


Типы айтишников





Показать полностью
7
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).
Настоящее исследование осуществлено с применением инструментария pg_expecto, обеспечивающего строгую методологию репрезентативного нагрузочного тестирования. Данный инструмент позволил провести сравнительный анализ двух дискретных конфигураций СУБД PostgreSQL в контролируемых и идентичных условиях, моделирующих устойчивую OLAP-нагрузку. Ниже представлено краткое изложение методологии эксперимента, включая описание стенда, генерации нагрузочного паттерна и ключевых варьируемых параметров, что обеспечивает полную воспроизводимость и верифицируемость полученных результатов. Основной целью являлась эмпирическая проверка гипотезы о влиянии реконфигурации областей памяти (shared_buffers и work_mem) на комплексные показатели производительности системы.

pg_expecto: где гипотезы встречаются с метриками.
Для данной OLAP-нагрузки и текущей конфигурации сервера снижение размера shared_buffers с 4 ГБ до 1-2 ГБ, с одновременным увеличением work_mem, приведет к росту общей производительности системы. Основная цель — не просто уменьшить кэш БД, а перенаправить высвободившуюся оперативную память на выполнение операций в памяти и ослабить нагрузку на подсистему ввода-вывода.
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 30
vm.dirty_background_ratio = 10
vm.vfs_cache_pressure = 100
vm.swappiness = 10
read_ahead_kb = 4096
work_mem
----------
32MB
shared_buffers
----------------
4GB
work_mem
----------
256MB
shared_buffers
----------------
2GB
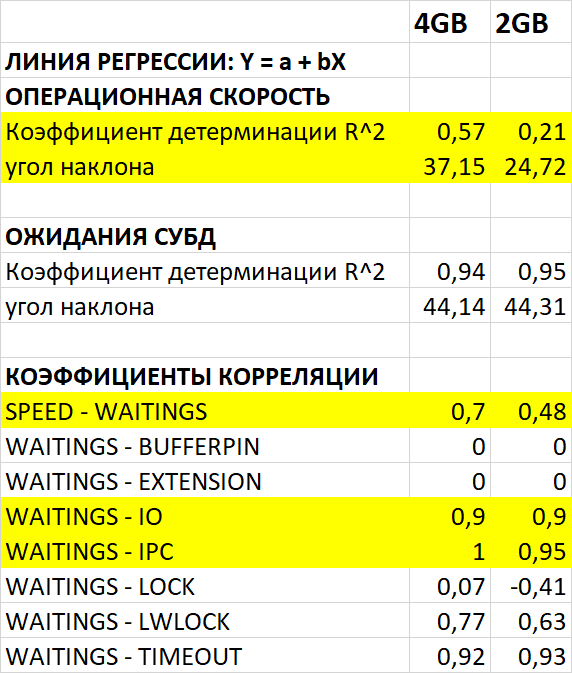
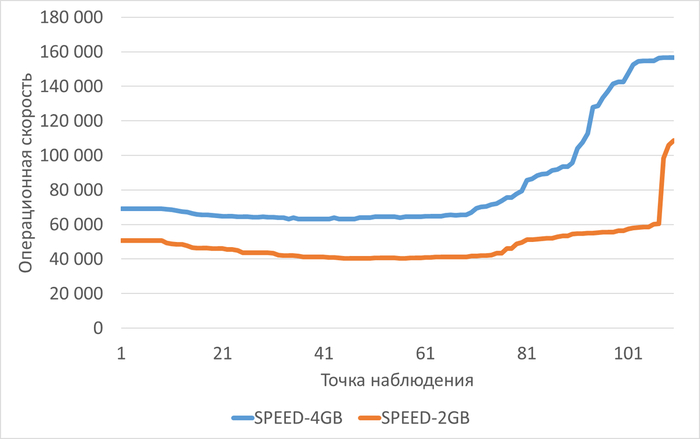
Среднее снижение операционной скорости при shared_buffers=2GB(work_mem=256MB) составило 38.38%.
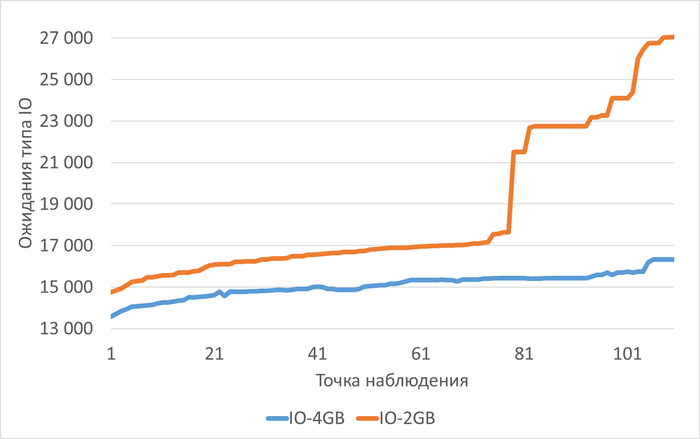
Среднее увеличение ожиданий типа IO при shared_buffers=2GB(work_mem=256MB) составило 22.70%.
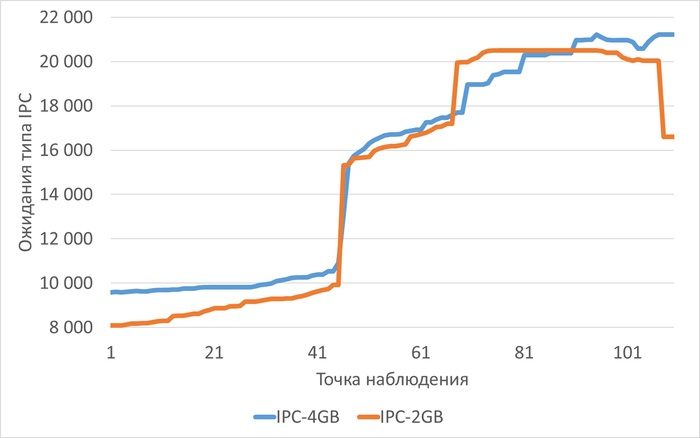
Среднее снижение ожиданий типа IPC при shared_buffers=2GB(work_mem=256MB) составило 4.78%.
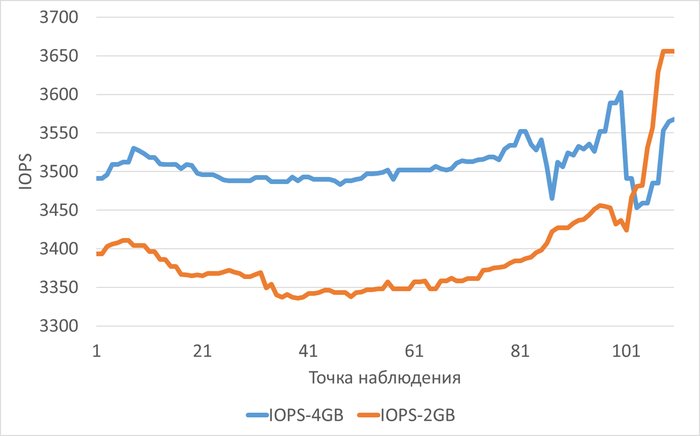
Среднее снижение IOPS при shared_buffers=2GB(work_mem=256MB) составило 3.29%.
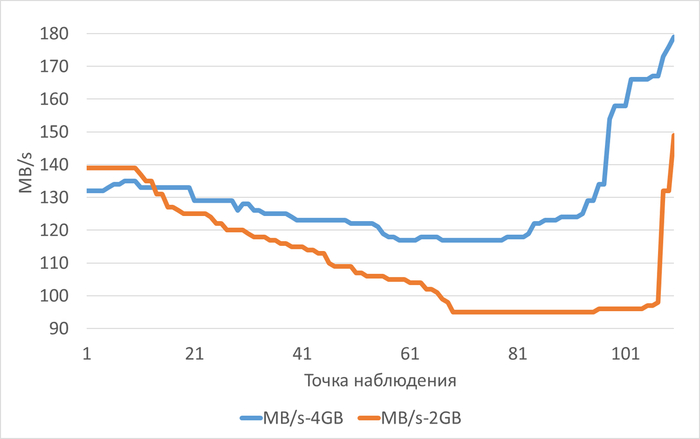
Среднее снижение пропускной способности(MB/s) при shared_buffers=2GB(work_mem=256MB) составило 313.74%.
