Генеративные нейросети уже изменили мир цифрового искусства, но настоящая магия начинается, когда ты сам берешь их под контроль. Сегодня расскажу о своем эксперименте по обучению LoRA на стиле South Park — от сбора датасета до финальной модели. Поделюсь реальным опытом, техническими нюансами и самое главное — что конкретно сработало, а что оказалось пустой тратой времени.
Меня зовут Илья, я основатель онлайн-нейросети для создания изображений ArtGeneration.me, техноблогер и нейро-евангелист.
Идея обучить LoRA на стиле мультсериала пришла ко мне случайно. На глаза попался новый анимационный сериал «Ваш дружелюбный сосед Человек-паук», и я подумал: «Было бы классно обучить LoRA именно на этом стиле!». Я уже обучал LoRA на отдельных персонажах и простых стилях, но на таких сложных и комплексных особо ещё не тренировал.
Но стиль человека-паука показался мне слишком сложным для первого эксперимента такого рода. Решил сначала потренироваться на чем-то попроще. И тут удачно подвернулась спешл-серия South Park! Стиль South Park простой, узнаваемый, многие его любят (включая меня). На Civitai уже была одна LoRA South Park, так что я подумал — если смог кто-то другой, то и я смогу!
Спойлер: всё оказалось гораздо сложнее, чем я думал. Но обо всём по порядку.
❯ Как собрать датасет, не сдохнув от скуки
Первое, что нужно для обучения LoRA — качественный датасет. У меня была FullHD-серия South Park — идеальное качество для набора скриншотов. Осталось только придумать, как эти скриншоты делать быстро и удобно.
Для просмотра видео я использую MPV. Раньше сидел на MPC-HC, но он стал подтормаживать на некоторых 4K рипах, так что я переехал на MPV. Он не только быстрее, но и поддерживает кучу всяких приколюшек типа скриптинга. Хотя для наших целей хватит и встроенной функции скриншотов.
Функция сохранения кадров в MPV активируется нажатием клавиши S (только на английской раскладке, что важно). Но чтобы не хранить скриншоты где попало, стоит настроить плеер. Создаём файл конфигурации по пути C:\Users\[имя_пользователя]\AppData\Roaming\mpv\mpv.conf (можно быстро перейти через Win+R → %APPDATA%\mpv → Enter). Если папки mpv нет – создайте её.
Вот содержимое файла mpv.conf:
screenshot-directory="C:/Users/user/Pictures/Screenshots/mpv"
screenshot-template="%F/%P"
screenshot-format=png
save-position-on-quit=yes
resume-playback=yes
(Замените user на ваше имя пользователя)
Что делает каждая строчка: screenshot-directory задаёт путь для скриншотов, screenshot-template определяет формат имени (где %F - имя видео, %P - позиция), screenshot-format выбирает PNG для лучшего качества, а две последние строки заставляют плеер запоминать где вы остановились и автоматически продолжать с этого места при следующем запуске. Таким образом мы решаем и проблему скриншотов, и вечный вопрос — «а где я остановился в прошлый раз?».
Вооружившись настроенным MPV, я посмотрел несколько серий South Park, нажимая S в ключевые моменты. Это, кстати, гораздо веселее, чем может показаться — сидишь себе, ржёшь над Картманом и заодно собираешь датасет.
В итоге у меня набралось около 150 скриншотов. Но для качественного обучения мало просто надёргать кадров — нужно тщательно их отфильтровать: убрать смазанные кадры, выкинуть неудачные ракурсы, оставить только типичные для стиля примеры. Для тренировки LoRA на персонажа обычно достаточно ~30 изображений, а вот для стиля нужно больше — до 200. У меня осталось около 120 кадров после фильтрации.
❯ Подготовка изображений к обучению
Теперь встал вопрос обработки. Обучение модели будет проходить в разрешении 1024×1024, а мои скриншоты были другого формата. Без паники! Python-скрипт спешит на помощь!
