
0 просмотренных постов скрыто



Язык Go: минимум знаний для вайбкодинга
В предыдущей статье мы разобрали C++ — мощный, но сложный инструмент, требующий понимания множества концепций от RAII до шаблонов. Сегодня поговорим о языке, рождённом из усталости от этой сложности.
Go создавался инженерами Google, которые устали ждать по полчаса компиляции C++-кода и разбираться в десяти способах сделать одно и то же. Для вайбкодинга Go представляет особый интерес: его намеренная простота и единообразие означают, что LLM реже «галлюцинирует» экзотические конструкции, а сгенерированный код легче проверить и понять даже без глубокой экспертизы.
В середине двухтысячных годов в калифорнийском Маунтин-Вью, в кампусе компании Google, назревало нечто похожее на тихий переворот — не политический и не корпоративный, а инструментальный, связанный с орудиями труда, которыми пользовались инженеры. Компания к тому времени превратилась в вычислительного левиафана: сотни миллионов поисковых запросов ежедневно перетекали через её серверы, значительная доля текстового содержимого всего интернета подвергалась индексации, а сервисы требовали такой координации вычислительных мощностей, какой человечество прежде не предпринимало. Программное обеспечение, приводившее в движение эту махину, писалось преимущественно на языке C++ — инструменте мощном, зрелом, позволявшем извлекать из аппаратуры предельную производительность. Однако та самая мощь и зрелость постепенно превращались в источник специфического страдания, знакомого каждому, кто имел дело с инструментом, переросшим границы своего первоначального замысла и обросшим напластованиями десятилетий.
История C++ восходит к началу восьмидесятых годов, когда датский программист Бьёрн Страуструп задумал расширить язык C средствами, облегчающими организацию крупных программных проектов. C, созданный десятилетием раньше Деннисом Ритчи и Кеном Томпсоном для написания операционной системы Unix, отличался спартанской лаконичностью: минимум концепций, максимум контроля над машиной, никаких излишеств. Страуструп добавил к этой аскетической основе классы, наследование, позднее — шаблоны и множество других конструкций, каждая из которых отвечала на реальную потребность какой-либо группы разработчиков. Язык развивался органически, почти демократически: если достаточное число голосов требовало новой возможности, возможность в конечном счёте появлялась. За три десятилетия такой эволюции C++ стал напоминать не столько спроектированный инструмент, сколько геологическое образование — слой поверх слоя, эпоха поверх эпохи, причём каждый слой оставался доступным, потому что убрать что-либо означало бы обрушить код, написанный в расчёте на его присутствие. Справочник по современному C++ производит впечатление музея, выросшего из частной коллекции: экспонаты бесспорно ценны, но их столько и они столь разнородны, что посетителю требуется путеводитель к путеводителю, чтобы не заблудиться между залами.
Практические последствия этой археологической сложности в масштабах Google проступали в двух измерениях с особенной остротой. Первое касалось времени компиляции. Компиляция — процедура перевода программы с языка, понятного человеку, на язык, понятный машине. Компьютер не постигает человеческих наречий, даже таких формализованных, как языки программирования; он оперирует исключительно последовательностями элементарных операций, закодированных в виде чисел: переместить содержимое одной ячейки памяти в другую, сложить два числа, сравнить результат с третьим и в зависимости от исхода перескочить к иному месту программы. Компилятор выступает переводчиком, превращающим относительно членораздельный текст программы в эту машинную скоропись. Для C++ перевод требовал колоссальных усилий: язык изобиловал конструкциями, допускавшими многообразные интерпретации, и компилятору приходилось проделывать обширную аналитическую работу, прежде чем породить исполняемый код. Инженер, внёсший скромное исправление в проект, мог затем наблюдать, как минуты складываются в десятки минут ожидания, пока компилятор переварит результат. Полчаса — достаточный срок, чтобы мысль успела остыть, контекст задачи выветрился из оперативной памяти головы, а сам инженер переключился на постороннее и потом с ощутимым трением возвращался к прерванному занятию.
Второе измерение затрагивало когнитивную нагрузку — то умственное усилие, которое программист тратит не на решение собственно задачи, а на навигацию по лабиринту возможностей, предоставляемых инструментом. C++ предлагал несколько способов достичь почти любой цели, и каждый способ нёс собственный багаж достоинств, недостатков и неочевидных подводных камней. Выбор между ними требовал экспертизы, которая накапливалась годами практики, и даже признанные эксперты нередко расходились во мнениях о предпочтительном подходе в той или иной ситуации. Код, написанный одним мастером, мог оказаться загадкой для другого — не потому, что был дурно написан, а потому, что пользовался иным диалектом того же языка, иным набором идиом из необъятного арсенала допустимых приёмов. Когда над проектом трудятся тысячи инженеров, когда код живёт десятилетиями и его читают несравненно чаще, чем пишут, такая вариативность из достоинства превращается в помеху, в источник трения и недоразумений.
Три инженера, которые в 2007 году начали размышлять о том, каким мог бы выглядеть язык, свободный от этих напластований, принадлежали к редкой породе людей, умеющих не только пользоваться инструментами, но и создавать их. Кен Томпсон обладал биографией, придававшей его суждениям об устройстве языков программирования вес исторического прецедента: в начале семидесятых он вместе с Деннисом Ритчи создал операционную систему Unix и язык C — два изобретения, определившие траекторию развития вычислительной техники на полстолетия вперёд. C был радикально прост для своего времени: он давал программисту прямой доступ к памяти и периферии, но делал это посредством минимального набора концепций, который можно было удержать в голове целиком, не прибегая к справочникам на каждом шагу. Эта простота являлась не признаком ограниченности, а плодом дисциплины — и она оказалась поразительно продуктивной, породив экосистему программного обеспечения, на которой до сих пор держится изрядная часть цифровой инфраструктуры мира. Роб Пайк работал над Plan 9 — экспериментальной операционной системой, пытавшейся переосмыслить архитектуру Unix для эры повсеместных сетей, — и вынес из этого опыта острое понимание того, как программные компоненты могут сообщаться друг с другом в распределённой среде, не превращая систему в клубок взаимозависимостей. Роберт Гризмер привнёс опыт создания виртуальных машин и компиляторов — техническое знание того, как воплотить язык не только выразительный, но и быстрый в трансляции и исполнении.
