

Базы данных. Основа реляционных баз

Основы реляционных баз данных: знакомимся с ключевыми концепциями
💡 Что такое база данных и зачем нужны таблицы?
Представьте себе огромную библиотеку, полную полок с книгами. Чтобы быстро найти нужную книгу, вы используете каталог, который помогает организовать книги по авторам, жанрам или годам издания. Примерно так же устроены и базы данных — системы структурированного хранения информации, позволяющие эффективно искать, обновлять и анализировать данные.
(Позвольте мне далее по тексту использовать сокращённое наименование базы данных — БД.)
На первых этапах знакомства с базами данных у меня сформировалось предвзятое мнение, что все базы данных непременно представляют собой таблицы с рядами записей. Однако реальность гораздо разнообразнее, и далее Мы рассмотрим какие вообще виды баз данных существуют.
(такое представление имеет место быть, так-как самые часто встречающиеся базы данных соответствуют именно такому описанию)
📊 Виды БД (за 4-е место в топе выдаем шоколадку 😄)
(Прошу Вас относится к этому рейтингу как к ориентировочному показателю, иллюстрирующему общую картину популярности различных типов баз данных на сегодняшний день. Приведённые проценты отображают частоту использования каждой категории технологий среди разработчиков и компаний.)
Реляционные БД (~ 70 %) 🏆
Документные БД (~ 20%) 🥈
Ключ-значение БД (~ 10-15%) 🥉
Облачные БД (~ 10%) 🍫
Графовые БД (~ 5-7%)
Колоночные БД (~ 3-5%)
Файловые БД (~ 2-3%)
Объектно-ориентированные БД (< 1%)
❗️❗️ Ввиду того, что данная статья посвящена именно реляционным базам данных, основное внимание сосредоточено на этом типе. В последующих статьях мы также рассмотрим и другие виды БД.
Мы можем заметить, что наиболее распространенным видом БД являются реляционные и это не просто так !
🌟 Почему реляционные базы настолько популярны?
Зрелость модели - реляционная модель, предложенная в 20-м веке ученым Эдгаром Коддом успела пройти проверку временем
Универсальность и совместимость технологий - существует более 160 реляционных СУБД, поддерживающих общие стандарты и язык запросов SQL. Это в значительной степени облегчает миграцию данных и совместимость решений
Поддержка транзакций - реляционные БД предлагают мощный функционал поддержки транзакций, обеспечивающий сохранение целостности данных (что является ключевым параметром многих решений)
Поддержка большинства корпоративных систем (ERP, CRM, BI) - данные системы исторически проектировались под реляционную модель, поэтому в настоящее время большинство крупных и средний предприятий имеют готовые решения, построенные на базе реляционных моделей.
Простота проектирования схем и стандартизация подходов, делают выбор реляционных моделей хранения данных более предпочтительным в отношении других подходов.
Но, реляционные БД это не "серебряная пуля", решающая все проблемы и не имеющая недостатков.
😱 Проблемы реляционных БД
Масштабирование - реляционные БД обладают определенными трудностями при горизонтальном масштабировании (чаще всего по причине, что каждая отдельная БД размещена на физическом сервере с ограниченными ресурсами, что значительно усложняет задачу разделения нагрузки)
Поддержка ACID-транзакций - не смотря на то, что поддержка транзакций является преимуществом реляционных БД, одновременно с этим она может быть и ее недостатком. Поддержание таких свойств, как: атомарность (Atomicity), согласованность (Consistency), изолированность (Isolation), надежность (Durability) может потребовать значительные ресурсы, что в свою очередь повлияет на скорость и производительность системы.
Проблема самой концепции - данные в реляционной БД хранятся разнесенные по таблицам (часто стараются хранить нормализованные данные), со временем увеличивается объемы таблиц, усложняются JOIN- запросы (одна из функций языка SQL), что в свою очередь снижает производительность при работе с данными. (не смотря на наличие индексов)
Перечисленные Выше проблемы (а это далеко не все, но, как мне кажется, одни из основных проблем) влияют на производительность системы и требуют поиска дорогих решений для обхода данных особенностей при использовании реляционных БД
Выше Мы уже упомянули, что основой реляционный БД являются таблицы.
Давайте посмотрим поближе на то, как выглядят таблицы в реляционной БД и что это такое
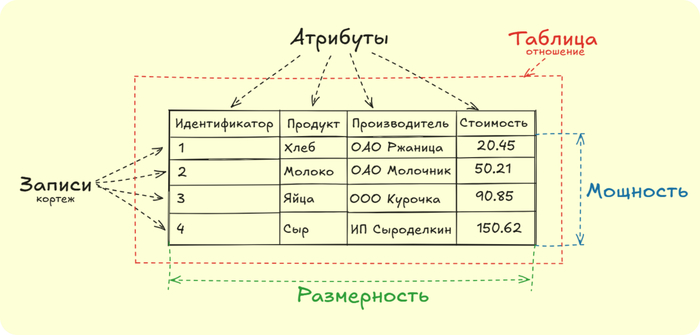
Пример таблицы "Продукты"
Рассмотрим пример таблицы на иллюстрации. Мы видим, что таблицы в реляционной БД имеют свою структуру, описание которой приведем ниже.
