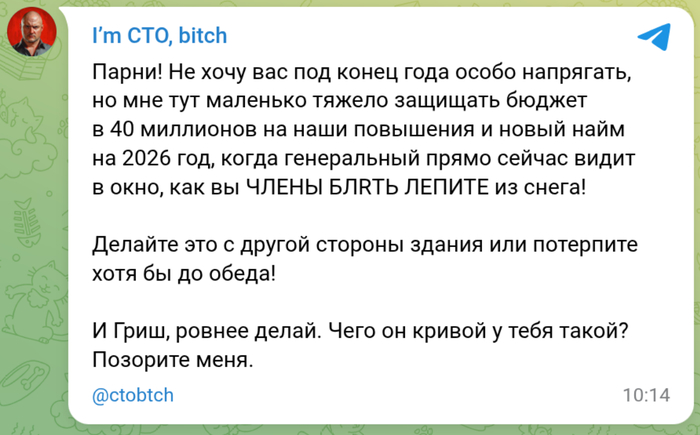
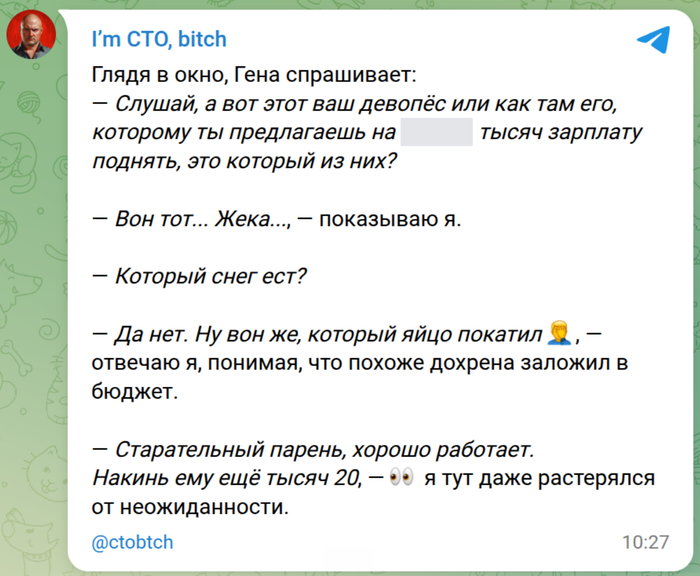