Язык, который они начали проектировать и который получил короткое имя Go, строился на принципе, который можно было бы назвать программируемой сдержанностью. Там, где C++ щедро предлагал десять путей к одной цели, Go предлагал один — тот, который создатели сочли достаточно хорошим для большинства случаев и достаточно очевидным, чтобы не требовать долгих раздумий. Там, где другие языки наращивали арсенал возможностей в ответ на каждую артикулированную потребность, Go сознательно воздерживался от добавлений, грозивших усложнить язык сверх определённого порога. Решение кажется контринтуитивным: разве обширный выбор — не благо? Разве инструмент, способный на десять действий, не превосходит инструмент, способный лишь на пять? Ответ зависит от того, что именно оптимизируется. Если оптимизировать удобство написания отдельной программы отдельным программистом здесь и сейчас, то изобилие возможностей действительно предпочтительнее. Но если оптимизировать читаемость кода, который будут поддерживать сотни разных людей на протяжении десятилетия, — тогда единообразие перевешивает гибкость, а предсказуемость ценнее виртуозной выразительности.
Аналогия с естественным языком помогает прояснить эту логику. Русский язык — как, впрочем, любой живой язык — мог бы теоретически обогащаться новыми грамматическими конструкциями, позволяющими выражать некоторые мысли компактнее или точнее. Но ценность общего языка коренится именно в его устойчивости: носители владеют одним и тем же сводом правил и потому способны понимать друг друга без предварительных переговоров о том, какой версией грамматики пользоваться сегодня. Язык, который непрерывно усложняется, рискует расслоиться на диалекты и в конечном счёте утратить свою коммуникативную функцию — перестать быть средством взаимопонимания и сделаться барьером. Языки программирования сталкиваются с аналогичной дилеммой: гибкость для индивидуального автора против связности профессионального сообщества в целом. Go сделал выбор в пользу связности.
Программа на Go существует как текстовый файл — или совокупность файлов — содержащий инструкции, записанные по правилам, которые определяет язык. Файлы группируются в единицы, называемые пакетами: пакет объединяет логически родственный код и может использоваться другими частями программы как готовый строительный блок. Один особый пакет носит имя main и служит точкой входа: при запуске программы выполнение начинается с функции main внутри этого пакета. Функция — именованный фрагмент кода, выполняющий определённую задачу; её можно вызывать из разных мест программы, избегая повторения одних и тех же инструкций.
Чтобы текст программы превратился в нечто, способное действовать, его обрабатывает компилятор Go. Результатом становится бинарный файл — цепочка машинных команд, готовая к непосредственному исполнению процессором без дополнительных посредников. Существенная особенность Go состоит в самодостаточности этого файла: он вмещает всё необходимое для работы и не требует установки вспомогательных библиотек или виртуальных машин на компьютере, где будет запущен. Программу, скомпилированную на одной машине, можно перенести на другую машину той же архитектуры и запустить немедленно, без ритуалов подготовки. Эта портативность приобрела особую ценность в эпоху облачных вычислений, где программы нередко исполняются в аскетичных средах, очищенных от всего постороннего ради экономии ресурсов и безопасности.
Синтаксис Go спроектирован с прицелом на лаконичность, граничащую со скупостью. Небольшой пример — программа, складывающая числа в списке и выводящая результат, — позволяет ощутить эту эстетику:
```go
package main
import "fmt"
func main() {
nums := []int{1, 2, 3, 4}
sum := 0
for _, n := range nums {
sum += n
}
fmt.Println("Sum:", sum)
}
```
Первая строка объявляет принадлежность файла к пакету main — тому самому, с которого начинается жизнь программы. Вторая строка импортирует пакет fmt, предоставляющий функции для форматированного вывода; название — сокращение от слова format. Третья строка открывает определение функции main, служащей точкой входа.
Внутри функции первая инструкция создаёт переменную nums и присваивает ей срез целых чисел со значениями 1, 2, 3, 4. Срез — структура данных, представляющая последовательность элементов одного типа; int указывает, что элементы являются целыми числами. Оператор := совмещает две операции: объявляет новую переменную и присваивает ей значение, причём тип переменной выводится автоматически из того, что ей присваивается. Компилятор сам догадывается, что nums должна быть срезом целых чисел, потому что именно такой срез стоит справа от знака присваивания. Этот механизм называется выводом типов и позволяет писать компактный код, сохраняя при этом строгую типизацию.
Следующая строка создаёт переменную sum с начальным значением ноль — в ней будет накапливаться сумма. Затем начинается цикл: конструкция for с ключевым словом range означает перебор всех элементов коллекции. Запись `_, n := range nums` расшифровывается так: для каждого элемента среза nums присвоить этот элемент переменной n и выполнить тело цикла. Символ подчёркивания занимает место, предназначенное для индекса элемента, — range возвращает и индекс, и значение, но индекс здесь не нужен, и Go требует явно показать, что мы его игнорируем, а не забыли по недосмотру. Внутри цикла инструкция `sum += n` прибавляет текущее число к накопленной сумме. Последняя строка вызывает функцию Println из пакета fmt, которая выводит свои аргументы — строку «Sum:» и значение переменной sum — и переходит на новую строку.
Даже читатель, никогда прежде не заглядывавший в программный код, может заметить своеобразную прозрачность этого текста. Здесь нет многословных деклараций, которыми славятся иные языки; нет обилия специальных символов с неочевидным смыслом; нет нагромождения абстракций, заслоняющих суть происходящего. Программа совершает ровно то, что написано, и написано почти так, как могло бы быть произнесено вслух, — разумеется, с поправкой на формальный синтаксис.
Go принадлежит к семейству статически типизированных языков: тип каждой переменной известен уже на этапе компиляции и не может измениться во время исполнения. Переменная, объявленная как вместилище целого числа, не способна внезапно начать хранить текстовую строку или дату. Компилятор проверяет согласованность типов и отказывается создавать программу, если обнаруживает нестыковку — скажем, попытку сложить число с текстом или передать функции аргумент неподходящего сорта. Подобная строгость воспринимается иногда как докучливое ограничение, но на практике она перехватывает множество ошибок прежде, чем программа будет запущена, превращая компилятор в первую линию обороны против определённых классов недоразумений. Вывод типов смягчает эту строгость с точки зрения удобства записи: программисту не приходится педантично указывать тип каждой переменной, поскольку компилятор способен вычислить его из контекста.
Одна из ключевых инноваций Go связана с понятием конкурентного выполнения — способностью программы заниматься несколькими делами одновременно или, точнее, создавать убедительную иллюзию одновременности. Современные программы почти никогда не являются линейными цепочками действий, терпеливо ожидающими завершения каждого шага перед переходом к следующему. Веб-сервер обрабатывает запросы от множества пользователей параллельно; браузер одновременно загружает изображения, исполняет скрипты и реагирует на щелчки мыши; программа для монтажа видео декодирует кадры, накладывает эффекты и отображает результат на экране, оставаясь при этом отзывчивой к командам пользователя. Конкурентность — способ организации программы так, чтобы эти множественные активности сосуществовали, не блокируя друг друга и не превращая систему в очередь из ожидающих.
