Предисловие
В условиях растущих требований к обработке больших данных и аналитическим нагрузкам (OLAP) критически важной становится не только настройка самой СУБД, но и тонкая оптимизация операционной системы, на которой она работает. Однако в современных исследованиях и практических руководствах наблюдается значительный пробел: рекомендации по настройке PostgreSQL часто ограничиваются параметрами самой СУБД, в то время как влияние параметров ядра Linux на производительность базы данных остаётся малоизученной областью.
Данная работа направлена на заполнение этого пробела. Фокус исследования сосредоточен на влиянии параметра ядра Linux vm.vfs_cache_pressure на производительность PostgreSQL под синтетической OLAP-нагрузкой. Этот параметр контролирует агрессивность, с которой ядро освобождает кэш файловой системы (VFS cache), что в теории может напрямую влиять на поведение СУБД, активно работающей с файлами данных.
Исследование носит экспериментальный характер и построено на методологии нагрузочного тестирования с использованием специализированного инструмента pg_expecto. В качестве тестовой среды используется конфигурация, типичная для небольших аналитических серверов: 8 CPU, 8 GB RAM, дисковая подсистема, подверженная ограничениям пропускной способности. Это позволяет смоделировать условия, в которых грамотная настройка ОС может стать ключом к раскрытию дополнительной производительности или, наоборот, источником проблем.
Ценность данной работы заключается в её практической ориентированности. Она предоставляет администраторам баз данных и системным инженерам не только конкретные данные о влиянии настройки, но и методологию анализа комплексного поведения системы (СУБД + ОС) под нагрузкой, выходящую за рамки простого мониторинга TPS (транзакций в секунду).
Предпосылка к исследованию
Отсутствие специализированных исследований: Поиск в научных базах данных (Google Scholar, IEEE Xplore) и технических блогах по запросам "vfs_cache_pressure PostgreSQL performance", "Linux kernel tuning for database workload" не выявил работ, фокусирующихся на экспериментальном изучении данного конкретного взаимодействия. Основная масса материалов предлагает общие советы или рассматривает настройку памяти PostgreSQL в отрыве от тонких параметров ОС.
Задача
Оценить влияние изменения параметра vm.vfs_cache_pressure на производительность СУБД и инфраструктуры при синтетической нагрузке, имитирующей OLAP.
Параметры инфраструктуры
vm.dirty_expire_centisecs=3000
vm.dirty_background_ratio=10
Параметры СУБД
shared_buffers = '4GB'
effective_cache_size = '6GB'
work_mem = '32MB'
Нагрузка на СУБД в ходе экспериментов
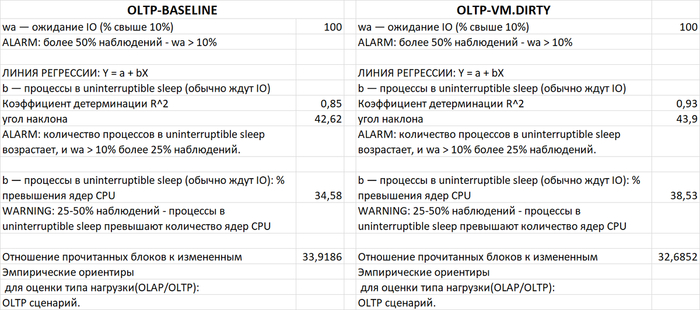
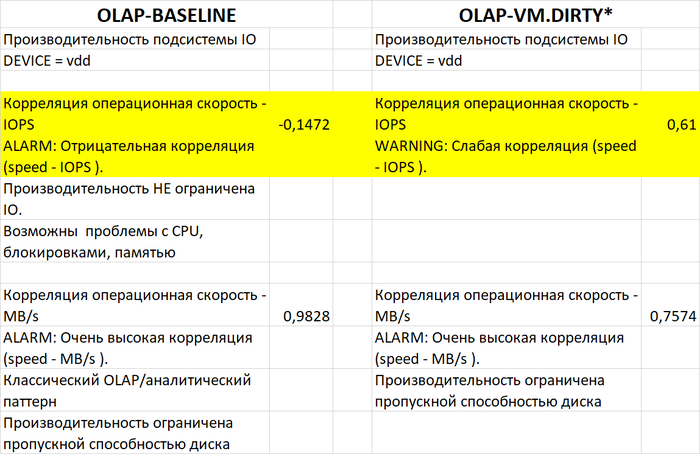
Отношение прочитанных блоков shared_buffers к измененным блокам shared_buffers (OLAP):
vm.vfs_cache_pressure = 100 : 177.98
vm.vfs_cache_pressure = 50 : 184.26
vm.vfs_cache_pressure = 150 : 172.22
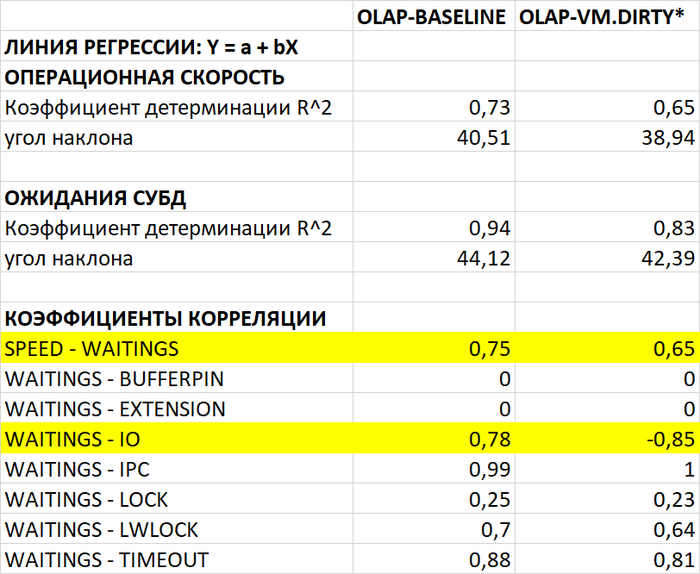
Часть 1 - Общая постановка исследования и результаты производительности СУБД и инфраструктуры.