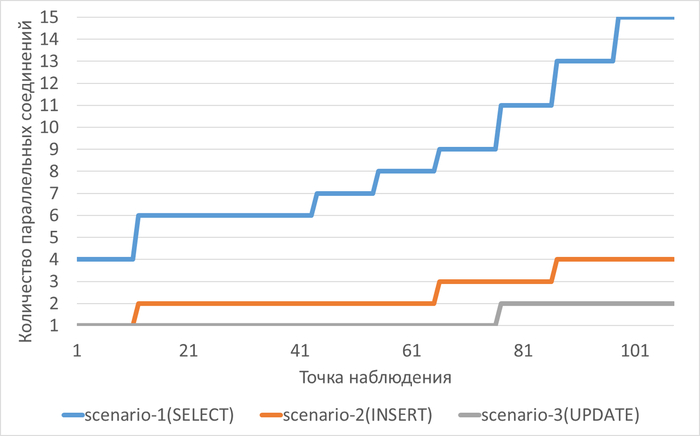
Нагрузка соответствует OLAP-сценарию (аналитические запросы, большие объёмы данных).
В обоих экспериментах наблюдался рост нагрузки (Load average увеличился с 5 до 22).
Параметры экспериментов:
Эксперимент-1: shared_buffers = 4GB, work_mem = 32MB
Эксперимент-2: shared_buffers = 2GB, work_mem = 256MB
Высокий I/O wait (wa): 100% наблюдений с wa > 10%.
Корреляция ожиданий IO и записи (bo): высокая (0.6533), система ограничена производительностью записи на диск.
Состояние процессов (b): слабая корреляция с ожиданиями IO (0.2611), количество процессов в состоянии непрерываемого сна не возрастает значительно.
Отношение прочитанных блоков к изменённым: 177.98, подтверждение OLAP-нагрузки.
Высокий I/O wait (wa): 97.27% наблюдений с wa > 10%.
Корреляция ожиданий IO и записи (bo): высокая (0.6719), система также ограничена записью.
Состояние процессов (b): очень высокая корреляция с ожиданиями IO (0.8774), процессы всё чаще переходят в состояние непрерываемого сна (ожидание диска).
Отношение прочитанных блоков к изменённым: 268.01, нагрузка ещё более ориентирована на чтение.
Уменьшение shared_buffers с 4GB до 2GB привело к усилению корреляции между ожиданием IO и блокированными процессами.
В обоих случаях система ограничена производительностью записи, но во втором эксперименте дисковые ожидания сильнее влияют на состояние процессов.
Свободная RAM: менее 5% в 100% наблюдений.
Свопинг (swap in/out): используется незначительно (в 9.01% и 1.8% наблюдений соответственно).
Свободная RAM: менее 5% в 100% наблюдений.
Свопинг: не используется (0% наблюдений).
Оба эксперимента показывают критически низкое количество свободной RAM.
Свопинг практически отсутствует, что может указывать на эффективное использование файлового кэша ОС.
Hit Ratio: 55.36% (критически низкий).
Корреляция hit/read: очень высокая (0.9725), кэширование связано с большим чтением с диска.
Hit Ratio: 38.58% (ещё ниже, критически низкий).
Корреляция hit/read: очень высокая (0.8698), аналогичная картина.
Уменьшение shared_buffers с 4GB до 2GB привело к снижению Hit Ratio на ~16.78%.
В обоих случаях кэширование недостаточно эффективно для данной нагрузки.
Корреляция LWLock и user time: очень высокая (0.9775).
Корреляция LWLock и system time: очень высокая (0.9092).
Очередь процессов (r): превышение числа ядер CPU в 16.22% наблюдений.
System time (sy): не превышает 30% (все наблюдения).
Корреляция LWLock и user time: очень высокая (0.8574).
Корреляция LWLock и system time: высокая (0.6629).
Очередь процессов (r): превышение числа ядер CPU в 3.64% наблюдений.
System time (sy): не превышает 30% (все наблюдения).
В Эксперименте-1 выше корреляция LWLock с системным временем, что может указывать на большее количество системных вызовов и переключений контекста.
Очередь процессов (r) чаще превышает число ядер CPU в Эксперименте-1, но в обоих случаях это не является критичным.
Уменьшение shared_buffers с 4GB до 2GB:
Привело к снижению Hit Ratio (с 55.36% до 38.58%).
Усилило корреляцию между ожиданием IO и блокированными процессами.
Не вызвало существенных изменений в использовании свопинга и свободной RAM.
Увеличение work_mem с 32MB до 256MB:
Не компенсировало снижение эффективности кэширования при уменьшении shared_buffers.
Не привело к значительным изменениям в поведении CPU и очереди процессов.
Общий характер нагрузки (OLAP) подтверждается высоким отношением чтения к записи и сильной зависимостью производительности от операций ввода-вывода.
Диск данных: vdd (100 ГБ, LVM-том 99 ГБ, точка монтирования /data)
Конфигурация сервера:
8 CPU ядер
8 ГБ RAM
Отдельные диски для WAL (/wal) и логов (/log)
Параметры сравнения:
Эксперимент 1: shared_buffers = 4 ГБ, work_mem = 32 МБ
Эксперимент 2: shared_buffers = 2 ГБ, work_mem = 256 МБ
Продолжительность тестов: ≈110 минут каждый
Эксперимент 1 (shared_buffers=4GB, work_mem=32MB):
Средняя утилизация диска: 90-94% → 80% (снижение к концу теста)
Средний IOPS: ≈3500 операций/сек
Средняя пропускная способность: ≈130 МБ/с → 180 МБ/с (рост к концу)
Среднее время ожидания чтения: 9-14 мс
Среднее время ожидания записи: 6-7 мс
Средняя длина очереди: ≈43
Средняя загрузка CPU на IO: ≈24%
Эксперимент 2 (shared_buffers=2GB, work_mem=256MB):
Средняя утилизация диска: 93-97% (стабильно высокая)
Средний IOPS: ≈3400 операций/сек
Средняя пропускная способность: ≈139 МБ/с → 95-149 МБ/с (колебания)
Среднее время ожидания чтения: 10-19 мс
Среднее время ожидания записи: 7-10 мс
Средняя длина очереди: ≈33 → 61 (рост)
Средняя загрузка CPU на IO: ≈28% → 9% (снижение)
Эксперимент 1:
Тип ограничения: Пропускная способность диска
Корреляция скорость-MB/s: Очень высокая (0.8191)
Корреляция скорость-IOPS: Слабая (0.4128)
Вывод: Производительность определяется объемом передаваемых данных
Эксперимент 2:
Тип ограничения: Количество операций ввода-вывода
Корреляция скорость-IOPS: Очень высокая (0.9256)
Корреляция скорость-MB/s: Слабая (0.1674)
Вывод: Нагрузка чувствительна к количеству IO операций
Эксперимент 1 (shared_buffers=4GB):
Утилизация диска снижается с 94% до 80% к концу теста
Пропускная способность растет с 132 МБ/с до 180 МБ/с
Загрузка CPU на IO снижается с 28% до 18%
Стабильные показатели IOPS и времени отклика
Эксперимент 2 (shared_buffers=2GB):
Высокая и стабильная утилизация диска (93-97%)
Колебания пропускной способности (139 → 95 → 149 МБ/с)
Значительный рост длины очереди (33 → 61)
Увеличение времени ожидания чтения (10 → 19 мс)
Снижение загрузки CPU на IO (28% → 9%)
Утилизация диска: Повысилась и стабилизировалась на высоком уровне
Время отклика: Увеличилось время ожидания операций чтения
Длина очереди: Выросла в 1.8 раза к концу теста
Загрузка CPU на IO: Снизилась в 3 раза
Характер нагрузки: Сместился с пропускной способности на IOPS-ограниченный режим
Стабильность пропускной способности: Ухудшилась, появились значительные колебания
Обеспечивает более предсказуемую пропускную способность
Демонстрирует улучшение производительности в ходе теста
Оптимальна для операций, требующих последовательного чтения больших объемов данных
Меньшая длина очереди и время отклика
Создает более высокую и стабильную нагрузку на диск
Приводит к увеличению времени отклика операций
Смещает характер нагрузки в сторону большего количества мелких операций
Снижает нагрузку на CPU для операций ввода-вывода
Увеличивает глубину очереди запросов к диску
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

PostgreSQL и ядро Linux: поиск оптимального взаимодействия.
В условиях растущих требований к обработке больших данных и аналитическим нагрузкам (OLAP) критически важной становится не только настройка самой СУБД, но и тонкая оптимизация операционной системы, на которой она работает. Однако в современных исследованиях и практических руководствах наблюдается значительный пробел: рекомендации по настройке PostgreSQL часто ограничиваются параметрами самой СУБД, в то время как влияние параметров ядра Linux на производительность базы данных остаётся малоизученной областью.