Традиционный подход к конкурентности опирается на потоки выполнения — независимые последовательности инструкций, которыми управляет операционная система. Создание потока сопряжено с выделением памяти и регистрацией в планировщике операционной системы; переключение между потоками требует сохранения и восстановления состояния, что тоже отнимает ресурсы. Накладные расходы достаточно ощутимы, чтобы программы обычно ограничивались умеренным числом потоков — десятками, сотнями, в напряжённых случаях тысячами — и тщательно распределяли работу между ними, словно драгоценный ресурс.
Go предлагает иную модель посредством горутин — легковесных единиц конкурентного выполнения, которыми распоряжается не операционная система, а собственная среда исполнения языка. Порождение горутины обходится несопоставимо дешевле, чем порождение потока: программа способна создавать сотни тысяч, а при необходимости и миллионы горутин без катастрофического роста накладных расходов. Это меняет саму парадигму проектирования: вместо того чтобы экономно делить скудный запас потоков между задачами, программист волен выделить каждой самостоятельной задаче собственную горутину и доверить среде исполнения заботу о планировании и распределении процессорного времени.
Конкурентное выполнение, однако, порождает проблему координации: когда несколько горутин работают бок о бок, как им обмениваться сведениями, не создавая хаоса? Вообразите двух поваров, одновременно тянущихся к одной кастрюле, чтобы добавить каждый свой ингредиент, — исход непредсказуем и потенциально плачевен. Классическое решение использует механизмы блокировки, позволяющие лишь одному участнику в каждый момент времени обращаться к разделяемому ресурсу, но корректное применение блокировок требует немалого искусства и остаётся благодатной почвой для трудноуловимых ошибок, проявляющихся лишь при редком стечении обстоятельств.
Go поощряет альтернативный подход через механизм каналов — выделенных путей передачи сообщений между горутинами. Канал можно уподобить трубе строго определённого диаметра: одна горутина опускает значение в один конец, другая горутина извлекает его из противоположного конца. Пока значение движется по каналу, оно не принадлежит ни отправителю, ни получателю; сам акт передачи гарантирует, что в каждый момент времени данными владеет ровно один участник. Эта модель — передача сообщений вместо разделяемой памяти — делает координацию явной и зримой: программист не полагается на неявные допущения о том, что разные части программы не столкнутся при доступе к общим данным, а прямо определяет, какая информация, когда и от кого к кому перетекает.
Образ фабричного конвейера помогает закрепить интуицию. Представьте производственную линию, где каждый рабочий выполняет одну операцию и передаёт изделие дальше. Между соседними постами установлены лотки: рабочий А, завершив свою часть, кладёт деталь в лоток; рабочий Б, освободившись, забирает деталь из лотка и приступает к следующей операции. Двое никогда не держат одну деталь одновременно; не требуется сложных договорённостей о том, кто когда к чему прикасается. Лоток — это канал, деталь — это данные, рабочие — это горутины. Система самоорганизуется через архитектуру соединений, а не через централизованный диспетчер, раздающий разрешения.
Ещё одна черта Go, имеющая далеко идущие практические последствия, — автоматическое управление памятью, именуемое сборкой мусора. Когда программа создаёт данные — переменные, структуры, массивы, — эти данные размещаются в оперативной памяти компьютера, занимая там определённое пространство. Когда данные становятся ненужными, занятое ими пространство должно быть высвобождено для повторного использования, иначе память рано или поздно исчерпается. В языках, подобных C, эта обязанность целиком лежит на программисте: он явно запрашивает память, когда она требуется, и явно возвращает её системе, когда надобность отпадает. Такой режим даёт полный контроль, но взамен требует неусыпной бдительности. Забыть освободить память — значит допустить утечку: программа постепенно разбухает, поглощая всё больше ресурсов, пока не упрётся в потолок. Освободить память преждевременно, пока на неё ещё ссылаются другие части программы, — значит заложить мину замедленного действия: рано или поздно программа обратится по адресу, где прежде лежали её данные, и обнаружит там нечто постороннее, что приведёт либо к немедленному краху, либо — что хуже — к тихому искажению результатов.
Go избавляет программиста от этого бремени: среда исполнения сама отслеживает, какие данные ещё достижимы из работающей программы, а какие превратились в сирот, утративших связь с остальным кодом, и автоматически возвращает память, занятую сиротами. Программист просто создаёт значения; об их своевременной кончине и погребении заботится система. За это удобство приходится расплачиваться частью производительности — сборщик мусора сам потребляет процессорное время и может вызывать краткие паузы, — но для подавляющего большинства задач эта плата пренебрежимо мала в сравнении с выигрышем в надёжности и скорости разработки.
Положение Go в ландшафте языков программирования удобно описывать как срединное. Он абстрактнее, чем языки наподобие C, обнажающие аппаратные детали и требующие от программиста самому следить за каждым байтом, но конкретнее, чем языки наподобие Python, укутывающие всё в многослойные абстракции ценой производительности. Эта срединность делает Go особенно пригодным для определённого класса задач: построения серверов, принимающих и обрабатывающих сетевые запросы; написания утилит командной строки, автоматизирующих системные операции; создания инфраструктурного программного обеспечения, на котором, как на фундаменте, возводятся приложения более высокого уровня.
Два инструмента, сделавшихся несущими конструкциями современной облачной инфраструктуры, написаны именно на Go: Docker и Kubernetes. Docker позволяет упаковывать приложение вместе со всем необходимым ему окружением в стандартизированный контейнер — нечто вроде герметичной капсулы, которую можно перемещать между машинами с гарантией, что содержимое будет работать одинаково независимо от особенностей конкретного сервера. Kubernetes занимается оркестрацией таких контейнеров в масштабе от нескольких серверов до десятков тысяч: управляет развёртыванием, масштабированием, распределением нагрузки и восстановлением после сбоев. Оба проекта определяют облик современных вычислений для огромного числа компаний и сервисов, и тот факт, что оба написаны на Go, не является случайным совпадением. Характеристики языка — стремительная компиляция, эффективное исполнение, мощная поддержка конкурентности, простота развёртывания самодостаточных бинарных файлов — делают его естественным выбором для инфраструктурного слоя, где эти качества критически значимы.
Философия проектирования Go находит концентрированное выражение в максиме, которую иногда формулируют как предпочтение композиции наследованию. В ряде языков программирования код организуется через иерархии наследования: определяется общее понятие, затем более частные понятия вводятся как его специализации, автоматически перенимающие свойства и поведение родительского понятия. Так выстраиваются древовидные структуры, где конкретное располагается на листьях, а абстрактное — ближе к стволу. Go вместо этого поощряет композицию: сборку сложного поведения из простых, независимых компонентов, а не надстраивание над существующими конструкциями. Вместо утверждения «утка есть разновидность птицы, которая есть разновидность животного» идиоматический Go предпочитает формулировку «утка обладает способностью летать, способностью плавать и способностью издавать звуки» — и каждая способность определяется отдельно, как самостоятельный кирпичик, пригодный для использования в разных контекстах. Такой подход порождает более плоские, более податливые структуры: кирпичики компактны и слабо связаны друг с другом; их можно сочетать способами, которые не предвиделись при их создании; код легче понять, потому что не приходится подниматься по лестнице наследования, чтобы выяснить происхождение того или иного поведения.