Для тех, кто никогда не работал с Python, вот краткая инструкция: скачайте и установите Python с официального сайта, при установке поставьте галочку «Add Python to PATH», потом откройте командную строку (Win+R, введите «cmd») и выполните команду pip install pillow для установки библиотеки обработки изображений.
Теперь создайте текстовый файл с названием resize_images.py, вставьте в него код ниже, поместите файл в папку со скриншотами и запустите двойным кликом:
from PIL import Image
import os
# Создаем выходную директорию, если её нет
output_dir = "outputs"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Получаем все файлы изображений из текущей директории
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff', '.webp']
image_files = []
for file in os.listdir('.'):
if any(file.lower().endswith(ext) for ext in image_extensions) and os.path.isfile(file):
image_files.append(file)
# Обрабатываем каждое изображение
for i, file in enumerate(image_files):
try:
# Открываем изображение
img = Image.open(file)
# Принудительно конвертируем в RGB (убираем прозрачность)
img = img.convert('RGB')
# Получаем размеры изображения
width, height = img.size
# Определяем новые размеры, сохраняя соотношение сторон
if width > height:
# Если ширина больше высоты, устанавливаем ширину = 1024
new_width = 1024
new_height = int(height * (new_width / width))
else:
# Если высота больше ширины, устанавливаем высоту = 1024
new_height = 1024
new_width = int(width * (new_height / height))
# Изменяем размер изображения с сохранением пропорций
resized_img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
# Сохраняем с порядковым номером в формате PNG с максимальным качеством
output_path = os.path.join(output_dir, f"{i+1:03d}.png")
resized_img.save(output_path, format='PNG', optimize=True, compress_level=0)
print(f"Обработано {file} -> {output_path} ({new_width}x{new_height})")
except Exception as e:
print(f"Ошибка при обработке {file}: {e}")
print(f"Завершена обработка {len(image_files)} изображений.")
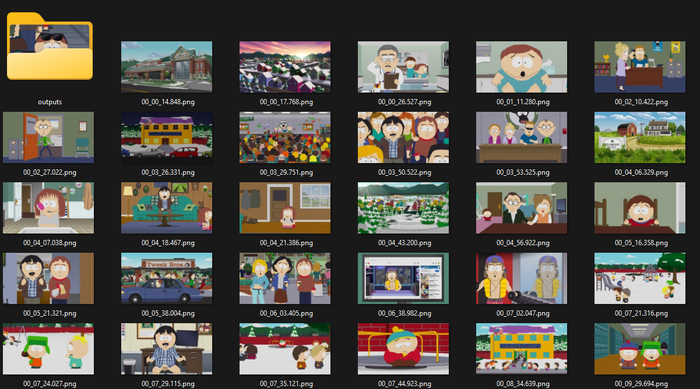
Этот скрипт делает несколько полезных вещей: сохраняет пропорции изображений, убирает прозрачность (чтобы не было проблем при обучении), нумерует файлы последовательно и оптимизирует PNG для лучшего качества. После запуска вы получите в папке outputs все обработанные изображения.
❯ Создание описаний для изображений
Следующий шаг — создание текстовых описаний (по-английски это называется captioning) для изображений. Нейросети учатся на парах «картинка + описание», и от качества описаний очень зависит результат.
Если бы я делал LoRA для чего-то безобидного, то использовал бы Florence-2 от Microsoft. Эта модель шикарно описывает обычные сцены и довольно быстрая. Но с South Park ситуация сложнее — там NSFW-контент, который Florence-2 не сможет нормально обработать (стесняется).