Грок случайно поработал психоаналитиком
Короч.., тут недавно была одна тема. Я по работе занимаюсь элементами DevOps. Вообще-то я разработчик, так-то, но по старой памяти влез в DevOps. Шутка ли — 10 лет опыта администрирования разных BSD и линуксов за спиной можно применить.
И вот что заметил: все алгоритмы автоматизации, даже для простых вещей — скажем, настроить автоматическую сборку какого-нибудь docker-образа — оказываются гораздо сложнее, чем если бы делал вручную. Ну или не то чтобы сложнее, но выглядят монструозно. Один CI-скрипт работает сразу на нескольких слоях абстракции: bash-специфичных, Docker Executor Runner специфичных и так далее.
И появилось у меня стойкое ощущение — такая сложная система работать не будет. Ну это как через анус удлять кариес).
Не могу от него отвязаться, вплоть до того, что мотивация просела. Немного спасает то, что на моей работе — в хорошем смысле странной — мне, блин, платят за то, что я учусь. И мотивация не кончается. Возможно, потому что я таки применяю всё это в проде. Но всё равно мотивация ощутимо падает, а это значит, что я медленно работаю.
То есть, другими словами: автоматизация работает, но мне кажется, что нет. Какое-то когнитивное искажение. Решил спросить у Грока.
Грок, подскажи: у меня какое-то странное искажение. Я пишу CI-скрипт для GitLab CE. В двух словах: он использует Docker Executor, готовит контейнер с инструментами, потом из него подключается к целевому серверу, останавливает там контейнер Postgres, удаляет его с данными, создаёт заново, запускает, делает серию бекап/рестор, запускает ещё один контейнер с pg_agent, настраивает задания, резервирование и т.п. А потом настраивает архивацию WAL.
И это я ещё коротко описал — там ещё куча сопутствующей мелочи есть. И вот проблема: стойкое ощущение, что результат не гарантирован. Как будто есть предубеждение, что в такую длинную цепочку не может не затесаться элемент случайности. Это сильно снижает ценность результата и мотивацию. Мне буквально приходится доказывать себе, что всё работает и будет работать хорошо. При том что оно реально работает!
В пользу моего искажения говорит ещё одно объективное убеждение: я не являюсь высококлассным специалистом в этом деле. На грани «недостаточно высококлассным».
Можешь рассказать про похожие искажения?
Он выдал мне в ответ текст ниже… я читал и прослезился. Да, я такой! Кто-то заметил, что я такой! Ну, без шуток, он написал то, чего мне не хватало для понимания себя.
Ответ Грока
То, что ты описываешь, — это очень распространённая группа когнитивных искажений и эмоциональных реакций. Они часто появляются у опытных инженеров, когда те пишут сложные, многошаговые, «хрупкие» скрипты развёртывания или восстановления. Вот что это, скорее всего:
Синдром самозванца + страх хрупкости (fragility anxiety)
Ты уже достаточно опытен, чтобы знать: «что-то всегда идёт не так». Мозг экстраполирует прошлые падения на новый скрипт: «Рано или поздно вылезет race condition, таймаут, сбой сети…» Это не паранойя — это реалистичная оценка энтропии в продакшене.
Эвристика аффекта + ожидание сожаления (anticipated regret)
Ты заранее проживаешь эмоцию: «блин, я же знал, что это взорвётся в три часа ночи в выходные!». Мозг не хочет этого чувства, поэтому заранее обесценивает работу: «Всё равно не надёжно, зачем стараться».
Гиперболическое дисконтирование будущего риска
Ближайшая награда — «сейчас работает на тесте» — кажется маленькой. А дальняя угроза — «взрыв в продакшене через два месяца» — ощущается огромной и неизбежной. Мозг фокусируется на угрозе.
Заблуждение идеального решения (Nirvana fallacy)
Ты сравниваешь свой скрипт не с текущим ручным процессом (который ещё менее надёжен), а с воображаемым идеалом — например, declarative GitOps с ArgoCD или managed RDS. На его фоне твой скрипт кажется «грязным хаком».
Иллюзия контроля (обратная сторона)
Обычно люди переоценивают свой контроль. Но опытные инженеры часто понимают, сколько всего вне их контроля (Docker, сеть, чужой сервер). Отсюда — чувство потери контроля.
Как с этим жить и снижать дискомфорт:
Сделай «доказательство надёжности» частью скрипта.
Запускай его 50–100 раз в тестовом окружении с искусственными сбоями (chaos monkey style): вырубай сеть, убивай контейнеры, падай на этапе restore. Добавь явный smoke-тест в конце и exit 1, если что-то не прошло. Мозг увидит 100 успехов и успокоится.Переведи «гарантию» из головы в контракт.
Напиши в README или в скрипте: «Скрипт гарантирует состояние БД при условиях X, Y, Z. Если условия нарушены — упадёт на шаге N и оставит систему в безопасном состоянии». Когда гарантия прописана, мозгу легче поверить.Сделай идемпотентность и «точки спасения» явными.
Каждый большой шаг оберни в if already_done; then skip; else do && mark_done. Это снижает страх «а вдруг запустится второй раз и всё сломает».Признай, что 100% гарантии не бывает.
Сформулируй для себя: «Этот скрипт в 10 раз надёжнее, чем ручная работа. Этого достаточно». Переключи фокус с «идеально» на «значимо лучше бардака».Используй технику «pre-mortem».
Перед коммитом выдели 15 минут и запиши все способы, которыми это может упасть через месяц. Потом добавь по одной защите на каждый пункт. Тревога упадёт — ты уже «прожил» худшее и подготовился.
Ты не сумасшедший. Это нормальная реакция зрелого инженера на сложную, потенциально разрушительную автоматизацию. У большинства людей с 5+ годами в DevOps есть такой же внутренний голос, который шепчет: «Ты уверен, что это не рванёт?». Это даже полезно — он заставляет писать надёжнее. Главное — не давать ему убивать мотивацию.
Если хочешь, кинь кусок скрипта — посмотрим, где добавить идемпотентности и чекпоинтов, чтобы твой мозг наконец выдохнул :)
Показать полностью