Язык Go, стало быть, представляет собой не просто очередной экспонат в и без того переполненной витрине программистских инструментов, но воплощение определённой философии — убеждённости в том, что осмысленное ограничение способно стать источником свободы, что меньшее при известных условиях оказывается большим, что инструмент, заточенный под конкретный сценарий, может превзойти инструмент, притязающий на универсальность. Создатели Go сделали ставку на то, что разработчикам нужен не язык безбрежных возможностей, а язык продуманных границ — язык, который направляет к добротным решениям не запретами и карами, а тем, что добротные решения оказываются естественными, а сомнительные требуют дополнительных ухищрений. Прошедшие годы в значительной мере подтвердили справедливость этой ставки: Go обрёл собственную нишу и процветает в ней, сделавшись языком выбора для целого поколения инфраструктурного программного обеспечения, на котором зиждется повседневное функционирование цифрового мира.
Показать полностью
Язык C++: минимум знаний для вайбкодинга
Рассмотрим:
1. история и причина появления в контексте других языков программирования
2. как работает код и нюансы архитектуры
Так, начнем:
Когда человек открывает браузер, чтобы прочитать новости или посмотреть видео, он редко задумывается о том, какие механизмы приводят в движение эту повседневную магию. Между щелчком мыши и появлением страницы на экране происходят миллионы операций, и значительная их часть выполняется кодом, написанным на языке программирования C++. Браузеры Chrome и Firefox, движки большинства компьютерных игр, системы, управляющие финансовыми транзакциями на биржах, компоненты операционных систем, даже многие библиотеки машинного обучения, которые внешне выглядят как программы на Python, — всё это в той или иной степени построено на C++. Этот язык, которому уже более сорока лет, продолжает оставаться фундаментом, на котором держится значительная часть современной технологической инфраструктуры, и причины такого долголетия заслуживают внимательного рассмотрения.
Чтобы понять, почему C++ занимает столь особое положение, необходимо обратиться к истории — не столько к хронологии событий, сколько к логике проблем, которые язык был призван решить. В конце 1970-х годов мир программирования существенно отличался от современного. Компьютеры были дорогими, их вычислительные мощности — скромными по нынешним меркам, а программное обеспечение создавалось относительно небольшими командами для решения конкретных задач. Доминирующим языком для системного программирования был C, созданный в начале того десятилетия Деннисом Ритчи в исследовательском подразделении Bell Labs компании AT&T. Язык C обладал замечательными достоинствами: он позволял программисту работать почти на уровне машины, контролируя, как именно данные располагаются в памяти и какие операции выполняет процессор, но при этом оставался достаточно выразительным, чтобы не приходилось писать каждую программу на языке ассемблера. Операционная система Unix, написанная преимущественно на C, демонстрировала, что на этом языке можно создавать серьёзные, долгоживущие системы.
Однако у C имелось ограничение, которое становилось всё более болезненным по мере того, как программные проекты росли в масштабе. Язык не предоставлял средств для организации кода в единицы более высокого уровня, чем функция. Функция — это именованный блок кода, который выполняет определённую задачу, и программа на C представляет собой, по существу, набор функций, работающих с общими данными. Пока функций десять или двадцать, удержать в голове их взаимосвязи несложно. Когда их сотни или тысячи, ситуация меняется качественно. Представьте библиотеку, где все книги лежат на одном огромном столе без какой-либо системы организации. Десять книг найти легко. Сотню — уже затруднительно. Десять тысяч превращают библиотеку в хаос, где поиск нужной книги занимает больше времени, чем её чтение. Программистам требовались полки, разделы, каталоги — способы группировать связанные части кода так, чтобы сложность оставалась управляемой.
Такие способы существовали — в других языках. Simula, разработанная в Норвегии в 1960-х годах, ввела понятие класса: шаблона, описывающего категорию объектов с определёнными свойствами и поведением. Класс можно сравнить с понятием биологического вида или философской категории. Когда мы говорим «собака», мы не имеем в виду какую-то конкретную собаку — мы описываем абстрактное понятие, включающее определённые характеристики и возможности. Конкретный пёс Барбос — это экземпляр этой категории, её реализация в материальном мире. Simula позволяла программисту определять такие категории (классы) и создавать их экземпляры (объекты), что делало структуру программы гораздо более прозрачной. Проблема заключалась в том, что Simula была медленной — слишком медленной для многих практических задач. Возникала дилемма: либо скорость C, либо организационные возможности Simula. Совместить и то, и другое казалось невозможным.
Бьярне Страуструп, молодой датский информатик, работавший в конце 1970-х в той же Bell Labs, где был создан C, оказался именно тем человеком, который нашёл выход из этой дилеммы. Его задачей было моделирование распределённых систем — сетей, в которых множество компьютеров обмениваются информацией. Такое моделирование естественно укладывалось в объектную парадигму: каждый узел сети можно представить как объект, каждое сообщение — как другой объект, взаимодействия между узлами — как обмен сообщениями между объектами. Страуструп знал Simula по своей докторской работе в Кембридже и видел, насколько этот подход облегчает работу со сложными системами. Но скорость Simula делала её непригодной для реальных задач.
Решение Страуструпа состояло в том, чтобы взять C как основу — с его скоростью и близостью к машине — и добавить к нему возможности Simula, реализовав их так, чтобы использование этих возможностей не влекло потерь производительности, если только программист сам не решит ими воспользоваться. Этот принцип — «вы не платите за то, чем не пользуетесь» — стал одним из краеугольных камней философии C++. Первая версия, созданная в 1979 году, называлась прямолинейно: «C with Classes», то есть «C с классами». Название исчерпывающе описывало суть: это был тот же C, к которому добавили механизм классов. Постепенно появлялись новые возможности — виртуальные функции, перегрузка операторов, ссылки, позднее шаблоны — и в 1983 году язык получил имя, под которым известен сегодня. C++ — это программистская шутка: в языке C оператор ++ означает «увеличить на единицу», так что C++ — это, буквально, «C, увеличенный на единицу», следующий шаг после C.
Страуструп не ставил целью создать теоретически безупречный язык, удовлетворяющий критериям академической красоты. Он создавал практичный инструмент для решения реальных проблем, и эта прагматическая установка определила многие особенности C++. Язык допускает разные стили программирования, потому что разные задачи требуют разных подходов. Язык сохраняет совместимость с C, потому что существовавший код на C представлял огромную ценность, которую нельзя было просто отбросить. Язык позволяет делать опасные вещи — напрямую работать с памятью, обходить проверки типов — потому что иногда опасные вещи необходимы для достижения нужной производительности или для взаимодействия с аппаратурой.