Данная работа направлена на заполнение этого пробела. Фокус исследования сосредоточен на влиянии параметра ядра Linux vm.vfs_cache_pressure на производительность PostgreSQL под синтетической OLAP-нагрузкой. Этот параметр контролирует агрессивность, с которой ядро освобождает кэш файловой системы (VFS cache), что в теории может напрямую влиять на поведение СУБД, активно работающей с файлами данных.
Исследование носит экспериментальный характер и построено на методологии нагрузочного тестирования с использованием специализированного инструмента pg_expecto. В качестве тестовой среды используется конфигурация, типичная для небольших аналитических серверов: 8 CPU, 8 GB RAM, дисковая подсистема, подверженная ограничениям пропускной способности. Это позволяет смоделировать условия, в которых грамотная настройка ОС может стать ключом к раскрытию дополнительной производительности или, наоборот, источником проблем.
Ценность данной работы заключается в её практической ориентированности. Она предоставляет администраторам баз данных и системным инженерам не только конкретные данные о влиянии настройки, но и методологию анализа комплексного поведения системы (СУБД + ОС) под нагрузкой, выходящую за рамки простого мониторинга TPS (транзакций в секунду).
Отсутствие специализированных исследований: Поиск в научных базах данных (Google Scholar, IEEE Xplore) и технических блогах по запросам "vfs_cache_pressure PostgreSQL performance", "Linux kernel tuning for database workload" не выявил работ, фокусирующихся на экспериментальном изучении данного конкретного взаимодействия. Основная масса материалов предлагает общие советы или рассматривает настройку памяти PostgreSQL в отрыве от тонких параметров ОС.
Оценить влияние изменения параметра vm.vfs_cache_pressure на производительность СУБД и инфраструктуры при синтетической нагрузке, имитирующей OLAP.
vm.dirty_expire_centisecs=3000
vm.dirty_ratio=30
vm.dirty_background_ratio=10
vm.swappiness=10
read_ahead_kb=4096
shared_buffers = '4GB'
effective_cache_size = '6GB'
work_mem = '32MB'
Отношение прочитанных блоков shared_buffers к измененным блокам shared_buffers (OLAP):
vm.vfs_cache_pressure = 100 : 177.98
vm.vfs_cache_pressure = 50 : 184.26
vm.vfs_cache_pressure = 150 : 172.22
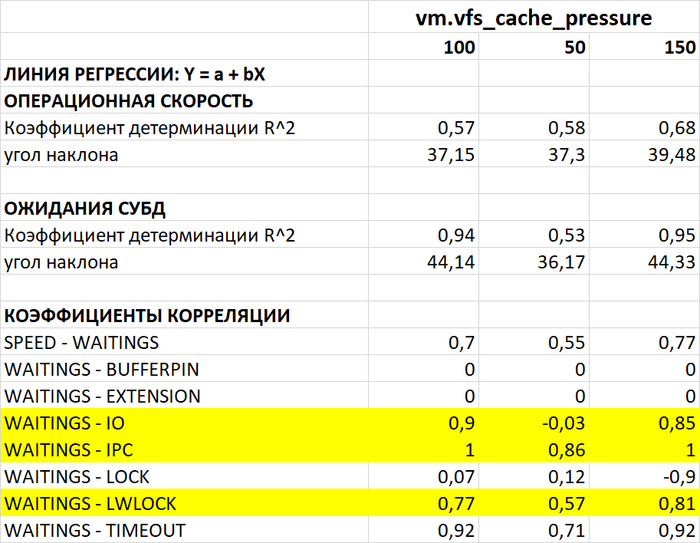
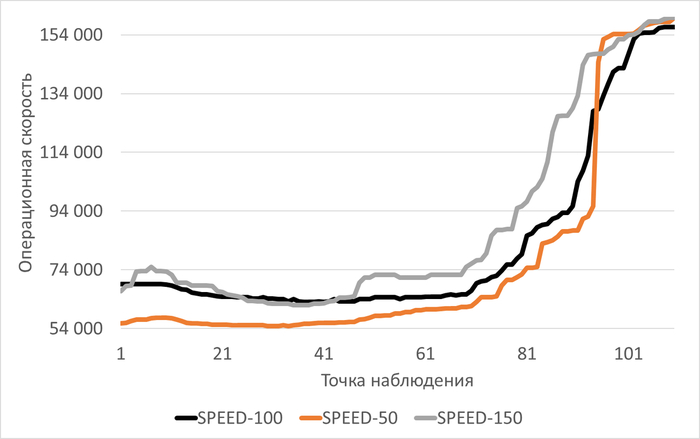
Медианные значения операционной скорости:
vm.vfs_cache_pressure = 100 : 15 154 (baseline)
vm.vfs_cache_pressure = 50 : 16 185 (-11.27%)
vm.vfs_cache_pressure = 150 : 15 095 (+8.65%)
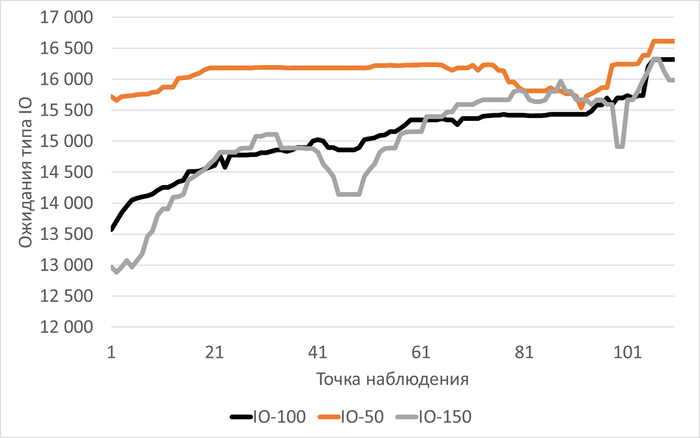
Медианные значения ожиданий типа IO:
vm.vfs_cache_pressure = 100 : 16 716 (baseline)
vm.vfs_cache_pressure = 50 : 19 411 (+16,12%)
vm.vfs_cache_pressure = 150 : 16 762 (+0,27%)
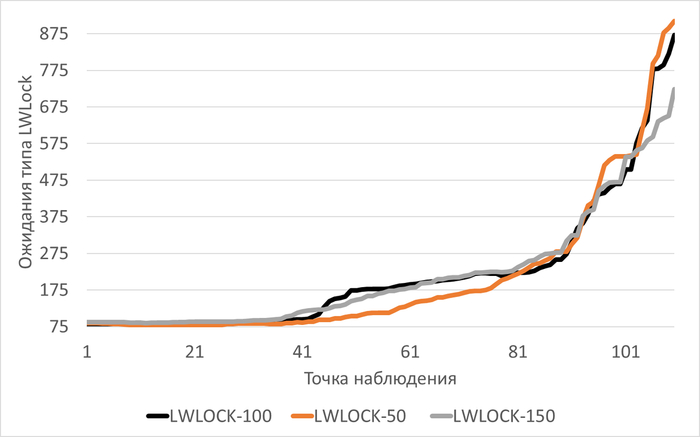
Медианные значения ожиданий типа LWLock:
vm.vfs_cache_pressure = 100 : 178(baseline)
vm.vfs_cache_pressure = 50 : 113 (-36,52%)
vm.vfs_cache_pressure = 150 : 167 (-6,46%)
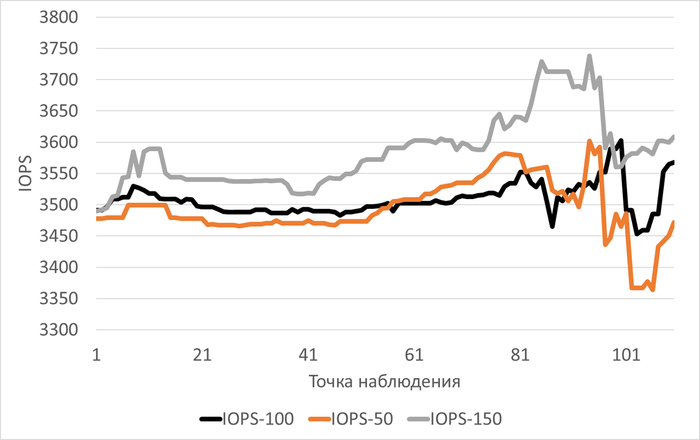
Медианные значения IOPS:
vm.vfs_cache_pressure = 100 : 3 502(baseline)
vm.vfs_cache_pressure = 50 : 3 479(-0,66%)
vm.vfs_cache_pressure = 150 : 3 582 (+2,28%)
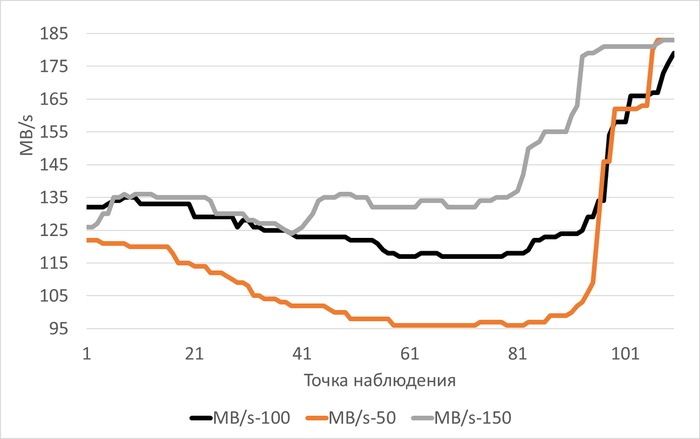
Медианные значения MB/s:
vm.vfs_cache_pressure = 100 : 125(baseline)
vm.vfs_cache_pressure = 50 : 103(-17,60%)
vm.vfs_cache_pressure = 150 : 135 (+8,00%)
Входные данные для анализа
Сводный отчета по нагрузочному тестированию подготовленный pg_pexpecto по окончании нагрузочного тестирования:
Метрики производительности и ожиданий СУБД
Метрики vmstat
Метрики iostat
Корреляционный анализ ожиданий СУБД
Корреляционный анализ метрик vmstat
Корреляционный анализ метрик iostat
Общая проблема: Во всех трёх экспериментах 100% наблюдений показывают wa > 10%, что свидетельствует о системном ограничении дисковой подсистемы.
