Анализ сопротивления внедрению системы 5С на ремонтном производстве через призму шести слоев сопротивления
Пост написан под влиянием обсуждения, которое началось здесь https://t.me/leanrussia/3702/21190 и продлилось несколько дней.
Методика шести слоев сопротивления https://habr.com/ru/articles/725018/
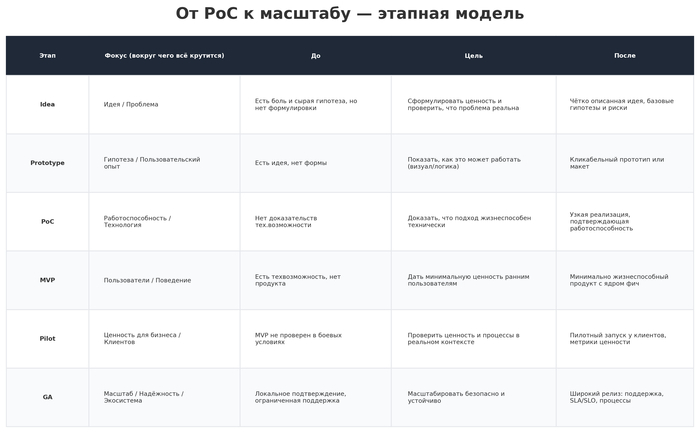
Подход к анализу сопротивления изменениям через шесть слоев позволяет систематизировать возражения и разработать целенаправленную стратегию их преодоления. Эта методика направлена на синхронизацию по трем ключевым вопросам изменений: что изменить, на что изменить и как обеспечить перемены.
Методика шести слоев сопротивления позволяет систематизировать работу с возражениями и разработать комплексную стратегию внедрения. Ключевой принцип – не бороться с сопротивлением, а понимать его причины и находить компромиссные решения, которые учитывают потребности производства.
Введение в 5С
Система 5С (сортировка, порядок, чистота, стандартизация, совершенствование) является фундаментом бережливого производства и доказала свою эффективность на множестве предприятий. Однако при внедрении в ремонтное производство руководители и специалисты часто сталкиваются с сильным сопротивлением со стороны персонала. Особенности ремонтного цеха – непредсказуемость заказов, разнообразие деталей, срочные заявки и отсутствие жесткого плана – создают уникальные вызовы для внедрения дисциплины рабочего места. Это порождает особое восприятие изменений и формирует специфические аргументы против внедрения 5С. Для эффективной работы с сопротивлением необходимо понимать его природу и структуру.
Анализ сопротивления внедрению 5С в ремонтном производстве по слоям
Первый слой: "У нас проблема не в беспорядке, а в отсутствии планирования"
Классическое возражение в ремонтном производстве: "Мы не можем внедрять 5С, потому что у нас нет плана производства, все работает по ситуации". Это указывает на фундаментальное несогласие в определении проблемы. Руководитель видит проблему в хаосе на рабочих местах, а сотрудники считают корневой проблемой отсутствие предсказуемости заказов.
Как показывает практика обсуждений, ремонтные цеха часто работают в условиях постоянных срочных заявок, когда "под конец рабочего дня к тебе залетает какое-нибудь колесо зубчатое, которое нужно сделать срочно". Сотрудники считают, что в таких условиях невозможно предсказать, какие инструменты понадобятся, и поэтому вынуждены держать все возможное под рукой.
Преодоление этого слоя требует признания проблемы с обеих сторон. Необходимо объяснить, что 5С – это не система для планирования производства, а метод организации рабочего места в условиях любой непредсказуемости. Беспорядок не решает проблему непредсказуемости, а усугубляет ее, создавая дополнительные простои из-за поиска инструментов и материалов.
Второй слой: "5С – это для основного производства, а не для ремонта"
Даже при согласии в том, что в цехе есть проблемы с организацией работы, сотрудники могут сомневаться в применимости именно системы 5С. Они могут предлагать альтернативные решения: увеличение количества инструментов на каждом рабочем месте, создание дополнительных кладовых или просто нанять больше кладовщиков.
Аргумент "в основном производстве 5С работает, а в ремонтном – нет" отражает глубокое убеждение в принципиальной разнице между типами производства. Сотрудники считают, что особенности ремонтного цеха требуют совершенно другого подхода.
Для преодоления этого слоя важно показать, что принципы 5С универсальны и могут быть адаптированы под любые условия. Например, в условиях непредсказуемости особенно важна сортировка инструментов на категории "нужные всегда", "нужные иногда" и "ненужные", что позволяет быстро находить необходимое независимо от типа работы.
Третий слой: "Это увеличит наше время, а не сократит"
Ключевая опасность третьего слоя – сомнения в эффективности решения. Типичное возражение: "Токарь должен бегать в кладовку за разными резцами и мерилками? Это же увеличит время изготовления детали!" Сотрудники не видят выгоды в том, чтобы организовывать инструменты по принципу 5С, если это потребует дополнительных перемещений.