Теперь, когда исторический контекст очерчен, можно обратиться к тому, как устроен сам язык и как происходит работа с ним. Программа на C++ существует изначально в виде текстовых файлов — исходного кода, который пишет программист. Эти файлы бывают двух основных типов: файлы реализации с расширением .cpp (или иногда .cc, .cxx) содержат собственно код, описывающий, что и как программа делает; заголовочные файлы с расширением .h или .hpp содержат объявления — описания того, что существует в программе, без подробностей реализации. Это разделение может показаться избыточным, но оно служит важной организационной цели. Заголовочный файл — это своего рода публичный контракт: он сообщает, какие классы и функции доступны и как их использовать, не раскрывая внутреннюю кухню. Файл реализации — это та самая внутренняя кухня. Такое разделение позволяет менять способ работы программы, не затрагивая её внешний интерфейс, и даёт возможность разным частям большого проекта развиваться относительно независимо друг от друга.
Исходный код, написанный программистом, машина выполнять не может — процессор понимает только последовательности чисел, представляющих машинные команды. Перевод исходного кода на язык машины выполняет специальная программа — компилятор. Компилятор читает файлы исходного кода, проверяет их на различные ошибки — синтаксические, логические, связанные с типами данных — и, если ошибок не обнаружено, генерирует исполняемый файл, который уже можно запустить. Для C++ существует несколько широко используемых компиляторов: GCC (его C++-версия называется g++), Clang, Microsoft Visual C++. Они различаются в деталях, но все реализуют единый стандарт языка.
Современные компиляторы делают гораздо больше, чем простой механический перевод. Они выполняют сложнейшие оптимизации, преобразуя код программиста в максимально эффективные машинные инструкции. Программист может писать ясный, структурированный код, а компилятор позаботится о том, чтобы этот код работал быстро. Это разделение труда между человеком и машиной — одно из ключевых достижений современного C++: не нужно жертвовать читаемостью ради производительности.
Центральным понятием C++ является класс. Класс — это определение категории объектов: какие данные они содержат (называемые полями или атрибутами) и какие операции они умеют выполнять (называемые методами или функциями-членами). Объект — это конкретный экземпляр класса, существующий в памяти компьютера в определённый момент времени. Можно определить класс «Книга» с полями «название», «автор», «количество страниц» и методами вроде «открыть на странице», «перелистнуть». Затем можно создать сколько угодно объектов этого класса — конкретных книг, каждая со своими значениями полей, но все с одинаковой структурой и набором операций.
Сила этой абстракции в том, что она позволяет думать о программе в терминах сущностей и их взаимодействий, а не в терминах голой последовательности инструкций. Вместо «сначала выполнить такую-то операцию с такими-то данными, затем другую операцию с другими данными» можно думать «объект-отправитель передаёт сообщение объекту-получателю, который в ответ выполняет действие». Это ближе к тому, как люди думают о мире вне программирования, и потому программы, построенные таким образом, часто легче понимать и модифицировать.
Шаблоны (templates) — ещё одна мощная возможность C++, позволяющая писать код, который работает с разными типами данных. Рассмотрим простую задачу: найти максимум из двух значений. Логика одинакова для целых чисел, для дробных чисел, для строк — сравнить два значения и вернуть большее. Без шаблонов пришлось бы писать отдельную функцию для каждого типа данных, дублируя по существу одинаковый код. С шаблонами можно написать функцию один раз, оставив тип данных параметром, который будет уточнён при использовании. Когда такой шаблон применяется к целым числам, компилятор автоматически создаёт версию для целых чисел; когда к строкам — версию для строк. Вся эта генерация происходит на этапе компиляции, так что в работающей программе нет никаких накладных расходов на «универсальность» — код столь же быстр, как если бы был написан вручную для каждого типа.
Стандартная библиотека C++ интенсивно использует шаблоны. Контейнеры — структуры данных для хранения коллекций элементов — реализованы как шаблонные классы. std::vector, динамический массив, способный расти по мере добавления элементов, может хранить целые числа, строки, объекты пользовательских классов — любой тип, который подставляется в качестве параметра шаблона. Алгоритмы сортировки, поиска, трансформации реализованы как шаблонные функции, работающие с любыми подходящими контейнерами. Это даёт высокую степень повторного использования кода без ущерба для производительности.
Особого внимания заслуживает идиома под названием RAII — аббревиатура от Resource Acquisition Is Initialization, что можно приблизительно перевести как «получение ресурса есть инициализация». Название неуклюжее, но идея элегантна и глубока, и она стала одной из определяющих характеристик программирования на C++. Программы работают с ресурсами: выделяют память для хранения данных, открывают файлы, устанавливают сетевые соединения. Каждый ресурс нужно получить перед использованием и освободить после, иначе возникают проблемы. Незакрытый файл может оставаться заблокированным для других программ. Невозвращённая память постепенно накапливается, и в конце концов программа исчерпывает доступные ресурсы — это называется утечкой памяти.
В языке C вся ответственность за своевременное освобождение ресурсов лежит на программисте. Выделил память — не забудь вернуть. Открыл файл — не забудь закрыть. Когда код между получением и освобождением прост, это не проблема. Но код редко бывает прост: условные переходы, циклы, обработка ошибок создают множество путей выполнения, и на каждом из них нужно помнить об освобождении всех полученных ресурсов. Это огромное поле для ошибок, и такие ошибки — одни из самых коварных: программа может работать почти правильно, лишь понемногу «подтекая», пока не упадёт в самый неподходящий момент.
RAII решает проблему изящно: ресурс привязывается к объекту. Когда объект создаётся, его конструктор — специальная функция, вызываемая при создании — получает необходимый ресурс. Когда объект прекращает существование, его деструктор — функция, вызываемая при уничтожении — автоматически освобождает ресурс. Программисту не нужно помнить об освобождении: язык гарантирует, что деструктор будет вызван, когда объект выйдет из области видимости или будет удалён. Это похоже на библиотечный абонемент, где возврат книги происходит автоматически, когда заканчивается срок — забыть невозможно, система сама позаботится.
Умные указатели — std::unique_ptr и std::shared_ptr — представляют собой применение RAII к управлению динамически выделенной памятью. Обычный указатель в C++ — это просто адрес в памяти, число, указывающее, где хранятся данные. Он ничего не знает о владении, о том, кто отвечает за освобождение памяти по этому адресу. Умный указатель — это объект, который содержит обычный указатель, но добавляет к нему семантику владения. std::unique_ptr выражает единоличное владение: когда unique_ptr уничтожается, память освобождается. std::shared_ptr допускает совместное владение несколькими указателями: память освобождается, когда уничтожается последний из них. Использование умных указателей вместо обычных делает утечки памяти существенно менее вероятными, сохраняя при этом полный контроль над тем, когда и как память выделяется.