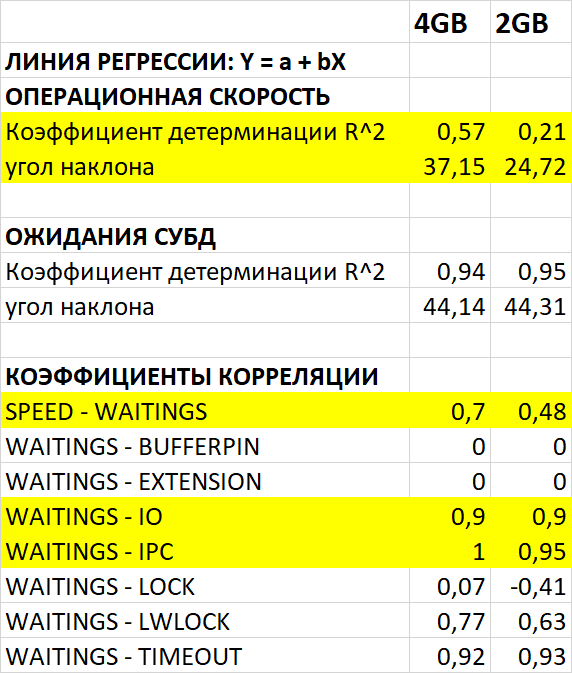
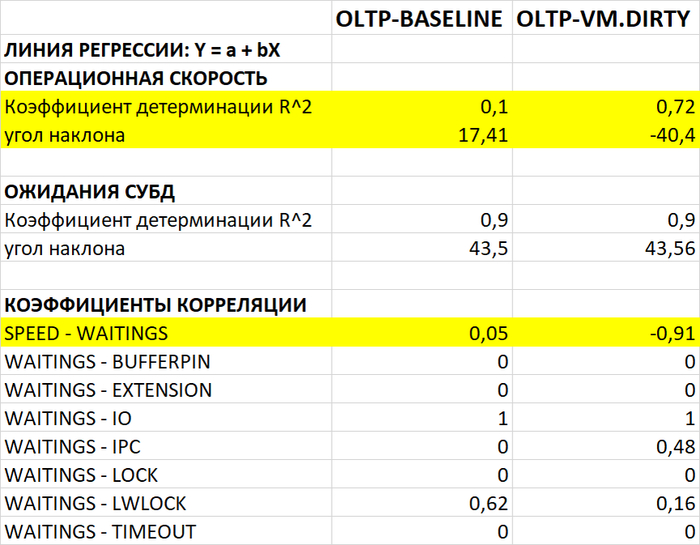
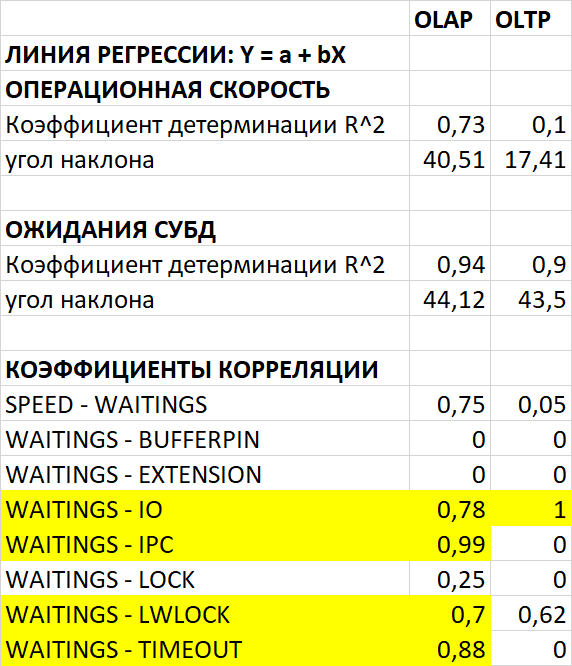
Корреляционный анализ ожиданий СУБД
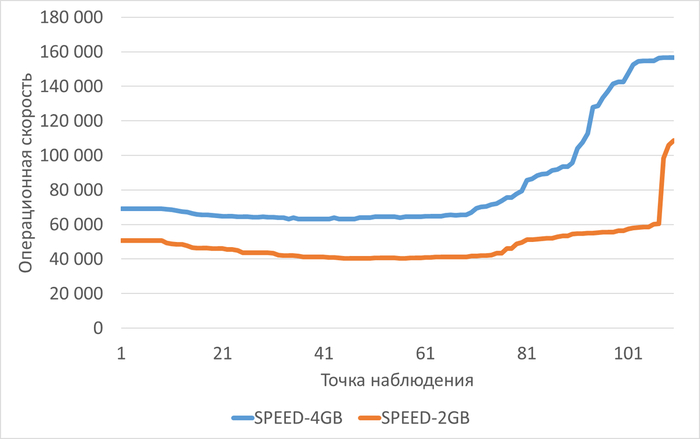
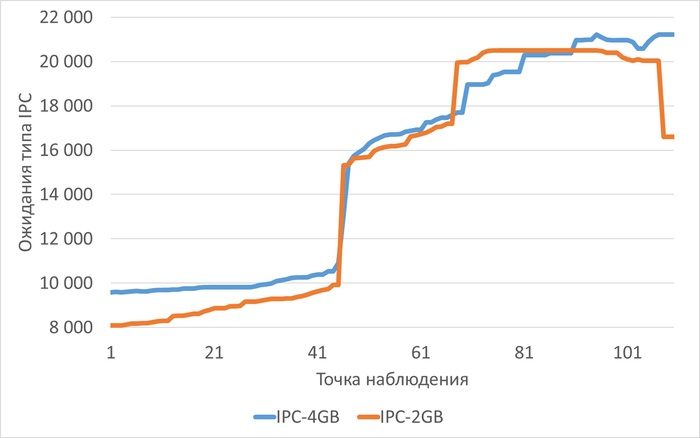
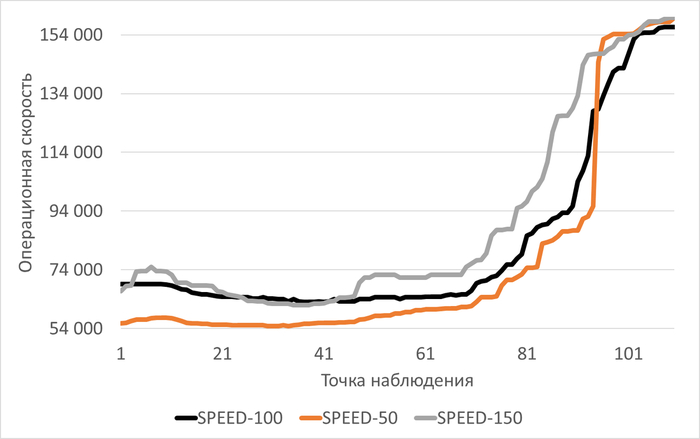
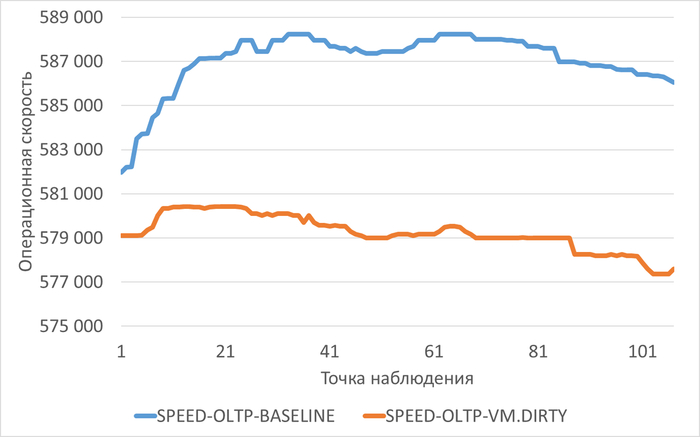
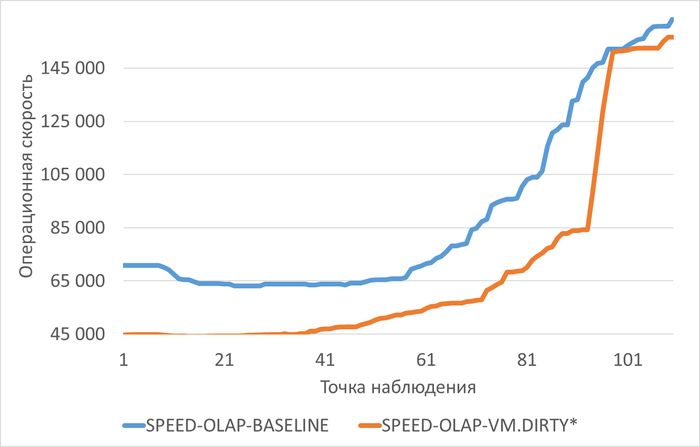
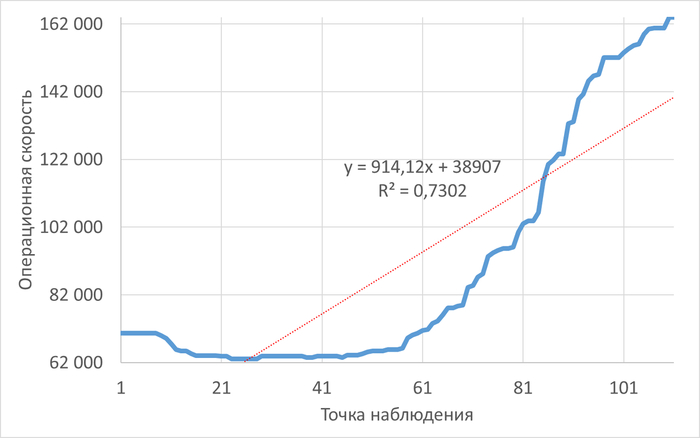
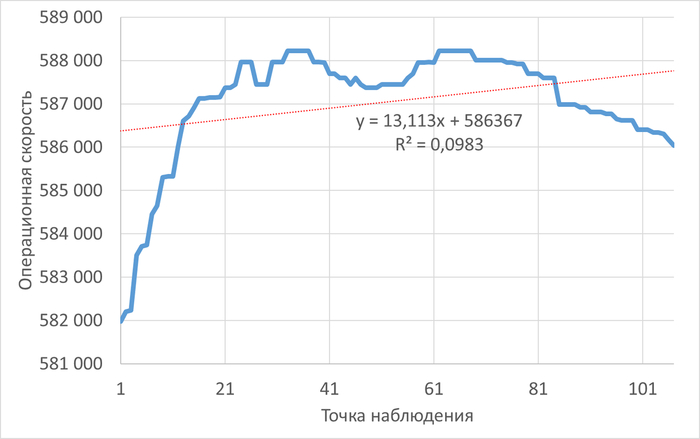
Операционная скорость
Медианные значения операционной скорости:
vm.vfs_cache_pressure = 100 : 15 154 (baseline)
vm.vfs_cache_pressure = 50 : 16 185 (-11.27%)
vm.vfs_cache_pressure = 150 : 15 095 (+8.65%)
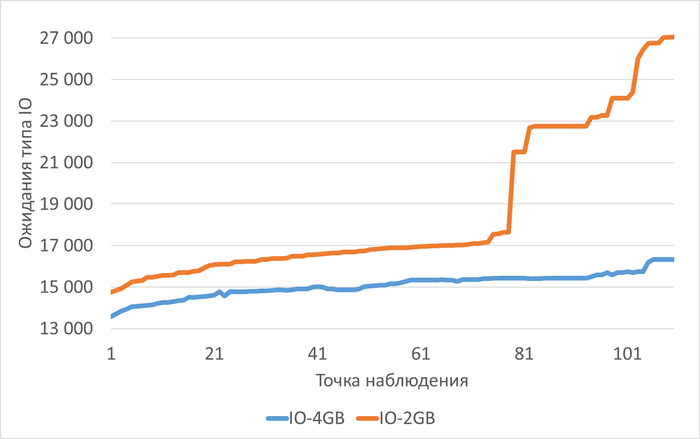
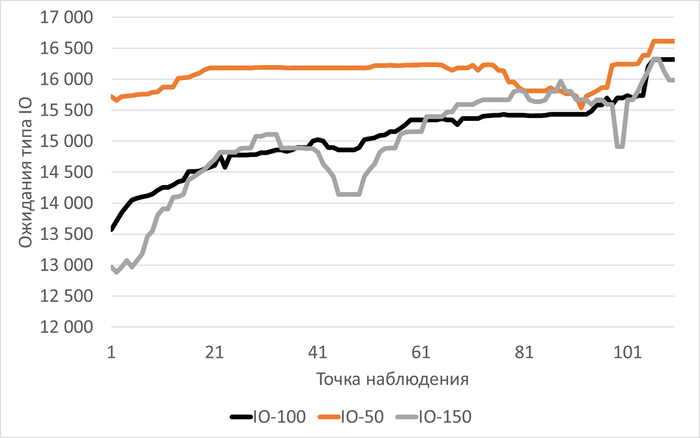
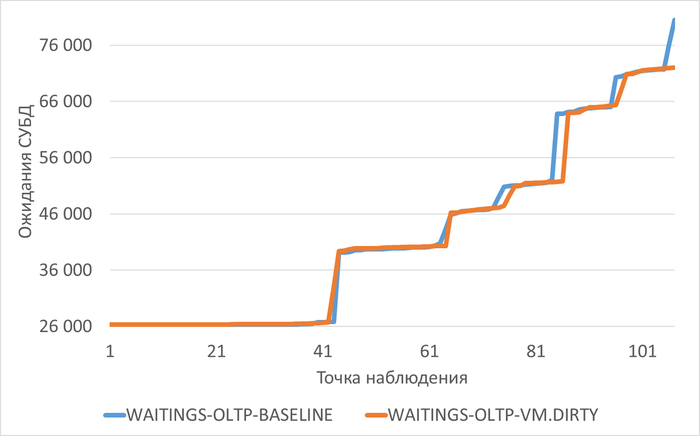
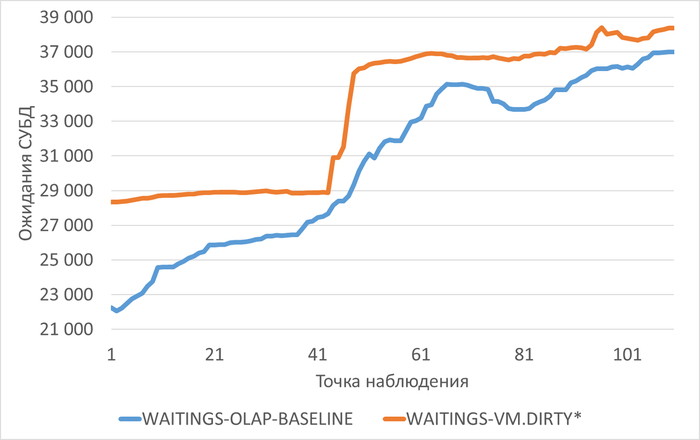
Ожидания типа IO
Медианные значения ожиданий типа IO:
vm.vfs_cache_pressure = 100 : 16 716 (baseline)
vm.vfs_cache_pressure = 50 : 19 411 (+16,12%)
vm.vfs_cache_pressure = 150 : 16 762 (+0,27%)
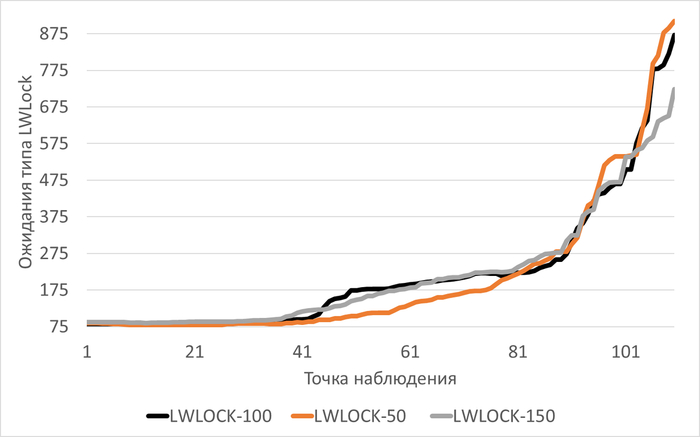
Ожидания типа LWLock
Медианные значения ожиданий типа LWLock:
vm.vfs_cache_pressure = 100 : 178(baseline)
vm.vfs_cache_pressure = 50 : 113 (-36,52%)
vm.vfs_cache_pressure = 150 : 167 (-6,46%)
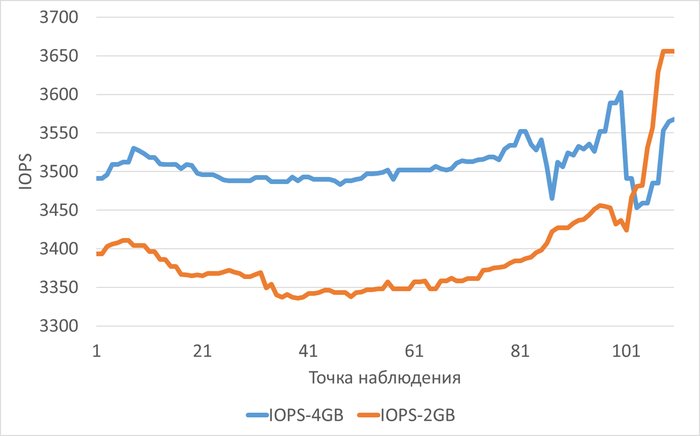
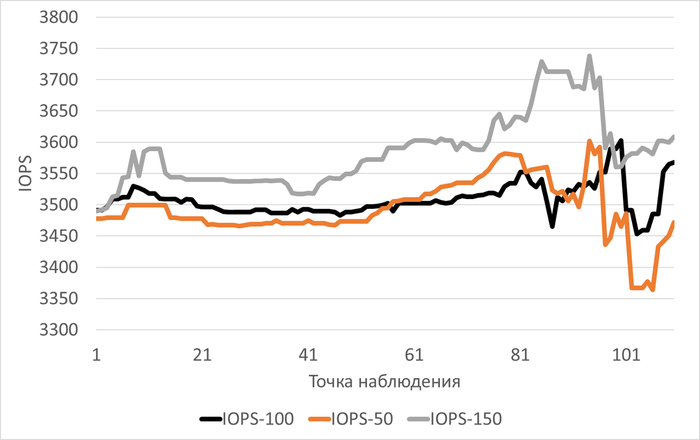
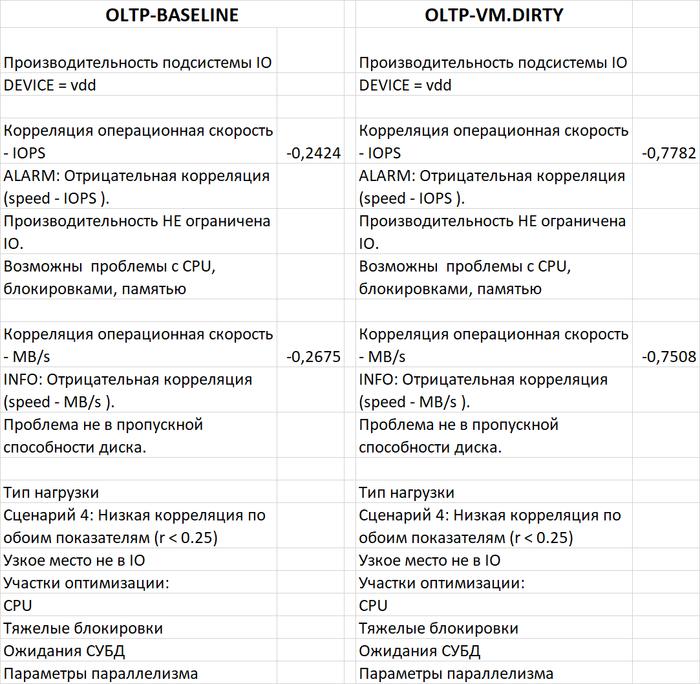
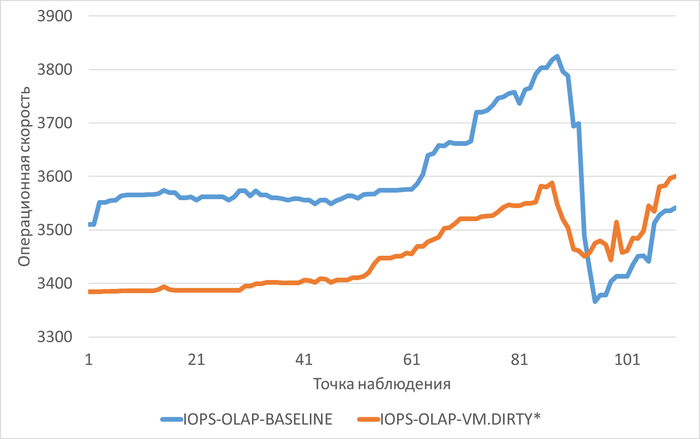
Производительность подсистемы IO (IOPS) файловой системы /data
vm.vfs_cache_pressure = 100 : 3 502(baseline)
vm.vfs_cache_pressure = 50 : 3 479(-0,66%)
vm.vfs_cache_pressure = 150 : 3 582 (+2,28%)
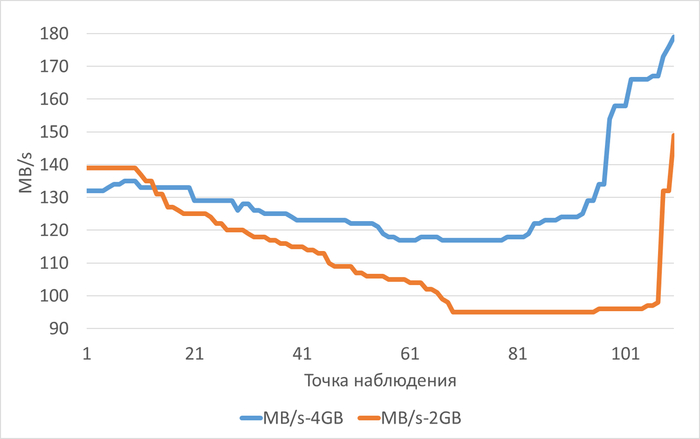
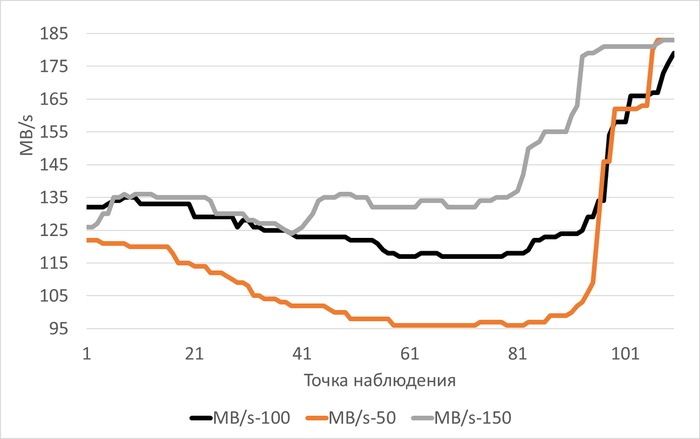
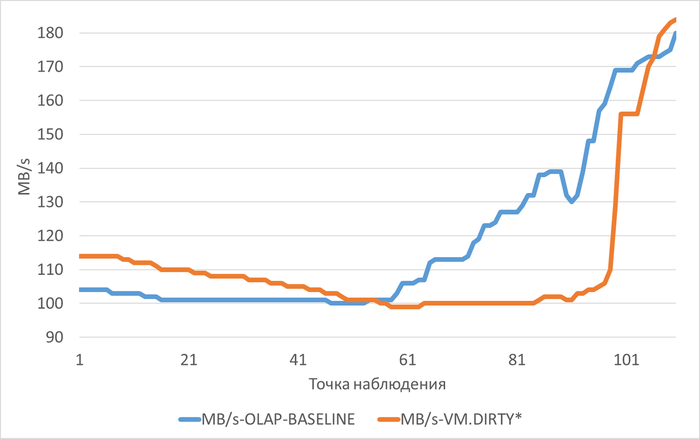
Пропускная способность подсистемы IO (MB/s) файловой системы /data
