Новости
47 постов
47 постов

2 поста

8 постов

40 постов

62 поста

12 постов
7 постов

Создана модель Kimi K2.5 (https://huggingface.co/moonshotai/Kimi-K2.5), которая сейчас самая мощная открытая мультимодальная ИИ-модель от Moonshot AI, разработанная как инструмент для реальных задач, начиная от разработки ПО с визуальным вводом до параллельного решения сложных проблем и автоматизации интеллектуальной работы.
В плане кодирования и зрения она является лидером среди open-source по программированию, особенно во фронтенде, так как может создавать интерфейсы и анимации по описанию или на основе изображений/видео. Главной инновацией внутри неё является роевой интеллект (Agent Swarm), благодаря которому модель сама создает и координирует до 100 параллельных агентов-помощников для сложных задач, что ускоряет выполнение до 4.5 раз по сравнению с одним агентом. Что касается офисной работы, то модель автоматизирует комплексные задачи, включающие в себя создание документов, таблиц, презентаций и анализ данных от начала до конца.
В результате модель показывает конкурентоспособные или лидирующие результаты в ключевых тестах на работу агентов (HLE - 50.2, BrowseComp - 74.9), программирование (SWE-Bench - 76.8), а также обработку изображений и видео (MMMU Pro - 78.5, MathVision - 84.2, VideoMMMU - 86.6).

Загружена модель DeepSeek-OCR 2 (https://huggingface.co/deepseek-ai/DeepSeek-OCR-2) с новой архитектурой визуального кодировщика.
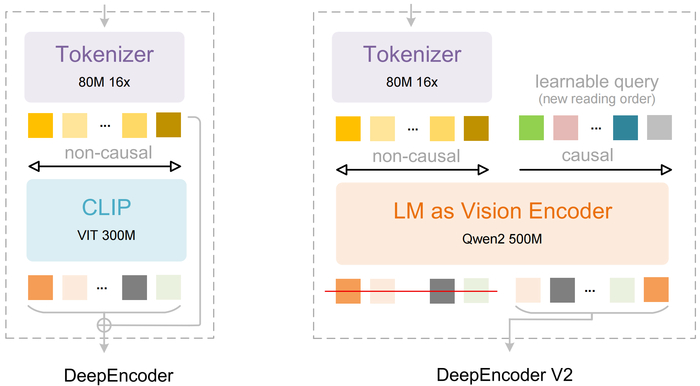
Главная идея разработки состоит в том, что традиционные модели обрабатывают изображение строго по порядку пикселей (слева направо, сверху вниз), что противоречит человеческому восприятию, где взгляд движется по смысловым связям.
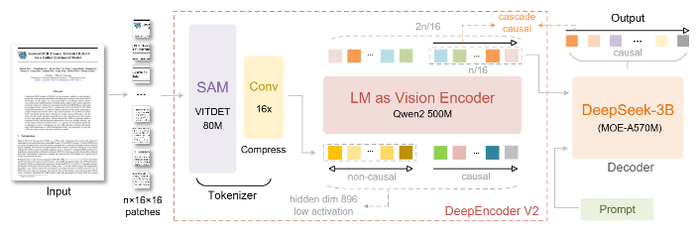
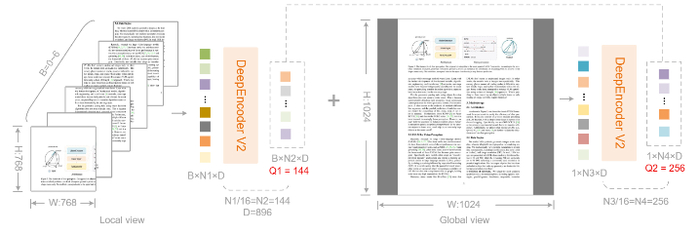
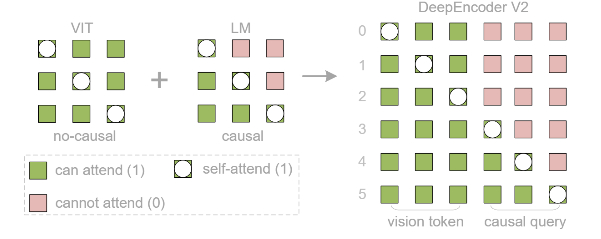
Для решения этой проблемы создан DeepEncoder V2, заменяющий стандартный визуальный кодировщик (CLIP) на архитектуру, похожую на языковую модель (LLM). Он использует "причинно-следственные" обучаемые запросы, которые динамически переупорядочивают визуальные токены на основе семантики изображения, прежде чем передать их в LLM. Кроме того, применяется реализация через комбинированную маску внимания, которая сочетает двунаправленность для визуальных токенов (как в ViT) с причинно-следственной логикой для запросов (как в декодере LLM).
В результате модель имитирует логичный, "причинный" поток человеческого визуального восприятия, особенно для документов со сложной структурой (текст, формулы, таблицы).
Модель сохраняет высокую степень сжатия визуальных токенов (256-1120 на изображение), а на тесте OmniDocBench показывает прирост +3.73% по сравнению с предыдущей версией (DeepSeek-OCR) за счёт лучшего определения порядка чтения.
Представим, что у нас есть вопрос по тексту произведения "Ревизор".