Сравнение корреляций при разных значениях vm.vfs_cache_pressure:
vm.vfs_cache_pressure=50:
Корреляция IO-wa: -0,0772 (отсутствует/отрицательная) ✅
Корреляция IO-b: 0,0609 (слабая/средняя) ℹ️
Корреляция IO-bi: 0,3650 (слабая/средняя) ℹ️
Корреляция IO-bo: 0,2693 (слабая/средняя) ℹ️
vm.vfs_cache_pressure=100:
Корреляция IO-wa: -0,9020 (отсутствует/отрицательная) ✅
Корреляция IO-b: 0,2611 (слабая/средняя) ℹ️
Корреляция IO-bi: 0,2730 (слабая/средняя) ℹ️
Корреляция IO-bo: 0,6533 (высокая) ⚠️
vm.vfs_cache_pressure=150:
Корреляция IO-wa: -0,7379 (отсутствует/отрицательная) ✅
Корреляция IO-b: 0,0000 (отсутствует/отрицательная) ✅
Корреляция IO-bi: 0,5074 (высокая) ⚠️
Корреляция IO-bo: 0,5532 (высокая) ⚠️
Вывод: Увеличение vfs_cache_pressure усиливает корреляцию IO-ожиданий с операциями чтения/записи (bi/bo), что указывает на более агрессивное управление кэшем файловой системы.
Наблюдаемый феномен:
· При vfs_cache_pressure=50: ALARM по регрессионной линии (R²=0,7, угол наклона 39,83)
· При vfs_cache_pressure=100: R²=0,03, угол наклона 10,38 (норма)
· При vfs_cache_pressure=150: R²=0,00, угол наклона 0,00 (норма)
Объяснение с точки зрения управления кэшем:
При низком значении vfs_cache_pressure(50) ядро менее агрессивно вытесняет кэш файловой системы
Это приводит к накоплению большего объёма кэшированных данных
При OLAP-нагрузке с интенсивным чтением это вызывает:
Более частые блокировки процессов в состоянии D при обращении к диску
Увеличение времени ожидания из-за конкуренции за IO-ресурсы
При значениях 100 и 150 кэш вытесняется активнее, что снижает конкуренцию и количество процессов в состоянии D
Общие характеристики нагрузки (все эксперименты):
Соотношение чтения к записи: ~180:1 (типичный OLAP-паттерн)
Очень высокая корреляция скорости операций с чтением (0,85-0,88)
Очень высокая корреляция скорости операций с записью (0,98-0,99)
Система ограничена производительностью диска
Влияние pressure на эффективность shared buffers:
HIT RATIO shared buffers: 55-58% (критически низкий во всех случаях)
Корреляция shared_blks_hit - shared_blks_read: 0,96-0,97 (очень высокая)
Вывод: vfs_cache_pressure практически не влияет на HIT RATIO PostgreSQL, так как shared buffers управляются отдельно от кэша файловой системы
Лучшие показатели у pressure=100:
Отсутствие роста процессов в состоянии D
Умеренные корреляции с операциями чтения/записи
Стабильное поведение системы
Проблемные зоны (все эксперименты):
Критически низкий HIT RATIO shared buffers (55-58%)
100% наблюдений с wa > 10%
Система ограничена производительностью диска
Рекомендации по оптимизации для OLAP-нагрузки
1. Настройки операционной системы:
Установить vm.vfs_cache_pressure = 100 (компромиссное значение)
Пересмотреть настройки vm.dirty_*:
Уменьшить vm.dirty_background_ratio с 10 до 5
Уменьшить vm.dirty_ratio с 30 до 20
Это снизит латентность записи
Проверить и оптимизировать параметры файловой системы
2. Настройки PostgreSQL для OLAP:
Увеличить shared_buffers с 4GB до 6GB (при 8GB RAM)
Увеличить work_mem с 32MB до 128-256MB для сложных сортировок
Увеличить effective_cache_size до 6-7GB
Рассмотреть увеличение max_parallel_workers_per_gather с 1 до 2-4
Установить random_page_cost = 1.0 (если используются SSD)
3. Аппаратные улучшения:
Рассмотреть переход на более быстрые диски (NVMe SSD)
Увеличить объём оперативной памяти с 8GB
Проверить балансировку нагрузки между дисками данных и WAL
Общая ситуация:
Во всех экспериментах свободная RAM < 5% в более 50% наблюдений - это норма для сервера с активной нагрузкой
Оперативная память практически полностью используется (7-7.2GB из 8GB)
Динамика memory_swpd (использование свопа):
vfs_cache_pressure=50: Рост с 209 MB до 347 MB (+138 MB за 110 минут)
vfs_cache_pressure=100: Рост с 260 MB до 328 MB (+68 MB за 111 минут)
vfs_cache_pressure=150: Рост с 246 MB до 338 MB (+92 MB за 110 минут)
Анализ скорости роста:
Наиболее медленный рост swpd при vfs_cache_pressure=100 (68 MB за период)
Наиболее быстрый рост при vfs_cache_pressure=50 (138 MB за период)
Промежуточный рост при vfs_cache_pressure=150 (92 MB за период)
Стабильность использования памяти:
Наиболее стабильное поведение при vfs_cache_pressure=100:
Наименьший рост использования свопа
Плавное изменение memory_swpd без резких скачков
Более предсказуемое управление памятью
Наименее стабильное поведение при vfs_cache_pressure=50:
Быстрый рост использования свопа
Более агрессивное вытеснение данных в своп
Статистика по экспериментам:
vfs_cache_pressure=50:
swap in: 10% наблюдений
swap out: 6.36% наблюдений
Баланс смещен в сторону чтения из свопа
При vfs_cache_pressure=100:
swap in: 9.01% наблюдений
swap out: 1.80% наблюдений
Минимальный объем записи в своп
vfs_cache_pressure=150:
swap in: 10% наблюдений
swap out: 11.82% наблюдений
Наибольший объем записи в своп
Объяснение различий:
1. vfs_cache_pressure=50:
Низкое давление на кэш файловой системы
Ядро менее агрессивно освобождает кэш
Чаще приходится читать из свопа (высокий swap in)
Относительно низкий swap out - меньше данных вытесняется
2. vfs_cache_pressure=100:
Оптимальный баланс
Кэш управляется эффективно
Минимальный swap out - редко требуется запись в своп
Умеренный swap in - меньше обращений к свопу
3. vfs_cache_pressure=150:
Высокое давление на кэш файловой системы
Ядро агрессивно освобождает кэш
Высокий swap out - активная запись в своп
Высокий swap in - частые чтения из свопа
Взаимодействие vfs_cache_pressure с настройками vm.dirty_*:
Текущие настройки:
vm.dirty_ratio=30 (запись блокируется при 30% dirty pages)
vm.dirty_background_ratio=10 (фоновая запись при 10%)
read_ahead_kb=4096 (4MB read-ahead)
Влияние pressure на dirty pages:
1. vfs_cache_pressure=50:
Медленное освобождение кэша
Больше данных остается в памяти
Более высокий риск достижения dirty_ratio
Потенциальные блокировки записи при всплесках нагрузки
2. vfs_cache_pressure=100:
Сбалансированное управление
Кэш освобождается своевременно
Меньше риск блокировок из-за dirty pages
Оптимально для текущих настроек dirty_*
3. vfs_cache_pressure=150:
Быстрое освобождение кэша
Меньше данных в кэше файловой системы
Чаще требуется чтение с диска
Возможна излишняя агрессивность для OLAP
Для OLAP с большим чтением рекомендуется:
vfs_cache_pressure=100-120 (компромиссное значение)
read_ahead_kb=8192-16384 (увеличение для последовательного чтения)
vm.dirty_background_ratio=5 (более частая фоновая запись)
vm.dirty_ratio=20 (раньше начинать синхронную запись)
Обоснование:
OLAP характеризуется последовательным чтением больших объемов данных
Большой read-ahead улучшает производительность последовательного чтения