vm.vfs_cache_pressure = 100 : 125(baseline)
vm.vfs_cache_pressure = 50 : 103(-17,60%)
vm.vfs_cache_pressure = 150 : 135 (+8,00%)
Часть 2 - Анализ паттернов производительности инфраструктуры
Входные данные для анализа
Сводный отчета по нагрузочному тестированию подготовленный pg_pexpecto по окончании нагрузочного тестирования:
Метрики производительности и ожиданий СУБД
Метрики vmstat
Метрики iostat
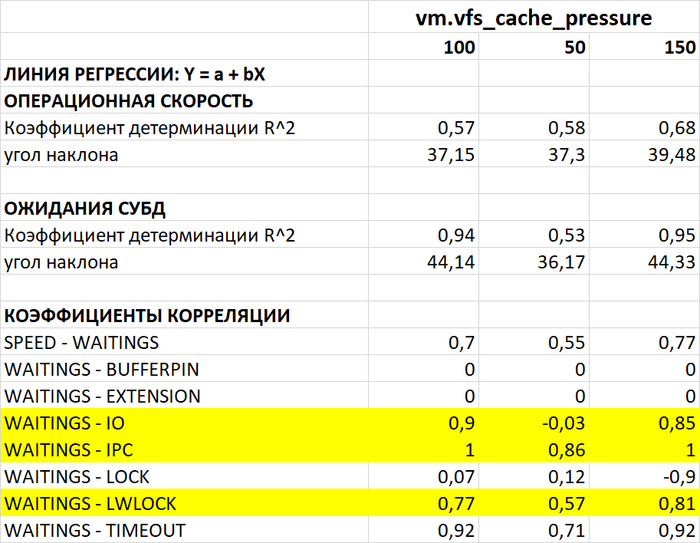
Корреляционный анализ ожиданий СУБД
Корреляционный анализ метрик vmstat
Корреляционный анализ метрик iostat
Общий анализ инфраструктуры при разном значении vm.vfs_cache_pressure
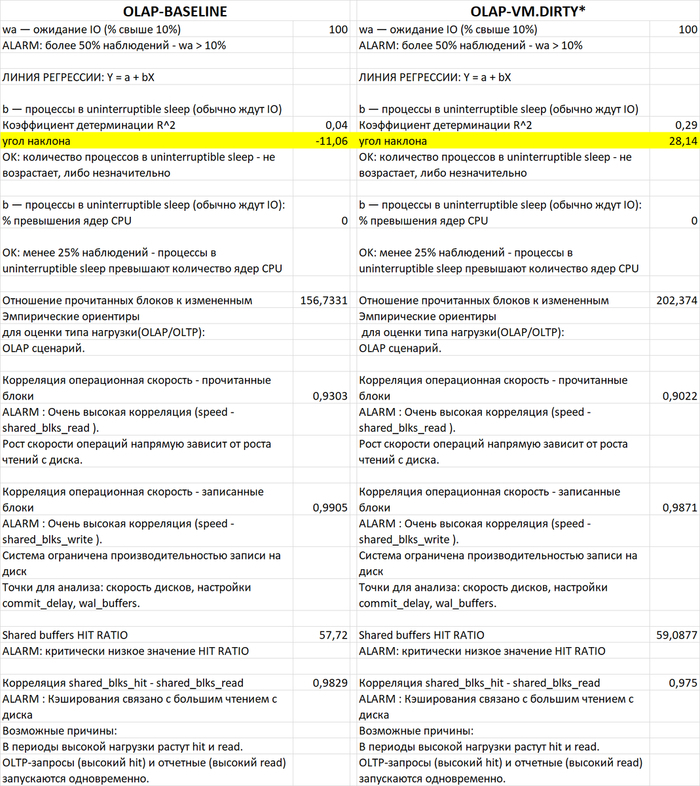
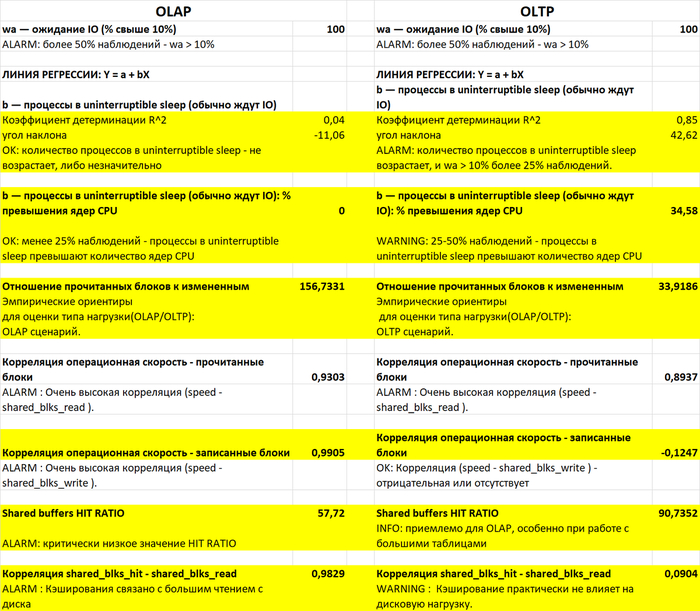
1. Влияние на IO-ожидания (wa)
Общая проблема: Во всех трёх экспериментах 100% наблюдений показывают wa > 10%, что свидетельствует о системном ограничении дисковой подсистемы.