Структура таблицы
Таблица (отношение) - основной элемент реляционной БД, представляет собой массив данных, состоящий из строк (записи) и столбцов (атрибуты)
Атрибуты - свойства, определяющие характеристики каждой сущности. Каждому атрибуту соответствует определенный тип данных (числовой, формат даты, строковый).
(Идентификатор, чаще всего, не приходит вместе с данными, а создается искусственно в момент создания записи в таблице)Записи (кортеж) - строка таблицы, которая содержит совокупность значений атрибутов.
Мощность - количество записей в таблице (в нашей таблице мощность = 4)
Размерность - количество атрибутов, описывающих характеристики сущности (в нашей таблице размерность = 4)
Сейчас мы рассмотрели лишь одну таблицу как наглядный пример. Однако на практике в реляционных базах данных встречается огромное множество таблиц, каждая из которых должна учитывать такие ключевые элементы, как мощность, размерность и кортежность. Понимание этих аспектов существенно упрощает процесс проектирования и последующего управления таблицами
Давайте теперь рассмотрим то, как может выглядеть самая простая схема реляционной БД на примере нашей таблицы (Продукты) и двух новых таблиц. (Покупатели и Покупки).
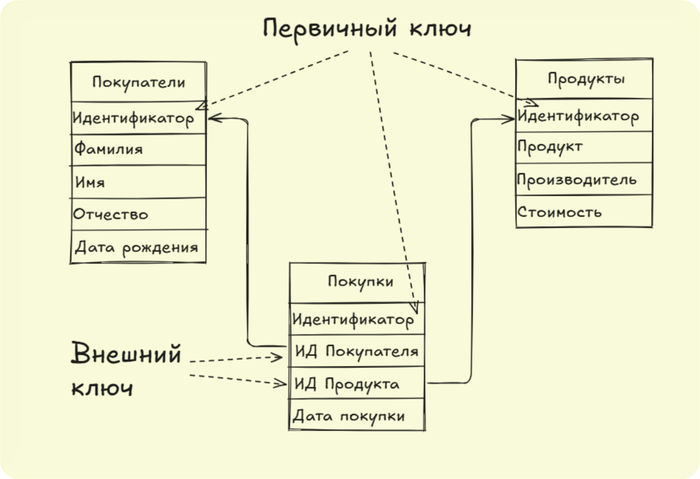
Схема таблиц в реляционной БД
Ранее мы отмечали, что в реляционной базе данных обычно имеется множество таблиц, каждая из которых описывает отдельную сущность. Все эти таблицы связаны между собой с помощью ключевых механизмов — первичных (PK) и внешних (FK) ключей.
Посмотрите на нашу схему сверху: таблица «Покупки» связана с таблицей «Покупатели» с помощью внешнего ключа «Идентификатор покупателя», который фактически ссылается на «Идентификатор» в таблице покупателей. Этот идентификатор гарантирует уникальную привязку каждого покупателя к конкретной покупке.
Аналогично построена связь между таблицей «Покупки» и таблицей «Продукты». Таким образом, любая покупка может быть легко ассоциирована с соответствующим товаром.
Проектирование этих связей выполняется на этапе разработки базы данных, используя специальные команды языка SQL. Но иногда связи отображают лишь схематически, без физического внедрения на уровне данных.
Теперь перейдем непосредственно к основным типам связей между таблицами.
🔗 Типы связей
Один-к-одному - одна запись первой таблицы, связана с одной записью второй таблицы. Данный тип связи встречается не столь часто, как два других.
Один-ко-многим - одна запись первой таблицы, связана с множеством записей второй таблицы. Самый распространенный тип связи на практике.
Многие-ко-многим - множество записей первой таблицы, связаны с множеством записей второй таблицы. Так же достаточно распространенный тип связи, который на практике требует создание таблицы-посредника (связующая таблица).