Более низкие dirty_* значения снижают латентность записи
vfs_cache_pressure=100 обеспечивает баланс между кэшированием и доступной памятью
Ключевые наблюдения:
Все эксперименты показывают очень высокую корреляцию LWLock с user time (0.96-0.98)
Все эксперименты показывают очень высокую корреляцию LWLock с system time (0.91-0.95)
Распределение CPU времени по экспериментам:
vfs_cache_pressure=50:
us (user time): 21-61% (среднее ~30%)
sy (system time): 5-10% (среднее ~7%)
wa (I/O wait): 17-31% (среднее ~27%)
id (idle): 12-42% (среднее ~35%)
vfs_cache_pressure=100:
us (user time): 25-57% (среднее ~35%)
sy (system time): 5-10% (среднее ~7%)
wa (I/O wait): 18-29% (среднее ~25%)
id (idle): 14-41% (среднее ~33%)
vfs_cache_pressure=150:
us (user time): 22-58% (среднее ~32%)
sy (system time): 5-10% (среднее ~7%)
wa (I/O wait): 16-28% (среднее ~24%)
id (idle): 13-41% (среднее ~34%)
Влияние vfs_cache_pressure:
User time: Наиболее высокий при pressure=100 (среднее 35%)
System time: Практически идентичен во всех случаях (~7%)
I/O wait: Наименьший при pressure=150 (среднее 24%)
Idle time: Наибольший при pressure=50 (среднее 35%)
Вывод: Увеличение pressure снижает I/O wait, но незначительно увеличивает user time, что указывает на более активную обработку данных приложением.
Общая картина:
Высокая корреляция переключений контекста с прерываниями (cs-in) во всех экспериментах (0.95-0.97)
При vfs_cache_pressure=150 появляется слабая/средняя корреляция cs-sy (0.0244)
Влияние управления кэшем на переключения контекста:
Механизм влияния:
1. vfs_cache_pressure=50:
Менее агрессивное управление кэшем
Меньше системных вызовов для управления памятью
Переключения контекста в основном вызваны прерываниями от дисковых операций
2. vfs_cache_pressure=100:
Сбалансированное управление кэшем
Умеренное количество системных вызовов для управления памятью
Прерывания остаются основной причиной переключений контекста
3. vfs_cache_pressure=150:
Агрессивное управление кэшем
Увеличение системных вызовов для управления памятью
Появление корреляции cs-sy указывает на рост времени ядра на управление памятью
Объяснение корреляции cs-sy при pressure=150:
Ядро тратит больше времени на:
Вытеснение страниц из кэша файловой системы
Управление списками страниц памяти
Обработку запросов на выделение/освобождение памяти
Это приводит к увеличению system time и связанных с ним переключений контекста
Статистика по экспериментам:
vfs_cache_pressure=50:
Проценты превышения ядер CPU: 7.27%
Максимальное значение procs_r: 10 процессов
Более стабильная очередь выполнения
vfs_cache_pressure=100:
Проценты превышения ядер CPU: 16.22%
Максимальное значение procs_r: 11 процессов
Наименее стабильная очередь выполнения
vfs_cache_pressure=150:
Проценты превышения ядер CPU: 14.55%
Максимальное значение procs_r: 11 процессов
Промежуточная стабильность
Анализ стабильности:
Наиболее стабильная очередь при pressure=50:
Наименьший процент превышения ядер CPU (7.27%)
Более равномерное распределение нагрузки
Меньше конкуренции за CPU ресурсы
Наименее стабильная очередь при pressure=100:
Наибольший процент превышения ядер CPU (16.22%)
Более выраженная конкуренция за CPU
Возможные задержки в обработке запросов
1. Оптимальный диапазон значений: vfs_cache_pressure = 90-110
Обоснование:
Компромисс между производительностью и стабильностью:
vfs_cache_pressure=50: лучшая стабильность очереди выполнения, но выше I/O wait
vfs_cache_pressure=150: ниже I/O wait, но выше нагрузка на ядро (system time)
vfs_cache_pressure=100: баланс между этими крайностями
2. Сопутствующие настройки для OLAP-нагрузки:
Настройки операционной системы:
vm.swappiness = 10 (уже установлено, оптимально для серверов)
vm.dirty_background_ratio = 5 (уменьшить с 10 для более частой фоновой записи)
vm.dirty_ratio = 20 (уменьшить с 30 для снижения латентности записи)
read_ahead_kb = 16384 (увеличить для последовательного чтения OLAP)
Настройки PostgreSQL для 8 CPU ядер:
max_parallel_workers_per_gather = 2-4 (увеличить с 1 для OLAP)
max_worker_processes = 16 (уже установлено, оптимально)
max_parallel_workers = 16 (уже установлено, оптимально)
work_mem = 64-128MB (увеличить с 32MB для сложных сортировок)
Проанализировать параметра vm.vfs_cache_pressure на производительность подсистемы IO для дискового устройства, используемого файловой системой /data.
Сводный отчета по нагрузочному тестированию подготовленный pg_pexpecto по окончании нагрузочного тестирования:
Метрики iostat для дискового устройства vdd
Корреляция скорость–IOPS: слабая (0,4128).
Корреляция скорость–MB/s: очень высокая (0,8191).
Тип нагрузки: аналитическая/ETL, так как наблюдается высокая зависимость от пропускной способности диска, а не от IOPS.
Ограничивающий фактор: пропускная способность диска (MB/s).
Дополнительные наблюдения:
Утилизация диска стабильно высокая (89–94%).
Задержки чтения/записи умеренные (9–14 мс).
Нагрузка на CPU в режиме ожидания I/O (wa) составляет 18–29%.
Корреляция скорость–IOPS: отрицательная (-0,2879).
Корреляция скорость–MB/s: очень высокая (0,8017).
Тип нагрузки: аналитическая/ETL с выраженной зависимостью от пропускной способности диска.
Ограничивающий фактор: пропускная способность диска (MB/s).
Дополнительные наблюдения:
Утилизация диска близка к максимальной (95–96%).
Задержки чтения растут со временем (до 16 мс).
Отрицательная корреляция с IOPS указывает на возможные проблемы с CPU, блокировками или памятью.
Нагрузка на CPU в режиме ожидания I/O (wa) достигает 31%.
Корреляция скорость–IOPS: слабая (0,5930).
Корреляция скорость–MB/s: очень высокая (0,9735).
Тип нагрузки: аналитическая/ETL с сильной зависимостью от пропускной способности диска.
Ограничивающий фактор: пропускная способность диска (MB/s).
Дополнительные наблюдения:
Утилизация диска стабильно высокая (89–95%).
Задержки чтения/записи низкие (6–11 мс).
Нагрузка на CPU в режиме ожидания I/O (wa) снижается к концу теста (до 16%).
1. Все три эксперимента показывают схожую картину:
Производительность ограничена пропускной способностью диска (MB/s), а не IOPS.
Нагрузка носит аналитический/ETL-характер (последовательное чтение/запись больших объёмов данных).
2. Влияние vm.vfs_cache_pressure:
Изменение параметра не оказало значительного влияния на тип нагрузки и ограничивающий фактор.
Наилучшие показатели задержек и утилизации CPU наблюдаются при значении 150.
3. Рекомендации:
Увеличить пропускную способность дисковой подсистемы .
Настроить параметры PostgreSQL для аналитических нагрузок (work_mem, maintenance_work_mem, effective_io_concurrency).