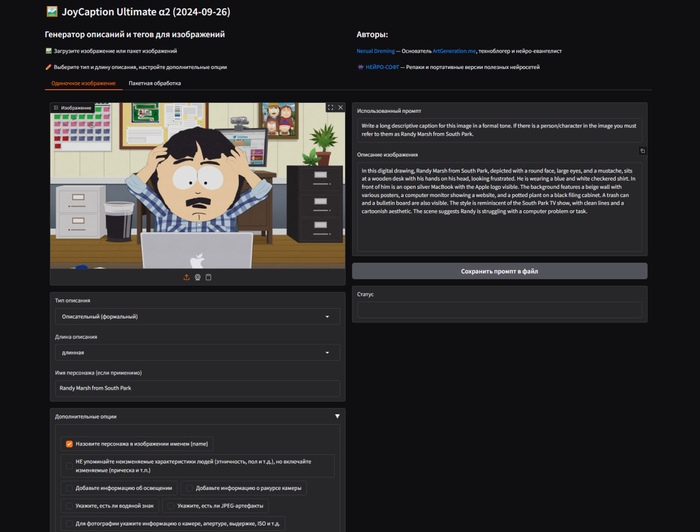
Я перепробовал кучу инструментов для создания описаний и в итоге остановился на Joy Caption Alpha Two. Эта модель меня покорила тем, что в ней есть более 19 различных настроек, разные типы описаний (включая стили Midjourney и Fusion) и основа на визуальной языковой модели, что даёт более подробные и точные описания.
Но возникла проблема — Joy Caption обрабатывает изображения только по одному, а у меня их 120! Сначала я искал готовые решения для пакетной обработки, но нашел только несколько cli, которые у меня даже не запустились. Пришлось закатать рукава и сделать свою локальную версию, за одно прикрутил к ней перевод и пакетный режим обработки.
Несколько вечеров кодинга (и некоторое количество психованных удалений файлов) — и я смог сделать работающую локальную версию с мультирежимом. Я хорошо потрудился, чтобы превратить это в портативную версию, которая запускается даже на видеокартах с 12 ГБ памяти.
Результатом стал JoyCaption Ultimate α2, который я выложил на канал Нейрософт, где публикуются репаки и портативные версии различных нейросетей. Моя модификация умеет генерировать описания в 9 разных режимах, поддерживает расширенные инструкции, разные стили и длину описаний, а также позволяет визуально проверить и исправить неудачные промпты в пакетном режиме.
Обработка 120 изображений заняла около 5 минут на RTX 4090. Главное — результат получился отличный, с корректными описаниями всех особенностей стиля South Park. На выходе мы получаем папку с результатами, в которой лежат все картинки и у каждой есть txt файл с промптом.
❯ Запуск обучения в FluxGym
Теперь, когда у меня был готовый датасет с картинками и описаниями, можно было приступать к самому обучению. Для этого я использовал FluxGym, установленный через Pinokio.
Pinokio — это удобный инсталлер для различных нейросетей. Установка проста: заходите на сайт, скачиваете, запускаете. Через интерфейс Pinokio находите FluxGym, жмёте Install, ждёте загрузки компонентов — и вуаля, у вас есть рабочий инструмент для обучения LoRA специально под модель Flux.
После запуска FluxGym появляется окошко с настройками. Я закинул свой датасет и настроил такие параметры:
Ранг: 4 (мне казалось, что для простого стиля South Park этого достаточно)
Эпохи: 13
Повторения: 10
Генерация сэмплов каждые 500 шагов
Добавил параметры --w 1280 --h 768 --s 20 для настройки превью, чтобы они генерировались с нормальным разрешением, а не стандартным 512×512
Запустил обучение и стал с нетерпением ждать результатов... И тут произошёл первый шок.
❯ Дневник Роршаха, 4 апреля: результаты разваливались на глазах
Результаты были... мягко говоря, неутешительными. Фоны получались более-менее нормальными, но персонажи — просто ужас какой-то. Месиво из десятков одинаковых Картманов, наложенных друг на друга, деформированные лица, непонятные конечности.
«Нет, это не очередной трип Паркера и Стоуна, это были мои плохо натренированные LoRA», — думал я, глядя на эту цифровую какофонию. Раньше я тренировал LoRA на персонажах, и никаких проблем не возникало. Почему же сейчас всё пошло не так?
❯ Эксперименты с параметрами обучения
Гуглинг подсказал, что для стилей, возможно, нужен более высокий ранг LoRA. Это влияет на глубину обучения — чем выше ранг, тем глубже модель может изучить особенности стиля.