Сравнение корреляций при разных значениях vm.vfs_cache_pressure:
vm.vfs_cache_pressure=50:
Корреляция IO-wa: -0,0772 (отсутствует/отрицательная) ✅
Корреляция IO-b: 0,0609 (слабая/средняя) ℹ️
Корреляция IO-bi: 0,3650 (слабая/средняя) ℹ️
Корреляция IO-bo: 0,2693 (слабая/средняя) ℹ️
vm.vfs_cache_pressure=100:
Корреляция IO-wa: -0,9020 (отсутствует/отрицательная) ✅
Корреляция IO-b: 0,2611 (слабая/средняя) ℹ️
Корреляция IO-bi: 0,2730 (слабая/средняя) ℹ️
Корреляция IO-bo: 0,6533 (высокая) ⚠️
vm.vfs_cache_pressure=150:
Корреляция IO-wa: -0,7379 (отсутствует/отрицательная) ✅
Корреляция IO-b: 0,0000 (отсутствует/отрицательная) ✅
Корреляция IO-bi: 0,5074 (высокая) ⚠️
Корреляция IO-bo: 0,5532 (высокая) ⚠️
Вывод: Увеличение vfs_cache_pressure усиливает корреляцию IO-ожиданий с операциями чтения/записи (bi/bo), что указывает на более агрессивное управление кэшем файловой системы.