Чтобы всё сказанное обрело конкретность, рассмотрим небольшую программу — тот самый пример, который был приведён в начале:
#include #include int main() {std::vector nums = {1, 2, 3};int sum = 0;for (int n : nums) {sum += n;}std::cout << "Sum: " << sum << std::endl;}
Первые две строки начинаются с #include — это директивы препроцессора, инструкции, которые выполняются до собственно компиляции. Они говорят: включить в программу содержимое файлов iostream и vector из стандартной библиотеки. iostream предоставляет средства для ввода и вывода — в частности, объект std::cout для вывода текста. vector предоставляет шаблонный класс динамического массива. Это похоже на указание в начале кулинарного рецепта, какие инструменты понадобятся: прежде чем описывать приготовление, автор сообщает, что потребуется миксер и мерный стакан.
Строка int main() объявляет функцию с именем main, которая возвращает целое число (int — сокращение от integer). Функция main особая: с неё начинается выполнение программы, это точка входа. Фигурные скобки { и } обозначают границы тела функции — всё, что между ними, принадлежит main и выполняется при её вызове.
Строка std::vector nums = {1, 2, 3}; делает несколько вещей одновременно. std::vector — это тип: вектор, хранящий целые числа. Префикс std:: указывает, что vector принадлежит стандартному пространству имён — это механизм организации, предотвращающий конфликты имён в больших программах. Угловые скобки содержат аргумент шаблона, уточняющий, что именно будет хранить вектор. nums — имя переменной, её можно было назвать как угодно. Знак равенства и фигурные скобки {1, 2, 3} — это инициализация: вектор создаётся сразу с тремя элементами.
Следующая строка int sum = 0; проще: объявляется целочисленная переменная sum и инициализируется значением ноль. Она будет накапливать сумму элементов вектора.
Конструкция for (int n : nums) { ... } — это цикл по диапазону, относительно новая синтаксическая возможность C++. Она читается почти как естественный язык: «для каждого целого числа n в коллекции nums выполнить то, что в фигурных скобках». При каждой итерации переменная n последовательно принимает значения элементов вектора: сначала 1, затем 2, затем 3.
Строка sum += n; прибавляет текущее значение n к переменной sum. Оператор += — сокращённая запись для sum = sum + n. После трёх итераций цикла sum будет содержать 6 — сумму чисел 1, 2 и 3.
Наконец, std::cout << "Sum: " << sum << std::endl; выводит результат. std::cout — это объект, представляющий стандартный поток вывода, обычно консоль или терминал. Оператор << направляет данные в этот поток: сначала строку текста "Sum: ", затем значение переменной sum, затем std::endl — символ конца строки, переводящий курсор на новую строку.
Эта программа, при всей её краткости, демонстрирует несколько характерных черт современного C++. Использование стандартной библиотеки — vector и iostream — избавляет от необходимости реализовывать базовые вещи вручную. Шаблоны — vector параметризован типом int — обеспечивают типобезопасность и производительность. RAII работает незаметно: вектор автоматически управляет памятью для своих элементов, выделяя её при создании и освобождая при уничтожении, программисту не нужно об этом заботиться. Современный синтаксис — инициализация списком, цикл по диапазону — делает код выразительным и читаемым. При этом компилятор превратит всё это в эффективный машинный код, работающий с минимальными накладными расходами.
Теперь можно вернуться к более широкой картине и увидеть, какое место C++ занимает в ландшафте языков программирования. Языки можно расположить вдоль спектра между двумя полюсами. На одном — языки, максимально близкие к машине: ассемблер, где каждая инструкция соответствует одной команде процессора. Программист имеет полный контроль, но код громоздок и непереносим — программа для одного типа процессора не будет работать на другом. На противоположном полюсе — языки высокого уровня абстракции: Python, JavaScript, Ruby. Программист работает с удобными конструкциями, не думая о том, как данные хранятся в памяти или сколько тактов процессора займёт операция. Взамен он отдаёт контроль: как именно код выполняется, решает интерпретатор или виртуальная машина, и результат обычно медленнее, чем у низкоуровневых языков.
C++ занимает необычную позицию: он способен работать на обоих концах спектра. Программист может спуститься до уровня отдельных байтов памяти, когда это требуется — при написании драйверов устройств, при оптимизации критичных участков кода, при взаимодействии с аппаратурой. Но он же может подняться до высокоуровневых абстракций — классов с наследованием и полиморфизмом, шаблонов, лямбда-функций, контейнеров и алгоритмов стандартной библиотеки. Эта амбивалентность — одновременно и главное достоинство языка, и источник его сложности.
Области, где C++ доминирует, объединяет требование к производительности, которое не удовлетворяется языками более высокого уровня. Игровой движок должен рендерить шестьдесят кадров в секунду, что оставляет около шестнадцати миллисекунд на каждый кадр — за это время нужно просчитать физику, выполнить логику искусственного интеллекта, подготовить графику к отображению. Система высокочастотной торговли должна реагировать на изменения рынка за микросекунды — тысячные доли миллисекунды, — потому что в этом бизнесе тот, кто медленнее на микросекунду, проигрывает. Браузер должен разбирать и отображать сложные веб-страницы без заметных для пользователя задержек, при том что страницы эти могут содержать тысячи элементов и десятки встроенных скриптов. Во всех этих случаях C++ позволяет достичь нужной скорости, сохраняя при этом структурированный, поддерживаемый код — не монолитный блок машинных инструкций, а осмысленную архитектуру из классов, модулей, компонентов.
Программирование на C++ требует определённой ментальной модели, отличающейся от моделей других языков. Программист должен осознавать, что происходит «под капотом» — не на уровне каждой машинной команды, но на уровне принципов. Когда создаётся объект, программист понимает, где в памяти он располагается: на стеке, если это локальная переменная, или в куче, если выделен динамически. Когда вызывается виртуальная функция, программист знает, что происходит дополнительный уровень косвенности для определения, какую именно функцию вызвать. Это понимание не обязательно для написания работающего кода — современные абстракции C++ позволяют многое делать, не задумываясь о деталях, — но оно необходимо для написания эффективного кода и для диагностики проблем, когда что-то идёт не так.
C++ сегодня — не тот язык, который Страуструп создал в 1983 году. Язык эволюционировал через серию стандартов. C++98 закрепил первоначальный облик. C++11 — стандарт, принятый в 2011 году после долгих лет работы — принёс революционные изменения: умные указатели в стандартной библиотеке, лямбда-функции (анонимные функции, определяемые прямо в месте использования), семантику перемещения (эффективную передачу владения ресурсами), современный синтаксис инициализации, автоматический вывод типов. Последующие стандарты — C++14, C++17, C++20, C++23 — продолжали добавлять возможности, делающие код безопаснее, выразительнее и удобнее для написания.