Рассмотреть использование партиционирования таблиц и параллельного выполнения запросов.
vm.vfs_cache_pressure = 50:
utilization: 95,1%
r_await: 13,8 мс
w_await: 6,6 мс
IOPS: 3 490
MB/s: 116,1
aqu_sz: 43,8
cpu_wa: 27,3%
vm.vfs_cache_pressure = 100:
utilization: 92,7%
r_await: 12,5 мс
w_await: 7,0 мс
IOPS: 3 513
MB/s: 129,6
aqu_sz: 40,5
cpu_wa: 25,4%
vm.vfs_cache_pressure = 150:
utilization: 92,7%
r_await: 9,8 мс
w_await: 7,3 мс
IOPS: 3 570
MB/s: 137,5
aqu_sz: 33,5
cpu_wa: 23,6%
Задержки и утилизация диска:
r_await последовательно снижается с ростом параметра: 13,8 мс (50) → 12,5 мс (100) → 9,8 мс (150)
w_await незначительно увеличивается: 6,6 мс (50) → 7,0 мс (100) → 7,3 мс (150)
Утилизация диска максимальна при значении 50 (95,1%), при 100 и 150 стабилизируется на уровне 92,7%
Наилучшие показатели задержек чтения достигаются при максимальном значении 150
Связь с пропускной способностью и IOPS:
Пропускная способность (MB/s) монотонно растёт: 116,1 (50) → 129,6 (100) → 137,5 (150)
IOPS также увеличивается: 3 490 (50) → 3 513 (100) → 3 570 (150)
Наблюдается чёткая тенденция: чем выше vfs_cache_pressure, тем выше производительность по пропускной способности
Поведение очереди запросов (aqu_sz):
Длина очереди последовательно уменьшается: 43,8 (50) → 40,5 (100) → 33,5 (150)
Это свидетельствует о более эффективной обработке запросов при высоких значениях параметра
Уменьшение очереди коррелирует со снижением времени ожидания CPU (cpu_wa)
Увеличение vfs_cache_pressure до 150 даёт наиболее сбалансированные результаты:
Наименьшие задержки чтения (9,8 мс против 13,8 мс при 50)
Наибольшая пропускная способность (137,5 MB/s против 116,1 при 50)
Самая короткая очередь запросов (33,5 против 43,8 при 50)
Наименьшая нагрузка на CPU в режиме ожидания (23,6% против 27,3% при 50)
Параметр vfs_cache_pressure оказывает существенное влияние на производительность дисковой подсистемы:
Более высокие значения способствуют более агрессивному освобождению кэша
Это снижает contention за память и уменьшает задержки
Однако может незначительно увеличить задержки записи
Для данной аналитической нагрузки оптимальным является значение 150, которое обеспечивает лучшую пропускную способность при меньших задержках и нагрузке на систему.
Проведённое комплексное исследование убедительно демонстрирует, что параметр ядра Linux vm.vfs_cache_pressure оказывает статистически значимое и многогранное влияние на производительность PostgreSQL при OLAP-нагрузке, имитирующей последовательное чтение больших объёмов данных.
Ключевые обобщённые выводы:
Тип нагрузки является определяющим: Во всех экспериментах система упиралась в пропускную способность диска (MB/s), а не в IOPS, что характерно для аналитических (OLAP) паттернов с последовательным доступом. Это главный ограничивающий фактор в данной конфигурации.
Влияние на кэширование и память:
Параметр практически не влияет на hit ratio внутреннего кэша PostgreSQL (shared buffers), что подтверждает их независимое управление.
Однако он существенно влияет на управление кэшем файловой системы (VFS cache) и подкачкой (swap). Более низкие значения (50) приводят к меньшей агрессивности вытеснения кэша, что вызывает более быстрый рост использования свопа и большее количество процессов, блокированных в состоянии ожидания ввода-вывода (D-состояние). Более высокие значения (150) заставляют ядро активнее освобождать кэш.
Влияние на производительность диска: Наблюдается чёткая тенденция: с ростом vfs_cache_pressure увеличивается пропускная способность (MB/s) и снижаются задержки чтения (r_await). Наилучшие показатели дисковых операций были достигнуты при значении 150.
Влияние на загрузку CPU и стабильность: Значение параметра также влияет на баланс загрузки процессора. Более высокие значения снижают время ожидания ввода-вывода (wa), но могут незначительно повысить системное время (sy) из-за активного управления памятью и привести к менее стабильной очереди выполнения процессов (run queue).
Недостатки тестовой конфигурации: Исследование выявило системные проблемы, общие для всех тестов:
Критически низкий hit ratio shared buffers (55-58%), указывающий на недостаточный объём оперативной памяти для данной рабочей нагрузки.
Постоянно высокий уровень ожидания ввода-вывода (wa > 10%), подтверждающий, что диск является узким местом.
Общие рекомендации для OLAP-нагрузок на PostgreSQL:
Аппаратные улучшения (более быстрые NVMe SSD, увеличение RAM) имеют высший приоритет для снятия выявленных ограничений.
Оптимизация ОС: Уменьшение vm.dirty_* соотношений для снижения латентности записи и увеличение read_ahead_kb для ускорения последовательного чтения.
Оптимизация PostgreSQL: Увеличение shared_buffers, work_mem, effective_cache_size и настройка параметров параллельного выполнения.
В исследовании содержится кажущееся противоречие: в Части 2 оптимальным названо значение 100, а в Части 3 — 150. Причина этих разных рекомендаций заключается не в ошибке, а в разном фокусе анализа и приоритетах, которые они отражают. Это наглядная иллюстрация того, что процесс оптимизации — это всегда выбор компромиссного решения из набора альтернатив.
Рекомендация из Части 2: vm.vfs_cache_pressure = 100
Фокус анализа: Общая стабильность системы, поведение процессов, управление памятью и свопом.
Ключевые аргументы:
Стабильность процессов: Отсутствие аномального роста процессов в состоянии D (блокировка).
Управление памятью: Наиболее стабильное и предсказуемое использование свопа (наименьший рост).
Сбалансированность: Умеренные корреляции между метриками, отсутствие экстремальных паттернов.
Компромисс: Оптимальный баланс между удержанием данных в кэше и их своевременным освобождением.
Приоритет: Надёжность и предсказуемость долгосрочной работы системы.
Рекомендация из Части 3: vm.vfs_cache_pressure = 150
Фокус анализа: Максимальная производительность дисковой подсистемы, задержки и пропускная способность.
Ключевые аргументы:
Производительность диска: Наивысшая пропускная способность (137.5 MB/s) и наименьшие задержки чтения (9.8 мс).
Эффективность очереди: Самая короткая очередь запросов к диску, что указывает на более эффективную обработку.
Разгрузка CPU: Наименьшая нагрузка процессора в режиме ожидания I/O (wa).
Механизм: Агрессивное освобождение кэша снижает конкуренцию (contention) за оперативную память.
Приоритет: Максимальная скорость обработки данных и минимизация времени выполнения задач.
Заключительный вывод по выбору значения
Обе рекомендации верны в своих контекстах. Выбор между 100 и 150 — это классический инженерный компромисс между «быстро» и «стабильно».
Для продакшен-среды, где критически важны предсказуемость, стабильность и отсутствие аномалий (внезапные блокировки процессов), следует придерживаться рекомендации vm.vfs_cache_pressure = 100 (или диапазон 90-110).
Для выделенных ETL-задач или пакетной аналитической обработки, где ключевая цель — минимизировать время выполнения и диск является подтверждённым узким местом, можно обоснованно применить значение vm.vfs_cache_pressure = 150 для получения максимальной пропускной способности, отдавая себе отчёт в потенциально возросшей нагрузке на подсистему памяти ядра.
Таким образом, исследование не даёт единственно верного ответа, а предоставляет администратору обоснованный выбор в зависимости от конкретных бизнес-требований и приоритетов, подчёркивая, что эффективная оптимизация — это всегда поиск баланса между конфликтующими целями системы.
Раньше я использовал Windows 11 25H2, и в целом система нормальная. Но со временем я решил попробовать Linux, и вот почему.
Во‑первых, в Windows многое скрыто и сложно менять. Иногда кажется, что система сама решает, что и когда делать. В Linux я могу полностью контролировать настройки и процессы.
Во‑вторых, обновления в Windows часто приходят в самый неподходящий момент — и приходится ждать или прерывать работу. В Linux я сам выбираю, когда обновлять систему, и это гораздо удобнее.
В-третьих, Windows в последнее время стала слишком прожорливой и требовательной к железу, в отличие от Linux-дистрибутивов, которые обычно работают легче и быстрее на том же компьютере.