2. Паттерны использования процессов в состоянии D (непрерываемый сон)
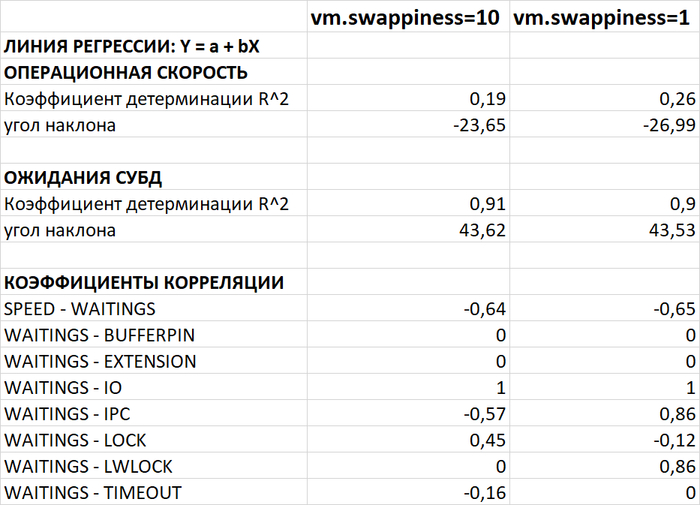
· При vfs_cache_pressure=50: ALARM по регрессионной линии (R²=0,7, угол наклона 39,83)
· При vfs_cache_pressure=100: R²=0,03, угол наклона 10,38 (норма)
· При vfs_cache_pressure=150: R²=0,00, угол наклона 0,00 (норма)
Объяснение с точки зрения управления кэшем:
При OLAP-нагрузке с интенсивным чтением это вызывает:
При значениях 100 и 150 кэш вытесняется активнее, что снижает конкуренцию и количество процессов в состоянии D
3. Производительность дисковой подсистемы и кэширования
Общие характеристики нагрузки (все эксперименты):
Соотношение чтения к записи: ~180:1 (типичный OLAP-паттерн)
Очень высокая корреляция скорости операций с чтением (0,85-0,88)
Очень высокая корреляция скорости операций с записью (0,98-0,99)
Система ограничена производительностью диска
Влияние pressure на эффективность shared buffers:
HIT RATIO shared buffers: 55-58% (критически низкий во всех случаях)
Корреляция shared_blks_hit - shared_blks_read: 0,96-0,97 (очень высокая)
Вывод: vfs_cache_pressure практически не влияет на HIT RATIO PostgreSQL, так как shared buffers управляются отдельно от кэша файловой системы
Ключевые выводы по экспериментам
Лучшие показатели у pressure=100:
Отсутствие роста процессов в состоянии D
Умеренные корреляции с операциями чтения/записи
Стабильное поведение системы
Проблемные зоны (все эксперименты):
Критически низкий HIT RATIO shared buffers (55-58%)
100% наблюдений с wa > 10%
Система ограничена производительностью диска
Рекомендации по оптимизации для OLAP-нагрузки
1. Настройки операционной системы:
Установить vm.vfs_cache_pressure = 100 (компромиссное значение)
Пересмотреть настройки vm.dirty_*:
Уменьшить vm.dirty_background_ratio с 10 до 5
Уменьшить vm.dirty_ratio с 30 до 20
Это снизит латентность записи
Проверить и оптимизировать параметры файловой системы
2. Настройки PostgreSQL для OLAP:
Увеличить shared_buffers с 4GB до 6GB (при 8GB RAM)
Увеличить work_mem с 32MB до 128-256MB для сложных сортировок
Увеличить effective_cache_size до 6-7GB
Рассмотреть увеличение max_parallel_workers_per_gather с 1 до 2-4
Установить random_page_cost = 1.0 (если используются SSD)
Рассмотреть переход на более быстрые диски (NVMe SSD)
Увеличить объём оперативной памяти с 8GB
Проверить балансировку нагрузки между дисками данных и WAL
Анализ влияния vfs_cache_pressure на управление RAM
1. Использование оперативной памяти
Динамика memory_swpd (использование свопа):
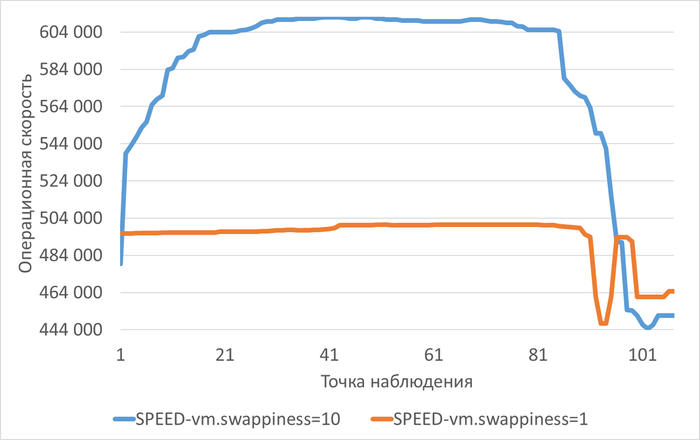
vfs_cache_pressure=50: Рост с 209 MB до 347 MB (+138 MB за 110 минут)
vfs_cache_pressure=100: Рост с 260 MB до 328 MB (+68 MB за 111 минут)
vfs_cache_pressure=150: Рост с 246 MB до 338 MB (+92 MB за 110 минут)
Наиболее медленный рост swpd при vfs_cache_pressure=100 (68 MB за период)
Наиболее быстрый рост при vfs_cache_pressure=50 (138 MB за период)
Промежуточный рост при vfs_cache_pressure=150 (92 MB за период)
Стабильность использования памяти:
Наиболее стабильное поведение при vfs_cache_pressure=100:
Наименьший рост использования свопа
Плавное изменение memory_swpd без резких скачков
Более предсказуемое управление памятью
Наименее стабильное поведение при vfs_cache_pressure=50:
2. Свопинг (swap in/out)
Статистика по экспериментам:
При vfs_cache_pressure=100:
swap in: 9.01% наблюдений
swap out: 1.80% наблюдений
Минимальный объем записи в своп
1. vfs_cache_pressure=50:
Низкое давление на кэш файловой системы
Ядро менее агрессивно освобождает кэш
Чаще приходится читать из свопа (высокий swap in)
Относительно низкий swap out - меньше данных вытесняется
2. vfs_cache_pressure=100:
Оптимальный баланс
Кэш управляется эффективно
Минимальный swap out - редко требуется запись в своп
Умеренный swap in - меньше обращений к свопу
3. vfs_cache_pressure=150:
Высокое давление на кэш файловой системы
Ядро агрессивно освобождает кэш
Высокий swap out - активная запись в своп
Высокий swap in - частые чтения из свопа
3. Кэширование и dirty pages
Взаимодействие vfs_cache_pressure с настройками vm.dirty_*:
vm.dirty_ratio=30 (запись блокируется при 30% dirty pages)
vm.dirty_background_ratio=10 (фоновая запись при 10%)
read_ahead_kb=4096 (4MB read-ahead)
Влияние pressure на dirty pages:
1. vfs_cache_pressure=50:
Медленное освобождение кэша
Больше данных остается в памяти
Более высокий риск достижения dirty_ratio
Потенциальные блокировки записи при всплесках нагрузки
2. vfs_cache_pressure=100:
Сбалансированное управление
Кэш освобождается своевременно
Меньше риск блокировок из-за dirty pages
Оптимально для текущих настроек dirty_*
3. vfs_cache_pressure=150:
Быстрое освобождение кэша
Меньше данных в кэше файловой системы
Чаще требуется чтение с диска
Возможна излишняя агрессивность для OLAP
Оптимальные значения для OLAP-нагрузки:
Для OLAP с большим чтением рекомендуется:
vfs_cache_pressure=100-120 (компромиссное значение)
read_ahead_kb=8192-16384 (увеличение для последовательного чтения)
vm.dirty_background_ratio=5 (более частая фоновая запись)
vm.dirty_ratio=20 (раньше начинать синхронную запись)
OLAP характеризуется последовательным чтением больших объемов данных
Большой read-ahead улучшает производительность последовательного чтения
Более низкие dirty_* значения снижают латентность записи
vfs_cache_pressure=100 обеспечивает баланс между кэшированием и доступной памятью
Анализ влияния vfs_cache_pressure на CPU
1. Нагрузка на CPU
Распределение CPU времени по экспериментам:
us (user time): 21-61% (среднее ~30%)
sy (system time): 5-10% (среднее ~7%)
wa (I/O wait): 17-31% (среднее ~27%)
id (idle): 12-42% (среднее ~35%)
us (user time): 25-57% (среднее ~35%)
sy (system time): 5-10% (среднее ~7%)
wa (I/O wait): 18-29% (среднее ~25%)
id (idle): 14-41% (среднее ~33%)
us (user time): 22-58% (среднее ~32%)
sy (system time): 5-10% (среднее ~7%)
wa (I/O wait): 16-28% (среднее ~24%)
id (idle): 13-41% (среднее ~34%)
Влияние vfs_cache_pressure:
User time: Наиболее высокий при pressure=100 (среднее 35%)
System time: Практически идентичен во всех случаях (~7%)
I/O wait: Наименьший при pressure=150 (среднее 24%)
Idle time: Наибольший при pressure=50 (среднее 35%)
Вывод: Увеличение pressure снижает I/O wait, но незначительно увеличивает user time, что указывает на более активную обработку данных приложением.