Мы даём текстовой нейросети только этот вопрос, и сразу начинаем играть в "рулетку". Если эту модель обучили на всём тексте произведения, на множестве качественных конспектов, пересказов, статей и обсуждений, то она, скорее всего, выдаст правильный ответ. Если же модель только частично узнала о существовании такого произведения во время обучения, то мы уже можем быть уверены в правильности ответа только на 50 процентов, а то и меньше, ведь, может быть, те данные, которые она знает, помогут ей ответить на вопрос, а могут и не помочь, и в итоге модель может создать сборную солянку текста, в котором будут одновременно полностью правильные факты и полнейшая ложь с дичью. Ну а самый худший вариант будет, если модель знать не знает, что вообще это за произведение, и начнёт пороть откровенную чушь (галлюцинировать), подкрепляя её полностью выдуманными фактами и цитатами.
Задача всех LLM заключается в том, чтобы предсказать следующий токен в текстовой последовательности. Они не "понимают" смысл так же, как мы, а вычисляют наиболее вероятное продолжение текста на основе статистических закономерностей, выученных на огромных наборах данных. При генерации текста для выполнения любой задачи всё сводится к многократному процессу, где в начале мы даём промт модели, она предсказывает следующий токен, который добавляется к контексту, а дальше это повторяется до момента генерации останавливающего токена. А во время предсказания того самого токена модель выдаёт не один "правильный" ответ, а наиболее вероятные варианты, что даёт некую вариативность, ну и, конечно же, возможные ошибки. Если информации в промте и контексте не хватает, модель, вместо того чтобы остановиться, всегда продолжает работать. Она опирается на свои знания, которые были заложены в неё во время обучения, и пытается заполнить пробелы. Для неё важнее, чтобы текст был логичным и связным, чем чтобы он был правдой.
Поэтому глупо испытывать судьбу в надежде получить правильный ответ, когда можно хотя бы минимально потрудиться и дать текстовой нейросети информацию, которая поможет ей для ответа. Любые нейросети нужно использовать как ИНСТРУМЕНТ, а не как мифическую кнопку "Сделать красиво".
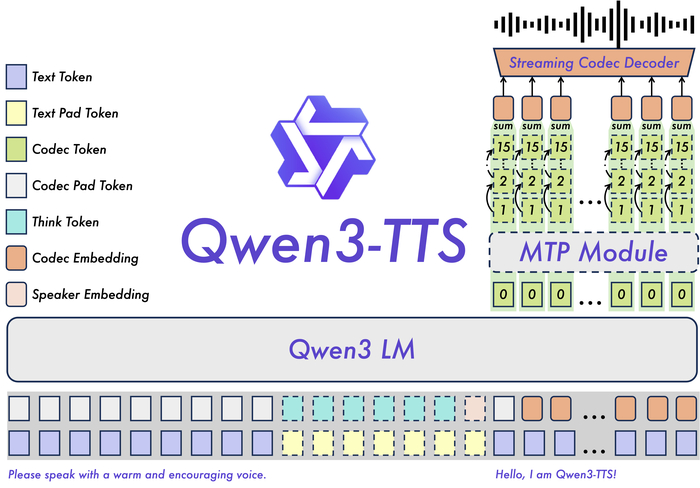
Нам теперь открыта серия мощных моделей генерации речи Qwen3-TTS (https://huggingface.co/collections/Qwen/qwen3-tts). Она доступна в двух размерах (1.7B и 0.6B) и поддерживает 10 основных языков.
У этой модели есть возможность клонирования голоса по 3-секундному образцу, а также создание нового голоса по текстовому описанию. Ещё она поддерживает детальное управление характеристиками речи (тембр, эмоции, интонация) через инструкции. При всём этом у неё сверхнизкая задержка при потоковой генерации.