Этот слой особенно сложен, потому что реальная выгода от 5С проявляется не сразу и не всегда очевидна для一线-персонала. Сотрудники фокусируются на видимых издержках (время на переходы до склада) и не учитывают скрытые потери (время поиска инструментов в беспорядке, простои из-за отсутствия нужного инструмента).
Для преодоления этого слоя необходимо четко продемонстрировать ROI изменений. Например, показать, что время поиска ключа на 13 в общей тумбочке составляет в среднем 5 минут, тогда как переход до правильно организованного склада займет 2 минуты, но инструмент будет всегда на месте.
Четвертый слой: "Кладовщик уйдет, и все работы встанут"
Опасения четвертого слоя часто связаны с реальными проблемами организации производства. Если в цехе сложилась система, где "кладовая закрывается, кладовщик домой пошел, контроль провел входной контроль, ну и вперед работаем", то предложение организовать централизованный склад вызывает законные опасения по поводу остановки работ в конце смены.
Сотрудники справедливо указывают на то, что в условиях срочных ремонтов отсутствие доступа к инструментам может привести к критическим простоям оборудования. Это не надуманная проблема, а реальный риск, который необходимо учитывать при проектировании системы.
Преодоление этого слоя требует комплексного подхода: возможно, создание мини-складов на участках с круглосуточным доступом, организация дежурств или внедрение системы самообслуживания с четкими правилами пополнения запасов.
Пятый слой: "У нас нет места/людей/ресурсов для этого"
Практические препятствия пятого слоя особенно актуальны для ремонтных цехов, которые часто расположены в старых помещениях с ограниченной площадью. Организация зон хранения по принципу 5С требует дополнительного пространства, ответственных лиц и времени на обучение персонала.
Сотрудники могут указывать на то, что "у нас в одной группе 10 токарей, в другой 5, плюс еще есть 5 фрезеровщиков, 4 шлифовщика" и предсказывать хаос в инструментально-раздаточной при централизации инструментов.
Эти опасения требуют практического решения: возможно, поэтапное внедрение, начиная с одного участка, или адаптация стандартов 5С под существующие ограничения. Например, вместо полной централизации можно создать систему "личных" и "общих" инструментов с четкими правилами использования.
Шестой слой: "Да, конечно, мы все сделаем" (но ничего не делают)
Самый опасный слой – формальное согласие без реальных действий. После длительных обсуждений сотрудники могут согласиться с необходимостью изменений, но продолжать работать по старому. Это происходит по нескольким причинам:
Отсутствие личной заинтересованности – система мотивации не поощряет поддержание порядка
Привычка – "у нас всегда так работали, и все нормально"
Недоверие к руководству – опыт показывает, что инициативы быстро забываются
Конфликт интересов – поддержание порядка требует дополнительных усилий без немедленной отдачи
Преодоление этого слоя требует системных изменений: включение показателей 5С в систему KPI, создание культуры постоянного совершенствования, признание и поощрение лучших практик.
Практические рекомендации по преодолению сопротивления
Адаптация 5С под специфику ремонтного производства
Система 5С должна быть гибкой и адаптированной под особенности ремонтного цеха:
Сортировка – не удаляйте "редко используемые" инструменты, а создайте для них отдельные зоны с пометкой частоты использования
Порядок – разработайте гибкие стандарты размещения, учитывающие разнообразие работ
Чистота – установите минимальные стандарты поддержания чистоты, применимые в условиях срочных ремонтов
Стандартизация – создайте простые, понятные визуальные стандарты, а не сложные документы
Совершенствование – учитывайте предложения一线-персонала по улучшению системы
Работа с ключевыми возражениями
"Нам нужен инструмент под рукой из-за непредсказуемости": Объясните разницу между "под рукой" и "в беспорядке". Организованный доступ к инструментам даже на складе быстрее, чем поиск в хаотично заполненной тумбочке. Введите систему "срочных" инструментов, которые всегда доступны на участке.
"Кладовщик уходит, и работа останавливается": Создайте систему самообслуживания с четкими правилами: ответственные за участки могут брать инструменты после рабочего дня по упрощенной процедуре с последующей отчетностью.
"Это для основного производства, а не для нас": Покажите примеры успешного внедрения 5С в ремонтных цехах. Подчеркните, что именно в условиях непредсказуемости организованная система поиска инструментов дает наибольший эффект.
Поэтапное внедрение
Начните с согласования проблемы: Проведите диагностику потерь времени на поиск инструментов и материалов. Покажите сотрудникам реальные цифры.
Выберите пилотный участок: Начните с одного токарного или слесарного участка, где есть заинтересованный мастер.
Создайте простые стандарты: Разработайте минимально необходимые правила, которые легко запомнить и выполнять.
Обеспечьте поддержку: Назначьте координатора внедрения, который будет помогать преодолевать возникающие сложности.
Демонстрируйте результаты: Регулярно показывайте улучшения в сокращении времени простоев, повышении безопасности и комфорта работы.
Заключение
Сопротивление внедрению 5С в ремонтном производстве – естественная и ожидаемая реакция. Оно не говорит о некомпетентности сотрудников или бесполезности самой системы. Сопротивление – это сигнал о том, что изменения не были должным образом проработаны и адаптированы под специфику производства.