В-четвёртых, Linux имеет обширное сообщество, которое реально помогает и отвечает на вопросы лучше, чем официальные «сотрудники Windows». Если что-то непонятно — всегда найдётся кто-то, кто подскажет или даст готовое решение.
В-пятых, большинство Linux-дистрибутивов (кроме Ubuntu) бесплатны, не имеют лишних «шпионских» модулей или ненужных компонентов, а также лишён Legacy-кода, который в Windows иногда создаёт уязвимости.
В-шестых, в Linux меньше создаётся вредоносного ПО, чем в Windows, поэтому система остаётся более безопасной без лишнего антивирусного софта.
В-седьмых, если вы хотите попробовать Linux, но не хотите удалять Windows, есть официальная прослойка WSL, доступная в Microsoft Store. Она позволяет запускать Linux прямо в Windows. Это не плюс или минус — просто вариант попробовать систему.
И наконец, Linux даёт больше прозрачности: можно реально увидеть, что делает компьютер, какие процессы запущены, как работает память и диски.
Для меня это оказалось интереснее и полезнее для понимания работы компьютера. Windows всё ещё хороша, но Linux лучше подходит, если хочешь сам контролировать систему и учиться.
Кстати, я сейчас использую Linux Mint, но когда впервые переходил — пробовал Ubuntu.
Слетела винда, 10, решив обновится после многих лет бездействия.
Пришлось поставить Линукс.
Пока мучаюсь с калибровкой тачскрина, но видимо придется без него обойтись. Да и в принципе не использовал его почти.
ну и неработает регулировка яркости экрана
А так, пока вроде не плохо живётся без винды.
Хотя, рассмотрел бы что-то полегче дебиана, но с таким же большим набором приложений в репах.(Не знаю есть ли такие дистрибутивы, тк только встал на дорогу Линукса)
Это рабочий стол такой, с корзиной, скринами и папками
Я помогал одному парню делать задание и делал скриншоты в Ubuntu. Но потом по какой-то причине один из скриншотов стал рабочим столом! Как это исправить? У меня нелицензионная windows 10, если решение в том, что надо сделать её лицензионной, то напишите, как а то у меня не получается (мне самому стыдно).
Ещё мне хотелось бы узнать, как это произошло? Я эти скриншоты разве что в word ljrevtyn вставлял и deepseek, чтобы логи проверить.
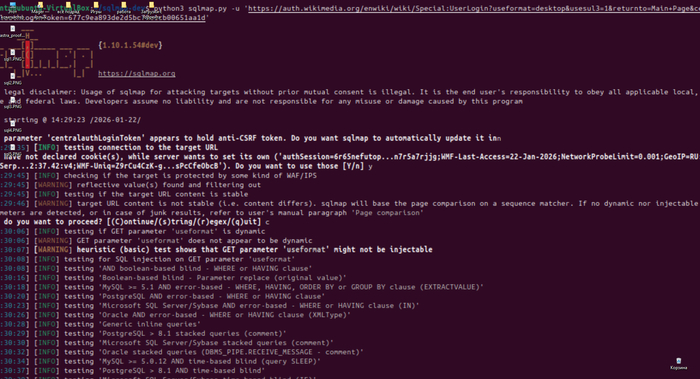
Всех приветствую дорогие друзья. С вами на связи Гридин Семён. Поработал сегодня с двумя сущностями Codesys 3.5 и SCADA SimpLight 5.
О чем вкратце изложу опыт работы в очередной последовательности.

Все вопросы можете задать в тг-канале "Ты же инженер АСУ ТП".
Будем считать, что у вас всё установлено. По установкам ПО можно найти документацию и мануалы.
Суть следующая - нам нужно сделать ПЛК с Modbus TCP Slave. В моем случае ПЛК200 использует оба порта Ethernet. 1 опрашивает модуль - является мастером. 2 порт работает в режиме Slave.
Для того чтобы работал 2 порт в режиме LAN нужто зайти в его веб-настройки и отконфигурировать.
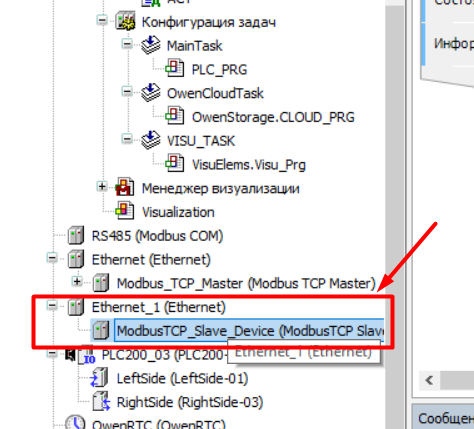
Дальше добавляем модуль Ethernet.
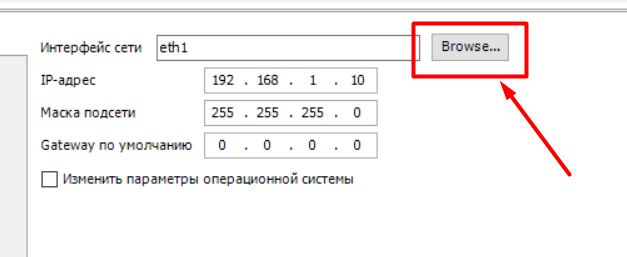
Нужно связаться с ПЛК и выбрать по какому порту ему отдавать.
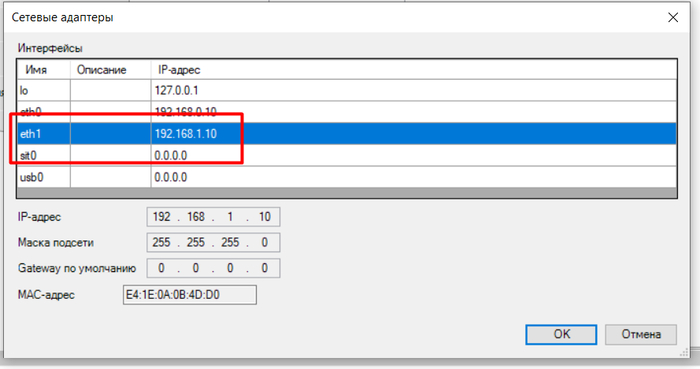
Выбираем преднастроенный порт.
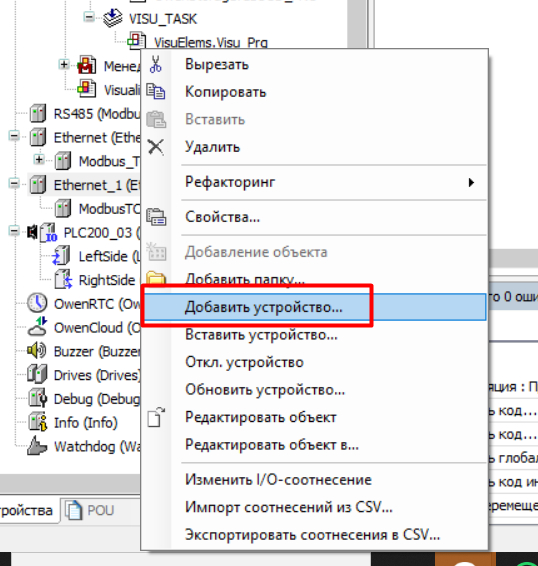
Добавляем устройство.
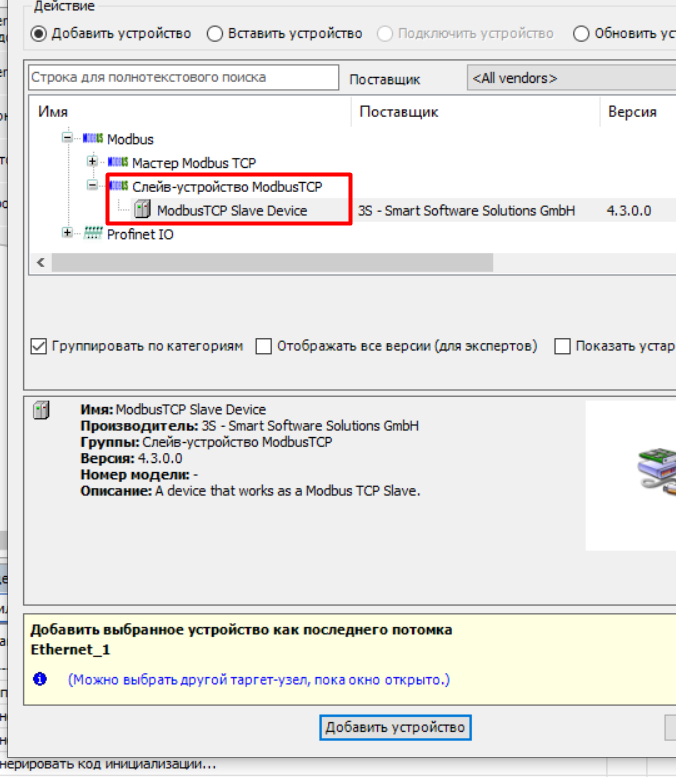
Выбираем TCP Slave.