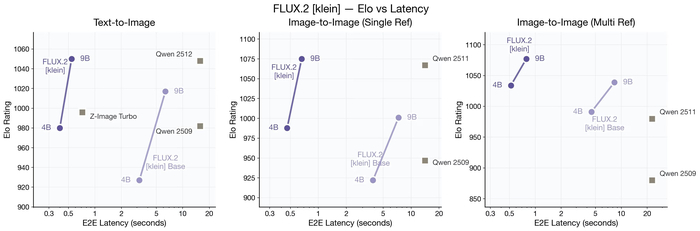
Опубликовали новое семейство моделей FLUX.2 [klein] (https://huggingface.co/black-forest-labs/FLUX.2-klein-9B), которые самые быстрые и компактные для генерации и редактирования изображений, давая высочайшее качество с выводом < 1 сек., и они работают на потребительском железе (от ~ 13 ГБ VRAM).
Их скорость генерации/редактирования <0.5 сек., а универсальность им обеспечивает единая модель для T2I, I2I, multi-reference.
В плане доступности 4B модель предоставляется с Apache 2.0 для локального запуска (RTX 3090/4070). В свою очередь 9B модель выложена с лицензией FLUX NCL.
По качеству модели соответствуют или превосходят модели в 5 раз больше.
Есть несколько вариантов моделей, и первые из них FLUX.2 [klein] 9B/4B (дистиллированные), нужные для быстрого вывода. Потом идут полноценные модели FLUX.2 [klein] Base 9B/4B, предназначенные для тонкой настройки и исследований. А в конце находятся квантованные версии (FP8/NVFP4), созданные совместно с NVIDIA для ещё большей скорости и экономии VRAM.