(Ниже приведены иллюстрации к видам связи. Прошу Вас учитывать, что примеры гипотетические)
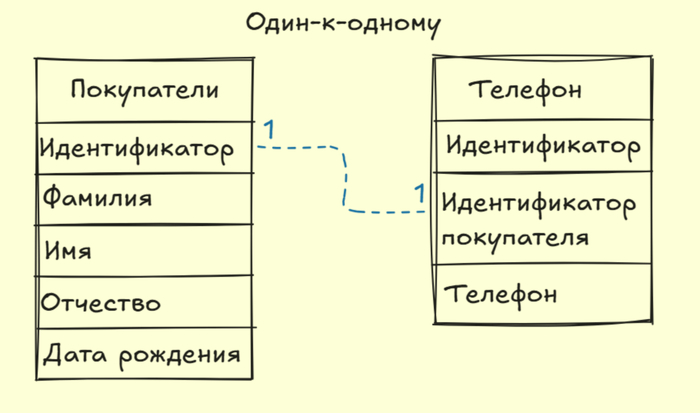
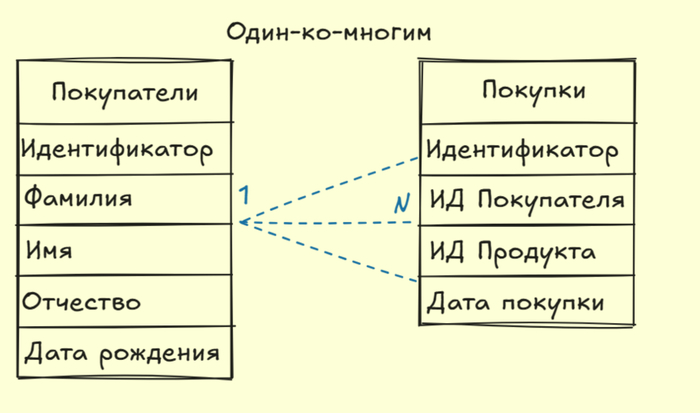
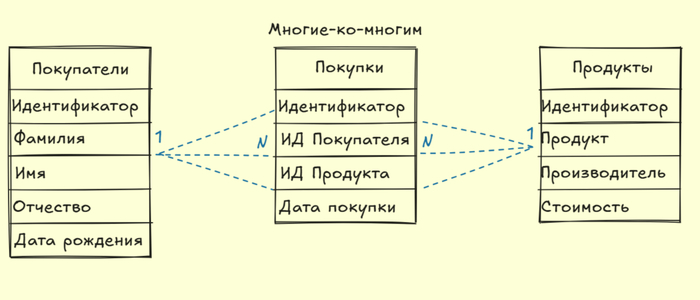
Завершая рассказ об основах реляционных баз данных, особое внимание уделим важной теме — первичным (PK) и внешним (FK) ключам.
Хотя формально использование ключей необязательно, практически их отсутствие нарушает фундаментальные принципы проектирования реляционных БД. Ключи позволяют точно идентифицировать записи, устанавливать связи между таблицами и поддерживать целостность данных.
Именно ключ служит механизмом, гарантирующим уникальность записей внутри таблицы. Далее познакомимся с основными видами ключей.
🔑 Рассмотрим виды ключей
Первичный ключ (Primary Key)
Первичный ключ — это атрибут или набор атрибутов, однозначно идентифицирующих каждую запись в таблице. Основная характеристика первичного ключа — его уникальность: каждая запись обладает уникальным значением.
При создании первичного ключа накладываются следующие ограничения:
Уникальность (каждая запись имеет уникальное значение ключа)
Обязательность заполнения (атрибут не может быть пустым)
Постоянство (значение ключа должно быть постоянным)
Первичные ключи удобно классифицировать по двум критериям:
Способ формирования
Естественный PK - атрибут, присутствующий в самих данных и обладающий уникальностью (например ИНН гражданина, серийный номер товара)
Искусственный PK (суррогатный ) - специально созданный атрибут, формируемый системой автоматически. (самый простой способ - автоинкрементируемое целое число)
Количество элементов
Простой PK - включает единственный атрибут.
Составной PK - формируется из нескольких атрибутов, с целью достижения уникальности.
Важно отметить следующее, что естественный или искусственные ключи могут быть как простыми, так и составными.
Внешний ключ (Foreign Key)
Внешний ключ — это атрибут или набор атрибутов, ссылающийся на значение первичного ключа другой таблицы. Благодаря внешним ключам обеспечивается согласованность и целостностью данных.
Особенности внешнего ключа
Допускает пустые значения, если связь между таблицами необязательна
Проверяет существование соответствующей записи в родительской таблице
Гарантирует соблюдение целостности данных (любая запись ссылается на реально существующую запись в другой таблице)
Определяет иерархические или ассоциативные связи между таблицами. (тут мы имеем ввиду ранее рассмотренные связи один-к-одному, один-ко-многим, многие-ко-многим)
Итак, мы завершили знакомство с основами реляционных баз данных. Рассмотрели базовые понятия, структуру таблиц, типы связей и способы организации ключей.
❤️ Спасибо за Ваше внимание! Надеюсь, эта статья помогла разобраться с ключевыми принципами реляционных баз данных.
📱 Оставайтесь с нами, чтобы получать свежие публикации и полезную информацию по системному анализу в нашей группе системного анализа
Хорошего дня, друзья!