Я решил попробовать обучение с рангом 128. Результаты стали лучше, но объем модели раздулся до полутора гигабайт! Решил попробовать компромиссный вариант: ранг 64, при котором LoRA весит примерно 500-600 МБ, что уже приемлемо.
Также я кардинально снизил скороть обучения. По умолчанию в FluxGym используется --learning_rate 8e-4, а я уменьшил до --learning_rate 2e-4, то есть в 4 раза. Это должно было предотвратить переобучение, но увеличило время тренировки. Вместо нескольких часов обучение заняло почти полдня. Но ради качества можно и подождать.
В процессе экспериментов я также пришел к выводу, что лучше ставить количество повторов равным 1, а желаемую продолжительность обучения регулировать числом эпох. Это даёт бóльшую гибкость и упрощает анализ результатов.
❯ Звёздный дневник, 38 мая 3.057 года: переученность видна невооружённым глазом
Примерно на 260-й эпохе я начал замечать явные признаки переобучения — множество зрачков в глазах персонажей, смазанные формы, снижение качества изображений. Пора было останавливаться. К тому времени обучение шло уже около суток.
Я решил остановиться на 255-й эпохе, и у меня получилось 90 файлов моделей с разных этапов обучения. Но как теперь понять, какая из них лучшая?
Автоматизация тестирования моделей
Для начала я написал простой скрипт, который создал мне список всех файлов в папке:
import os
from datetime import datetime
# Получаем текущую папку, откуда запущен скрипт
current_folder = os.getcwd()
# Имя выходного файла
output_file = 'file_list.txt'
# Открываем файл для записи
with open(output_file, 'w', encoding='utf-8') as f:
f.write(f"Список файлов в текущей папке: {current_folder}\n")
f.write(f"Дата: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write("-" * 50 + "\n\n")
# Получаем список всех файлов в текущей папке и подпапках
for root, dirs, files in os.walk(current_folder):
# Получаем относительный путь от текущей папки
rel_path = os.path.relpath(root, current_folder)
if rel_path != '.':
f.write(f"\nПапка: {rel_path}\n")
else:
f.write("Текущая папка:\n")
# Записываем все файлы из этой папки
for file in sorted(files):
f.write(f" {file}\n")
print(f"Список файлов сохранен в {output_file}")
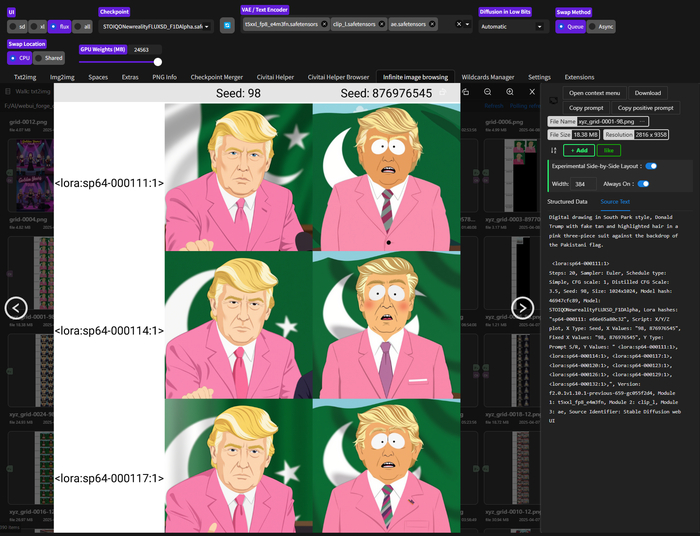
Затем скормив в ЛЛМ список, я составил последовательность для тестирования с равномерной выборкой примерно каждой 30-й эпохи:
<lora:sp64-000003:1>, <lora:sp64-000030:1>, <lora:sp64-000060:1>, <lora:sp64-000087:1>, <lora:sp64-000114:1>, <lora:sp64-000144:1>, <lora:sp64-000171:1>, <lora:sp64-000198:1>, <lora:sp64-000228:1>, <lora:sp64-000255:1>
Для тестирования я использовал Stable Diffusion WebUI Forge. Хоть этот форк A1111 и устаревает, он всё ещё удобен для многих задач. Особенно круто в нём работает скрипт X/Y/Z plot, который позволяет автоматически протестировать разные LoRA и получить наглядную таблицу.