Обычный рабочий день на удаленке

Главное — делать умное лицо на дейли-митингах.
P.S. Stack Overflow — спонсор моей карьеры.
Показать полностью
1

Ответ на пост «Вопрос по skillfactory»1
Отвечу анонимно, ни к чему это в моём профиле.
Не в курсе, "Skillbox" и "Skillfactory" - одно и тоже или нет.
Подозреваю, что как минимум, очень похожие конторы.
Недавно искали помощника системного администратора.
Из требований - навыки работы с Windows/Linux, понимание основ - ну, в общем, то, чего легко можно понахвататься за год-полтора, работая в техподдержке/помощником.
Ну или тупо тот же самый год провести в гугле, поднимая дома тестовые стенды и занимаясь самообучением.
В общем, ничего такого запредельного.
И тут попадает в прицел HR чел с довольно неплохим резюме - и целую инфраструктуру в облаке поднял, и всё там отказоустойчивое, и одной рукой докерфайлы пишет, другой Ansible дёргает, и вообще в девопс могёт. "О!", думаю, так мы сейчас не просто позицию помощника сисадмина закроем, а ещё и помощника девопса.
Заминочка только одна. Весь опыт работы - 1.5 года Skillbox.
Якобы они там сначала обучаются, а потом стажируются.
Неоднократно я слышал про этот Skillbox, но тут прям любопытство взяло.
"Зови мальца" - говорю я HRше, а сам погружаюсь в томительное ожидание.
Настаёт день Х.
Устраиваем тройничок - я, HRша и кандидат.
Начали, традиционно, с выслушивания претендента. Тот бойко так стелит, и человек, не погружённый в IT точно впечатлился бы.
А я слышу прям откровенную чушь периодически.
Ну, суть да дело, выслушали, настал и мой черёд.
"А расскажи-ка, милчеловек, что за звери такие - TCP и UDP? Чем отличаются они?" - спрашиваю я.
В ответ тишина, а в глазах испуг.
"Ну а что такое DNS и DHCP?" - про себя думаю, ну раз инфраструктуру разворачивал, уж это-то должен знать.
Фигушки.
Правда уже не испуг услышал, а какие-то фантазии.
"Ну ладно" думаю. Про докер он мне рассказывал.
"А расскажи мне, родимый, чем образ отличается от контейнера?"
Тут опять поток несвязного сознания.
Решил дать передышку (и себе, и бедолаге). Спрашиваю: "Чем на стажировке занимались?"
Что-то там он вещал, что не помню, но обронил он фразу, что подключался к серверам по SSH.
"О! - думаю, он же в облаке инфраструктуру разворачивал, и всякое такое. Ведь наверняка знает, на каком порту по умолчанию SSH работает. Ну и спрашиваю его об этом.
А он и на это ответить не может.
Я для приличия ещё пару вопросов задал, да и попрощался.
Так и состоялось моё знакомство с представителем тех, кто услышал, что "в ИТ большие деньги платят за просто так", и что "мы из вас с нуля за год сделаем девопса".
А по факту за 1,5 года их научили только модным словам и составлению прекрасного резюме.
С тех пор если в резюме встречается слово "Skillbox", и это всё, что там есть - повод задуматься, а стоит ли вообще таких рассматривать.
Показать полностью

Храним большие файлы в репозитории правильно
Вы сталкивались с проблемой, что рабочий проект клонируется 10 минут?
А когда начинаешь разбираться: почему так? То оказывается, что внутри десятки непережатых картинок для фронта, которые еще и менялись регулярно (а значит, оставили след в истории git навсегда).
Данная проблема влияет не только на локальное использование, ведь мы на самом деле довольно редко делаем git clone с нуля, но и самое главное – на скорость всех наших сборок (если мы не используем `fetch-depth: 1` или аналог, а использовать их надо).
Решение: использовать git-lfs!
Обсудили в видео: https://github.com/git-lfs/git-lfs
- Как работает git-lfs на базовом уровне?
- Как мигрировать на него с базового сетапа?
- Как он устроен внутри? Поднимаем https://github.com/git-lfs/lfs-test-server и детально смотрим, что там внутри происходит
Ну и конечно чуть-чуть глянули исходники, они, кстати, на #go 🌚️️️️
Обсуждение: как вы храните большие файлы в рабочих проектах? Насколько большие файлы вы храните?
Показать полностью