2. Переключения контекста
Влияние управления кэшем на переключения контекста:
1. vfs_cache_pressure=50:
Менее агрессивное управление кэшем
Меньше системных вызовов для управления памятью
Переключения контекста в основном вызваны прерываниями от дисковых операций
2. vfs_cache_pressure=100:
Сбалансированное управление кэшем
Умеренное количество системных вызовов для управления памятью
Прерывания остаются основной причиной переключений контекста
3. vfs_cache_pressure=150:
Агрессивное управление кэшем
Увеличение системных вызовов для управления памятью
Появление корреляции cs-sy указывает на рост времени ядра на управление памятью
Объяснение корреляции cs-sy при pressure=150:
Ядро тратит больше времени на:
Вытеснение страниц из кэша файловой системы
Управление списками страниц памяти
Обработку запросов на выделение/освобождение памяти
Это приводит к увеличению system time и связанных с ним переключений контекста
3. Очередь выполнения (run queue)
Статистика по экспериментам:
Проценты превышения ядер CPU: 7.27%
Максимальное значение procs_r: 10 процессов
Более стабильная очередь выполнения
Проценты превышения ядер CPU: 16.22%
Максимальное значение procs_r: 11 процессов
Наименее стабильная очередь выполнения
Проценты превышения ядер CPU: 14.55%
Максимальное значение procs_r: 11 процессов
Промежуточная стабильность
Наиболее стабильная очередь при pressure=50:
Наименьший процент превышения ядер CPU (7.27%)
Более равномерное распределение нагрузки
Меньше конкуренции за CPU ресурсы
Наименее стабильная очередь при pressure=100:
Наибольший процент превышения ядер CPU (16.22%)
Более выраженная конкуренция за CPU
Возможные задержки в обработке запросов
Рекомендации по балансировке vfs_cache_pressure
Для конфигурации: 8 CPU ядер, 8GB RAM, OLAP-нагрузка с интенсивным чтением
1. Оптимальный диапазон значений: vfs_cache_pressure = 90-110
Компромисс между производительностью и стабильностью:
vfs_cache_pressure=50: лучшая стабильность очереди выполнения, но выше I/O wait
vfs_cache_pressure=150: ниже I/O wait, но выше нагрузка на ядро (system time)
vfs_cache_pressure=100: баланс между этими крайностями
2. Сопутствующие настройки для OLAP-нагрузки:
Настройки операционной системы:
vm.swappiness = 10 (уже установлено, оптимально для серверов)
vm.dirty_background_ratio = 5 (уменьшить с 10 для более частой фоновой записи)
vm.dirty_ratio = 20 (уменьшить с 30 для снижения латентности записи)
read_ahead_kb = 16384 (увеличить для последовательного чтения OLAP)
Настройки PostgreSQL для 8 CPU ядер:
max_parallel_workers_per_gather = 2-4 (увеличить с 1 для OLAP)
max_worker_processes = 16 (уже установлено, оптимально)
max_parallel_workers = 16 (уже установлено, оптимально)
work_mem = 64-128MB (увеличить с 32MB для сложных сортировок)
Часть 3 - Анализ производительности подсистемы IO для файловой системы /data
Задача
Проанализировать параметра vm.vfs_cache_pressure на производительность подсистемы IO для дискового устройства, используемого файловой системой /data.
Входные данные для анализа
Сводный отчета по нагрузочному тестированию подготовленный pg_pexpecto по окончании нагрузочного тестирования:
Анализ корреляций и типа нагрузки
vm.vfs_cache_pressure = 100
Корреляция скорость–IOPS: слабая (0,4128).
Корреляция скорость–MB/s: очень высокая (0,8191).
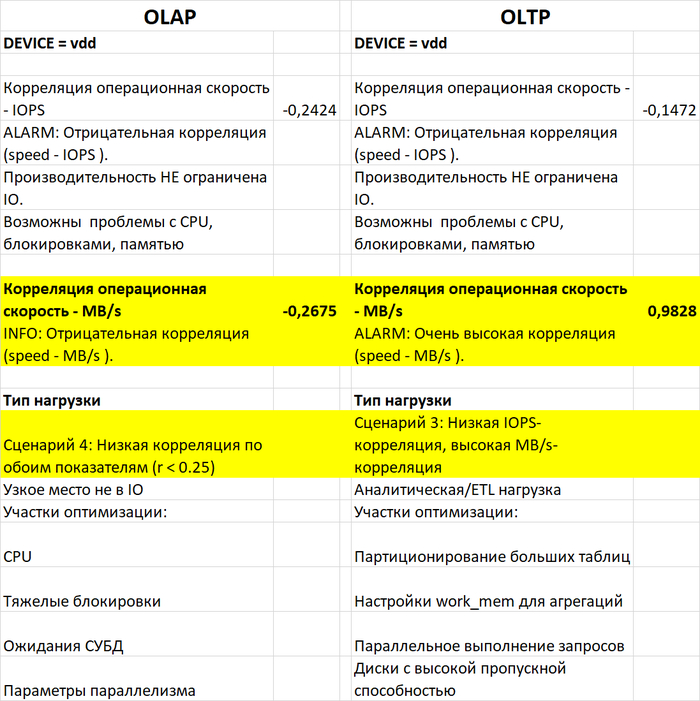
Тип нагрузки: аналитическая/ETL, так как наблюдается высокая зависимость от пропускной способности диска, а не от IOPS.
Ограничивающий фактор: пропускная способность диска (MB/s).
Дополнительные наблюдения:
Утилизация диска стабильно высокая (89–94%).
Задержки чтения/записи умеренные (9–14 мс).
Нагрузка на CPU в режиме ожидания I/O (wa) составляет 18–29%.
vm.vfs_cache_pressure = 50
Корреляция скорость–IOPS: отрицательная (-0,2879).
Корреляция скорость–MB/s: очень высокая (0,8017).
Тип нагрузки: аналитическая/ETL с выраженной зависимостью от пропускной способности диска.
Ограничивающий фактор: пропускная способность диска (MB/s).
Дополнительные наблюдения:
Утилизация диска близка к максимальной (95–96%).
Задержки чтения растут со временем (до 16 мс).
Отрицательная корреляция с IOPS указывает на возможные проблемы с CPU, блокировками или памятью.
Нагрузка на CPU в режиме ожидания I/O (wa) достигает 31%.
vm.vfs_cache_pressure = 150
Корреляция скорость–IOPS: слабая (0,5930).
Корреляция скорость–MB/s: очень высокая (0,9735).
Тип нагрузки: аналитическая/ETL с сильной зависимостью от пропускной способности диска.
Ограничивающий фактор: пропускная способность диска (MB/s).
Дополнительные наблюдения:
Утилизация диска стабильно высокая (89–95%).
Задержки чтения/записи низкие (6–11 мс).
Нагрузка на CPU в режиме ожидания I/O (wa) снижается к концу теста (до 16%).
Сводные выводы
1. Все три эксперимента показывают схожую картину:
Производительность ограничена пропускной способностью диска (MB/s), а не IOPS.
Нагрузка носит аналитический/ETL-характер (последовательное чтение/запись больших объёмов данных).
2. Влияние vm.vfs_cache_pressure:
Увеличить пропускную способность дисковой подсистемы .
Настроить параметры PostgreSQL для аналитических нагрузок (work_mem, maintenance_work_mem, effective_io_concurrency).
Рассмотреть использование партиционирования таблиц и параллельного выполнения запросов.