Я использовал функцию PROMPT S/R (Search and Replace), чтобы автоматически перебрать все варианты LoRA. Для тестов я использовал такие промпты:
Digital drawing in South Park style A fat boy sits astride a cow, with a red barn behind him
Digital drawing in South Park style a policeman is sitting in a strip club, a naked stripper is showing her breasts on stage.
Digital drawing in South Park style tricycle chase, fat boy with glasses rides after red-haired boy in green ushanka hat, cinematic
Результаты тестирования, я небрежно сложил на онлайн доску, можно посмотреть.
❯ Ошибка новичка при тестировании
После первых тестов я понял свою глупую ошибку — я тестировал на промте, похожем на те, что были в моём датасете! Так делать нельзя, ведь это не показывает реальную гибкость модели.
Я составил более короткие и совершенно другие промпты, и результаты оказались ГОРАЗДО лучше. Оказывается, проблема была не в моделях, а в моём тестировании!
❯ Финальный раунд экспериментов и открытия
После нескольких циклов тестирования я обнаружил несколько интересных закономерностей:
LoRA на ранге 128 выглядит интереснее, чем на ранге 4 — она глубже изучает стиль и не так топорно его применяет. Высокий ранг позволяет модели улавливать более сложные и нюансированные особенности стиля.
Чем ниже ранг, тем быстрее происходит переобучение, что было для меня сюрпризом. Я ожидал, что модели с высоким рангом будут быстрее переобучаться из-за большего количества параметров. На практике оказалось наоборот — высокий ранг позволяет обучаться более «аккуратно», с меньшим риском жесткой фиксации на обучающих примерах.
В итоге я остановился на ранге 64 и эпохе 114, которая дала лучший баланс стилизации без переобучения. Удивительно, но это только примерно треть от всего обучения — более поздние эпохи давали признаки переобучения.
Я проверил эту модель с разными весами (0.8 и 1.2), чтобы убедиться, что LoRA достаточно гибкая и работает предсказуемо при разных значениях. Результаты меня порадовали — даже при весе 0.8 стиль South Park был хорошо узнаваем, а при 1.2 не появлялись артефакты переобучения.
❯ Ключевые уроки из моего эксперимента
Обучение LoRA на стили оказалось гораздо сложнее, чем я предполагал. Вот главные уроки, которые я извлек:
Для стилей нужен гораздо более высокий ранг, чем для персонажей. Если для персонажа часто хватает ранга 4-8, то для стиля лучше ставить 64-128. Это связано с тем, что стиль — это комплексный набор визуальных особенностей, которые затрагивают множество аспектов изображения.
Чем ниже скорость обучения, тем более плавно происходит обучение, хотя и дольше. Для сложных стилей лучше уменьшить скорость в 3-4 раза от рекомендуемой и запастись терпением. Результат того стоит — меньше шансов получить переобученную модель.
Оптимальные эпохи часто находятся примерно в первой трети всего обучения. У меня лучший результат дала эпоха 114 из 255. Не бойтесь останавливать обучение раньше, если видите признаки переобучения.
Никогда (серьезно, НИКОГДА) не тестируйте LoRA на промтах, похожих на те, что были в датасете! Это даст вам ложное представление о качестве модели. Тестировать нужно на новых, совершенно других промтах, чтобы проверить гибкость и универсальность обученной LoRA.
❯ Итоговый результат
Готовую LoRA я опубликовал на Civitai: South Park Style Flux LoRA.
Все примеры и тесты можно посмотреть на доске: Примеры и тесты.
Обучение LoRA на стили оказалось намного сложнее, чем я ожидал, но результат того стоил. Теперь я гораздо лучше понимаю процесс и готов браться за более сложные стили — возможно, даже за тот самый сериал про человека-паука, который изначально меня вдохновил.
А какие LoRA вы обучали? Делитесь своим опытом в комментариях!
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял и удачных генераций.