При этом язык сохраняет обратную совместимость: код, написанный тридцать или даже сорок лет назад, в подавляющем большинстве случаев компилируется и работает в современных компиляторах без изменений. Это и благословение, и бремя. Благословение — потому что накопленные за десятилетия инвестиции в существующий код не обесцениваются, потому что можно постепенно модернизировать старые проекты, смешивая старый и новый стили. Бремя — потому что язык несёт груз исторических решений, которые сегодня были бы приняты иначе, потому что существует множество способов сделать одно и то же, и не все они одинаково хороши.
Сложность C++ стала притчей во языцех в программистском сообществе. Существует шутка, что никто не знает C++ полностью, включая его создателя. Это преувеличение, но оно указывает на реальность: язык огромен, его спецификация занимает полторы тысячи страниц, а взаимодействие различных возможностей порождает тонкости, в которых легко запутаться. Знание того, какие возможности языка использовать в какой ситуации и каких избегать, приходит с опытом и требует не только понимания синтаксиса, но и суждения, вкуса, чувства стиля. Это цена, которую приходится платить за мощь и гибкость инструмента.
Тем не менее, несмотря на сложность — а отчасти и благодаря ей, — C++ продолжает оставаться одним из наиболее востребованных языков. Не только для поддержки унаследованного кода, хотя этого кода действительно много, но и для новых проектов там, где его достоинства критичны. Пока существуют задачи, требующие максимальной производительности без отказа от высокоуровневой организации кода, C++ будет сохранять свою нишу. Это не самый простой язык для изучения и не самый безопасный для использования, но для определённого класса задач он остаётся непревзойдённым инструментом — инструментом, который, подобно скальпелю хирурга, опасен в неумелых руках, но незаменим для тех, кто владеет им профессионально.
Показать полностью

Ответ на пост «Нужен совет»1
кто как начинал
Я начинал с перфокарт на БЭСМ-6,
загружал RT-11 на Электронике-85 с 8 дюймовых дискет, даже играл на нем в LodeRunner
учил язык бейсик на ZX spectrum и БК-001 и Микроше,
на DEC Vax VMS разбирался с сетями,
изучал Borland С++ и Ada на IBM 80286,
подключался к usenet через relcom и demos,
держал FIDO ноду в 5015,
Настраивал сети на Lantastic и Novell Netware,
восхищался OS/2 и WFW 3.11 после MS DOS,
учил теорему Котельникова, для понимания как работает связь, ADSL, Ethernet,
разбирался с TCP/IP, SQL, Linux, Erlang, Python, Go, Kubernetes, Docker, openvswitch и тд и тп.
А, к чему это я все , нехуя тебе в ИТ делать, если даже ты вопрос для гугля сформулировать не можешь.
ИТ это постоянные изменения технологий , поиск и глубокое изучение информации самостоятельно, аргументированные споры с коллегами, вечные дедлайны и синдром самозванца.
Так что забудь, иди дальше ладу гранту проектируй.
Показать полностью
Нужен совет1
Хочу поменять сферу деятельности,задумал войти в it, backend.интересует кто как начинал,выбор курсов может быть,литературы и т д.
кто из вас готов поговорить,дать совет?исходные данные (мои) и т д в личном общении..заранее благодарю!

Продуктовая корзина бэкендера









Показать полностью
9

Цифровая ведьма. Digital для новичков. Frontend vs Backend
Пикабу удалили пост за неправильное размещение ссылки на яндекс.диск
Поэтому ссылка на пдф будет в комментариях.
Показать полностью

Автоматизация Laravel: как сделать процесс разработки быстрой и надёжной
Автоматизация Laravel
Разработка на Laravel становится действительно эффективной, если автоматизировать каждую стадию — от поднятия окружения до тестирования и проверки кода. В этой статье я расскажу, как выстроить рабочий процесс, который минимизирует рутинную работу, повышает качество кода и ускоряет выпуск новых фич.
Материал рассчитан на тех, кто уже знаком с Laravel и хочет внедрить автоматизацию: проверки, стиль, статический анализ, готовый Docker-Compose и др. Ниже — конкретные инструменты, советы и примеры из реального проекта.
Все актуальные скрипты и примеры можно посмотреть в репозитории:
https://github.com/prog-time/git-hooks
Буду рад если вы поддержите репозиторий ⭐️ или напишете свои предложения в раздела Issues
Подготовка окружения через Docker Compose
Я предпочитаю начинать любой Laravel-проект с надёжной конфигурации Docker Compose.
Это даёт:
изолированное окружение разработки, тестирования, мониторинга;
независимые контейнеры, чтобы компоненты не мешали друг другу;
быстрое развёртывание и минимизацию «работы вручную».
Сервисы, которые я поднимаю:
php-fpm — чтобы исполнять PHP-код,
PostgreSQL — база данных,
Redis — кэш и очереди,
Grafana + Loki — для логов и мониторинга,
pgAdmin — интерфейс к БД,
queue - контейнер для очередей запускает php artisan queue:work.
Каждый сервис — в отдельном контейнере. Это даёт гибкость: можно обновлять один сервис без простоя остальных, менять версии без конфликта, и так далее.
Пример docker-compose.yml
Совет: Используйте готовые шаблоны docker-compose.yml, сразу поднимающие весь стек. Это экономит время при старте проекта.
Поддержка единого стиля кода с Laravel Pint
Чтобы соблюдать PSR-12 и единый стиль кода, я пользуюсь laravel/pint.
Пакет Pint для Laravel:
автоматически форматирует файлы PHP по заданным правилам,
позволяет не думать вручную о расстановке скобок, отступах и т.д.
Пример конфигурации pint.json
Запуск Pint перед коммитом гарантирует, что весь код будет в нужном стиле — не нужно править вручную после ревью.
Статический анализ: PHPStan + Larastan
Чтобы ловить ошибки на раннем этапе, я использую связку phpstan/phpstan + nunomaduro/larastan.
Они помогают:
находить ошибки типов,
выявлять недостающие проверки,
предупреждать баги до запуска приложения.
Пример phpstan.neon
Преимущества:
баги выявляются ещё до запуска кода;
повышается стабильность и надёжность проекта;
интеграция в процесс разработки минимально мешает.
Git Hooks и shell-скрипты для проверок
Для поддержания качества кода я использую Git Hooks, которые автоматически проверяют код перед коммитом и пушем. Все проверки вынесены в отдельные shell-скрипты, что позволяет гибко настраивать их для разных проектов.
Основные подходы:
1. Pre-commit: проверка изменённых файлов
Проверяются только новые или изменённые файлы, что ускоряет процесс;
Скрипты запускают Pint и PHPStan, автоматически исправляют стиль и выявляют ошибки;
Если проблем нет, коммит продолжается без задержек.