Сравнение метрик диска
Средние значения метрик по экспериментам:
vm.vfs_cache_pressure = 50:
utilization: 95,1%
r_await: 13,8 мс
w_await: 6,6 мс
IOPS: 3 490
MB/s: 116,1
aqu_sz: 43,8
cpu_wa: 27,3%
vm.vfs_cache_pressure = 100:
utilization: 92,7%
r_await: 12,5 мс
w_await: 7,0 мс
IOPS: 3 513
MB/s: 129,6
aqu_sz: 40,5
cpu_wa: 25,4%
vm.vfs_cache_pressure = 150:
utilization: 92,7%
r_await: 9,8 мс
w_await: 7,3 мс
IOPS: 3 570
MB/s: 137,5
aqu_sz: 33,5
cpu_wa: 23,6%
Анализ влияния vfs_cache_pressure:
Задержки и утилизация диска:
r_await последовательно снижается с ростом параметра: 13,8 мс (50) → 12,5 мс (100) → 9,8 мс (150)
w_await незначительно увеличивается: 6,6 мс (50) → 7,0 мс (100) → 7,3 мс (150)
Утилизация диска максимальна при значении 50 (95,1%), при 100 и 150 стабилизируется на уровне 92,7%
Наилучшие показатели задержек чтения достигаются при максимальном значении 150
Связь с пропускной способностью и IOPS:
Пропускная способность (MB/s) монотонно растёт: 116,1 (50) → 129,6 (100) → 137,5 (150)
IOPS также увеличивается: 3 490 (50) → 3 513 (100) → 3 570 (150)
Наблюдается чёткая тенденция: чем выше vfs_cache_pressure, тем выше производительность по пропускной способности
Поведение очереди запросов (aqu_sz):
Длина очереди последовательно уменьшается: 43,8 (50) → 40,5 (100) → 33,5 (150)
Это свидетельствует о более эффективной обработке запросов при высоких значениях параметра
Уменьшение очереди коррелирует со снижением времени ожидания CPU (cpu_wa)
Ключевые выводы:
Увеличение vfs_cache_pressure до 150 даёт наиболее сбалансированные результаты:
Наименьшие задержки чтения (9,8 мс против 13,8 мс при 50)
Наибольшая пропускная способность (137,5 MB/s против 116,1 при 50)
Самая короткая очередь запросов (33,5 против 43,8 при 50)
Наименьшая нагрузка на CPU в режиме ожидания (23,6% против 27,3% при 50)
Параметр vfs_cache_pressure оказывает существенное влияние на производительность дисковой подсистемы:
Более высокие значения способствуют более агрессивному освобождению кэша
Это снижает contention за память и уменьшает задержки
Однако может незначительно увеличить задержки записи
Для данной аналитической нагрузки оптимальным является значение 150, которое обеспечивает лучшую пропускную способность при меньших задержках и нагрузке на систему.
Итог исследования
Проведённое комплексное исследование убедительно демонстрирует, что параметр ядра Linux vm.vfs_cache_pressure оказывает статистически значимое и многогранное влияние на производительность PostgreSQL при OLAP-нагрузке, имитирующей последовательное чтение больших объёмов данных.
Ключевые обобщённые выводы:
Тип нагрузки является определяющим: Во всех экспериментах система упиралась в пропускную способность диска (MB/s), а не в IOPS, что характерно для аналитических (OLAP) паттернов с последовательным доступом. Это главный ограничивающий фактор в данной конфигурации.
Влияние на кэширование и память:
Параметр практически не влияет на hit ratio внутреннего кэша PostgreSQL (shared buffers), что подтверждает их независимое управление.
Однако он существенно влияет на управление кэшем файловой системы (VFS cache) и подкачкой (swap). Более низкие значения (50) приводят к меньшей агрессивности вытеснения кэша, что вызывает более быстрый рост использования свопа и большее количество процессов, блокированных в состоянии ожидания ввода-вывода (D-состояние). Более высокие значения (150) заставляют ядро активнее освобождать кэш.
Влияние на производительность диска: Наблюдается чёткая тенденция: с ростом vfs_cache_pressure увеличивается пропускная способность (MB/s) и снижаются задержки чтения (r_await). Наилучшие показатели дисковых операций были достигнуты при значении 150.
Влияние на загрузку CPU и стабильность: Значение параметра также влияет на баланс загрузки процессора. Более высокие значения снижают время ожидания ввода-вывода (wa), но могут незначительно повысить системное время (sy) из-за активного управления памятью и привести к менее стабильной очереди выполнения процессов (run queue).
Недостатки тестовой конфигурации: Исследование выявило системные проблемы, общие для всех тестов:
Критически низкий hit ratio shared buffers (55-58%), указывающий на недостаточный объём оперативной памяти для данной рабочей нагрузки.
Постоянно высокий уровень ожидания ввода-вывода (wa > 10%), подтверждающий, что диск является узким местом.
Общие рекомендации для OLAP-нагрузок на PostgreSQL:
Аппаратные улучшения (более быстрые NVMe SSD, увеличение RAM) имеют высший приоритет для снятия выявленных ограничений.
Оптимизация ОС: Уменьшение vm.dirty_* соотношений для снижения латентности записи и увеличение read_ahead_kb для ускорения последовательного чтения.
Оптимизация PostgreSQL: Увеличение shared_buffers, work_mem, effective_cache_size и настройка параметров параллельного выполнения.
Анализ расхождений в рекомендациях: vm.vfs_cache_pressure = 100 vs 150
В исследовании содержится кажущееся противоречие: в Части 2 оптимальным названо значение 100, а в Части 3 — 150. Причина этих разных рекомендаций заключается не в ошибке, а в разном фокусе анализа и приоритетах, которые они отражают. Это наглядная иллюстрация того, что процесс оптимизации — это всегда выбор компромиссного решения из набора альтернатив.
Рекомендация из Части 2: vm.vfs_cache_pressure = 100
Фокус анализа: Общая стабильность системы, поведение процессов, управление памятью и свопом.
Ключевые аргументы:
Стабильность процессов: Отсутствие аномального роста процессов в состоянии D (блокировка).
Управление памятью: Наиболее стабильное и предсказуемое использование свопа (наименьший рост).
Сбалансированность: Умеренные корреляции между метриками, отсутствие экстремальных паттернов.
Компромисс: Оптимальный баланс между удержанием данных в кэше и их своевременным освобождением.
Приоритет: Надёжность и предсказуемость долгосрочной работы системы.
Рекомендация из Части 3: vm.vfs_cache_pressure = 150
Фокус анализа: Максимальная производительность дисковой подсистемы, задержки и пропускная способность.
Ключевые аргументы:
Производительность диска: Наивысшая пропускная способность (137.5 MB/s) и наименьшие задержки чтения (9.8 мс).
Эффективность очереди: Самая короткая очередь запросов к диску, что указывает на более эффективную обработку.
Разгрузка CPU: Наименьшая нагрузка процессора в режиме ожидания I/O (wa).
Механизм: Агрессивное освобождение кэша снижает конкуренцию (contention) за оперативную память.
Приоритет: Максимальная скорость обработки данных и минимизация времени выполнения задач.
Заключительный вывод по выбору значения
Обе рекомендации верны в своих контекстах. Выбор между 100 и 150 — это классический инженерный компромисс между «быстро» и «стабильно».
Для продакшен-среды, где критически важны предсказуемость, стабильность и отсутствие аномалий (внезапные блокировки процессов), следует придерживаться рекомендации vm.vfs_cache_pressure = 100 (или диапазон 90-110).
Для выделенных ETL-задач или пакетной аналитической обработки, где ключевая цель — минимизировать время выполнения и диск является подтверждённым узким местом, можно обоснованно применить значение vm.vfs_cache_pressure = 150 для получения максимальной пропускной способности, отдавая себе отчёт в потенциально возросшей нагрузке на подсистему памяти ядра.
Таким образом, исследование не даёт единственно верного ответа, а предоставляет администратору обоснованный выбор в зависимости от конкретных бизнес-требований и приоритетов, подчёркивая, что эффективная оптимизация — это всегда поиск баланса между конфликтующими целями системы.