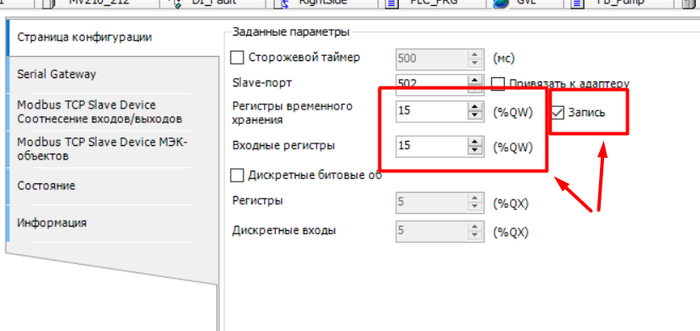
Далее залезаем в его настройки, вводим количество регистром и ставим галочку на запись, если нужно read\write.
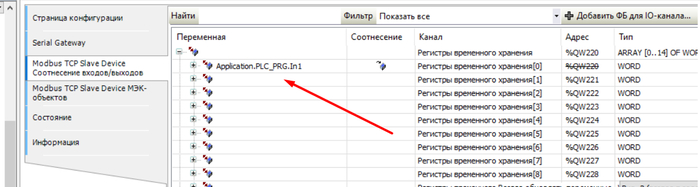
Во вкладке соотнесение входов выходов вносим переменную. Переходим на следующий этап.
Далее работаем со SCADA. Будем считать, что она скачана, установлена и запущена Среда разработки.
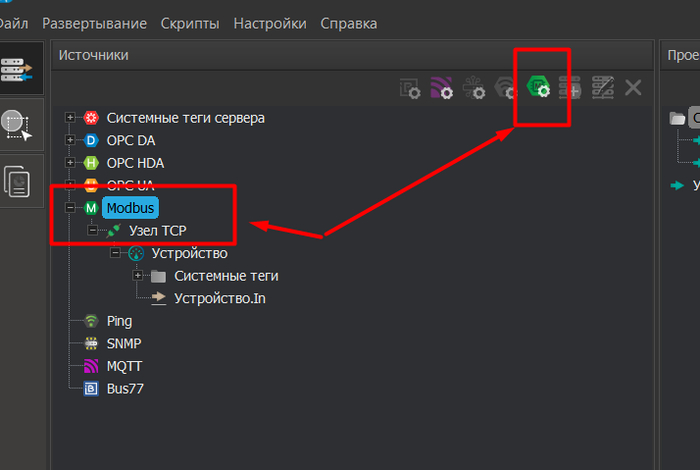
Список различных драйверов. Выбираем напрямую Modbus Драйвер, заходим в настройки.
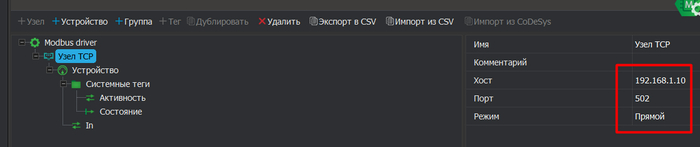
Настраиваем Узел. В моем случае IP 192.168.1.10.
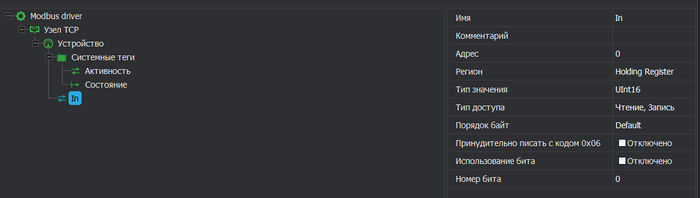
Вносим тег. У ПЛК 200 в режиме TCP Slave адресация начинается с 0.
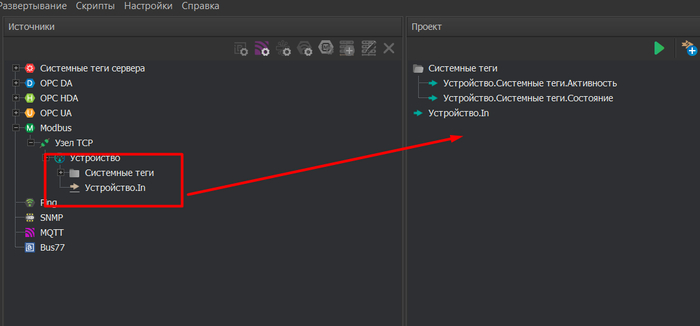
Перетаскиваем теги в Проект.
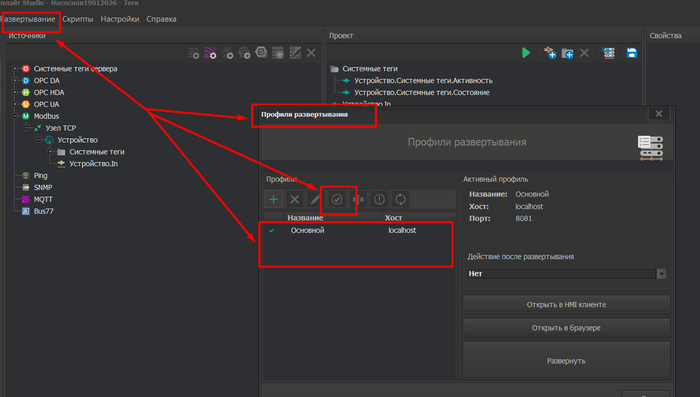
Прежде чем запускать сервак. Нужно для него создать профиль и нажать птичку, что именно этот сервер мы используем.
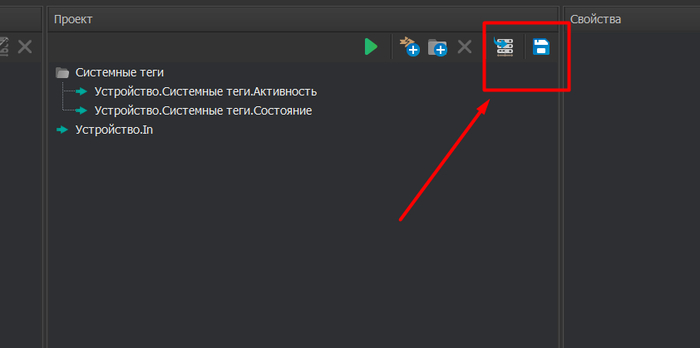
После этого сохраняем проект и запускаем сервер.
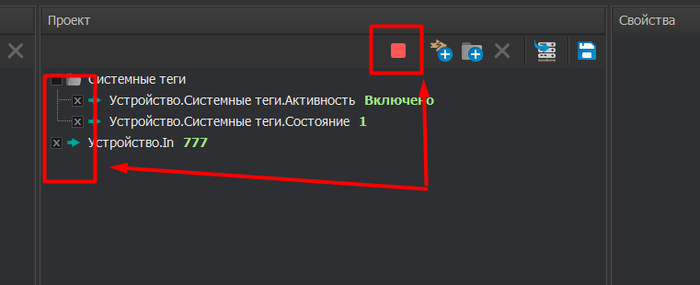
Ставим маленькие галочки - чего опрашивать, зеленую стрелочку Пуск. И наблюдаем ТРИ топора, и что вообще чё то включено.
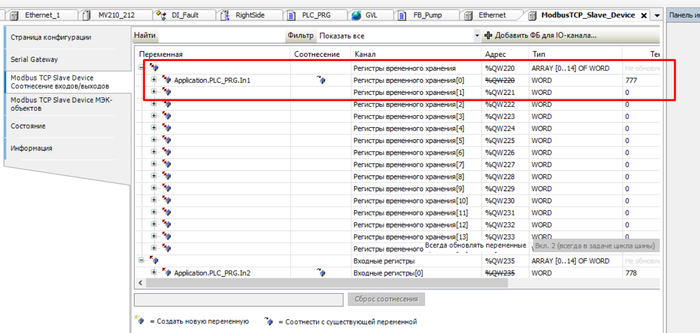
В программе благополучно отдаём ТРИ топора.
На этом всё друзья. Пишите в чатах..