2. Постепенное исправление старых ошибок
Для старых проектов скрипты проверяют, что количество ошибок в файле уменьшилось хотя бы на 1–2 по сравнению с предыдущим коммитом;
Такой подход позволяет внедрять проверки без блокировки разработки.
3. Проверка наличия тестов для классов
4. Проверка работы Docker-сборки
Совет: интегрируйте эти скрипты с самого начала проекта, чтобы автоматизация стала частью привычного рабочего процесса.
Shell скрипт для работы с PHPStan
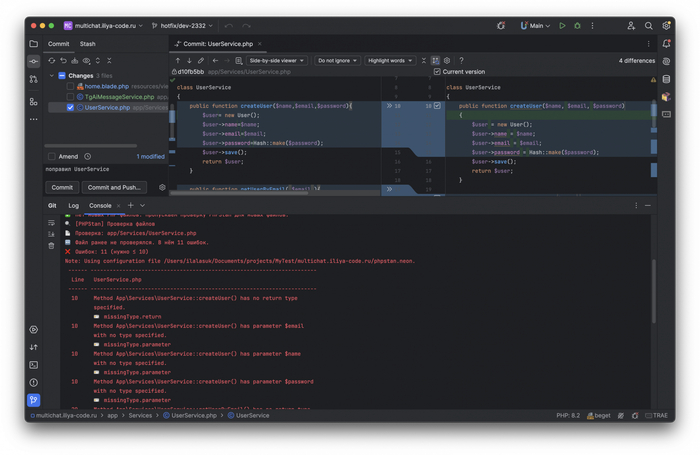
Пример работы PHPStan
Shell скрипт для работы с Pint
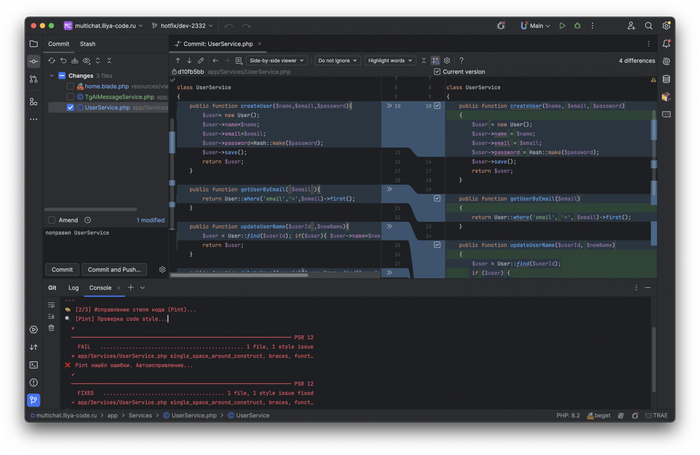
Пример работы с Pint
Проверка наличия тестов для классов
Для достижения этой цели я использую скрипт, который проверяет наличие тестов для каждого PHP-класса, добавленного или изменённого в коммите.
Скрипт получает список изменённых и добавленных PHP-файлов и ищет соответствующий тестовый файл в директории tests.
Например, если в проекте есть класс app/Services/UserService.php, скрипт потребует создать файл теста tests/Unit/Services/UserServiceTest.php. Таким образом, любой новый или изменённый класс обязательно должен иметь соответствующий тест, что помогает поддерживать качество и надёжность кода.
Это скрипт, который постоянно дополняется, поэтому актуальную версию вы можете посмотреть здесь - https://github.com/prog-time/git-hooks
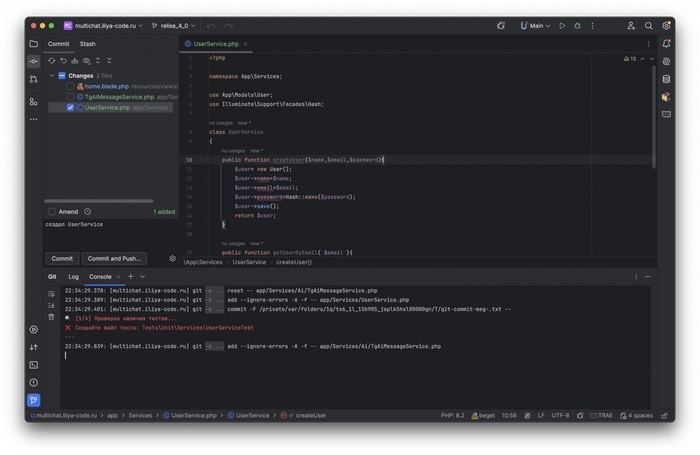
Пример проверки наличия тестов
Проверка работы Docker сборки
Не менее важно регулярно проверять работу Docker сборки. Для этого я создаю отдельный shell-скрипт, который перезапускает все контейнеры и проверяет, что они успешно запустились. Такой подход позволяет убедиться, что изменения в конфигурации или коде не нарушили работу сервисов и приложение корректно поднимается в локальной среде.
Скрипт может автоматически останавливать текущие контейнеры, заново собирать их и запускать в фоне. После запуска выполняется проверка состояния через docker ps или docker compose ps, чтобы убедиться, что все контейнеры находятся в статусе healthy или up.
#!/bin/bash
echo "=== Остановка всех контейнеров ==="
docker-compose down
echo "=== Сборка контейнеров ==="
docker-compose build
echo "=== Запуск контейнеров в фоне ==="
docker-compose up -d
# Пауза для запуска сервисов
echo "=== Ждем 5 секунд для старта сервисов ==="
sleep 5
echo "=== Проверка состояния контейнеров ==="
# Получаем статус всех контейнеров
STATUS=$(docker-compose ps --services --filter "status=running")
if [ -z "$STATUS" ]; then
echo "Ошибка: ни один контейнер не запущен!"
exit 1
else
echo "Запущенные контейнеры:"
docker-compose ps
fi
# Дополнительно можно проверять HEALTHCHECK каждого контейнера
echo "=== Проверка состояния HEALTH ==="
docker ps --filter "health=unhealthy" --format "table {{.Names}}\t{{.Status}}"
echo "=== Скрипт завершен ==="
exit 0
Таким образом, перед деплоем или важными изменениями можно убедиться, что сборка полностью работоспособна и готова к развёртыванию.
Итоги и ключевые принципы
Автоматизация в Laravel — не «фича», а часть рабочего процесса.
Вот основные практики:
настроенное окружение через Docker Compose;
автоматические проверки стиля (Pint);
статический анализ (PHPStan + Larastan);
Git Hooks и скрипты — «сторожи качества» при коммите и пуше;
обязательное тестирование новых и изменённых классов.
Если внедрить всё это, можно:
сократить время на исправления;
поддерживать единообразный стиль кода;
повысить предсказуемость и стабильность приложения;
и главное — освободить команду для работы над функционалом, а не над «ремонтами кода».
Показать полностью
3