Здесь у нас серия открытых моделей для машинного перевода на основе Gemma 3, называющаяся TranslateGemma (https://huggingface.co/collections/google/translategemma), которые специально дообучены для перевода, показывая значительное улучшение качества.
Чтобы дообучить модели первым делом использовали метод контролируемого обучения (SFT) на смеси синтетических (сгенерированных Gemini) и человеческих параллельных текстов (+30% общих инструкций). Вторым этапом шло обучение с подкреплением (RL), где для оптимизации качества использовали объединение reward-моделей (MetricX-QE, AutoMQM, ChrF и другие).
Во время сбора данных охватили множество языков, включая низкоресурсные, сочетая синтетические (Gemini + MADLAD-400) и человеческие (SMOL, GATITOS) данные.
В результате на автооценке (WMT24++, 55 языков) TranslateGemma стабильно превосходит базовую Gemma 3 по MetricX и COMET22 во всех размерах (4B, 12B, 27B), причём меньшие модели часто сравнимы с большими базовыми. По задачам перевода изображений (Vistra) модели сохранили мультимодальность Gemma 3 и качество перевода текста на изображениях также улучшилось. Что касается человеческой оценки (WMT25, 10 языков), то она подтвердила улучшения, особенно для низкоресурсных языков, за исключением пары с японского на английский (регресс из-за ошибок в именах собственных).
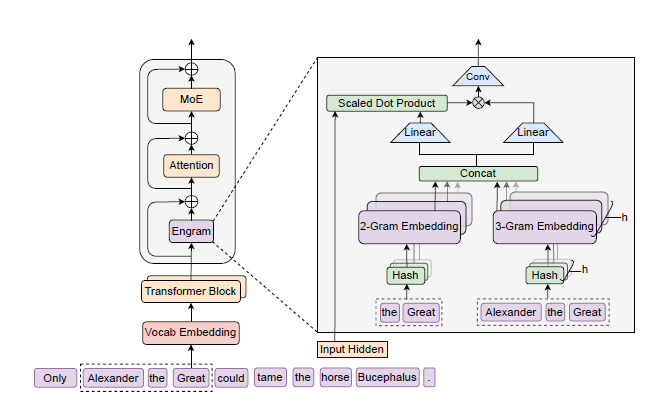
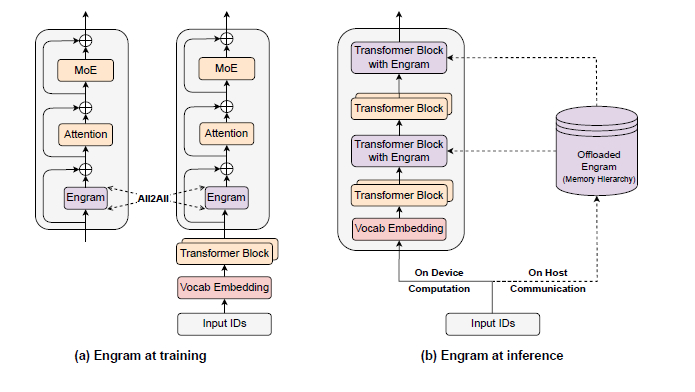
В DeepSeek взялись за проблему, суть которой в том, что трансформеры не имеют встроенного механизма поиска знаний, тратя вычислительные слои на реконструкцию статической информации.
В качестве решения они предложили условную память как новую ось разреженности, дополняющую условные вычисления (MoE). Реализуя её в модуле Engram (https://github.com/deepseek-ai/Engram), который обеспечивает O(1)-поиск статических паттернов через хешированные N-граммные эмбеддинги.
С его помощью модель рациональней использует MoE, где оптимальное распределение параметров между архитектурами следует U-образному закону, улучшая общую эффективность. Поэтому Engram-27B превосходит iso-параметричный и iso-FLOPs MoE-базлайн не только в задачах на знания, таких как MMLU и CMMLU, но и в рассуждениях (BBH, ARC), коде (HumanEval) и математике (MATH).
Всё это работает за счёт освобождения ранних слоёв модели от запоминания статики, умереннее увеличивая глубину сети для сложных рассуждений и освобождая внимание для работы с длинным контекстом и благодаря этому улучшая результаты в бенчмарке RULER. В плане эффективности можно сказать, что детерминированный доступ к памяти позволяет выполнять её разгрузку на хост с предвыборкой, и это даёт ничтожные накладные расходы при выводе, составляющие менее 3%.


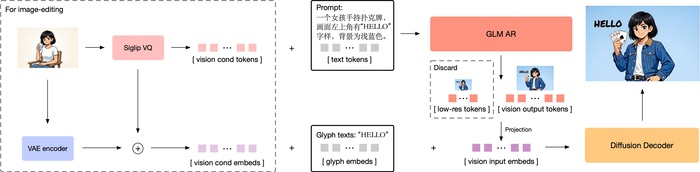
Выложена авторегрессионная модель для генерации изображений, насыщенных знаниями, с высокой точностью GLM-Image (https://huggingface.co/zai-org/GLM-Image).
Она первая открытая промышленная модель, сочетающая авторегрессионный трансформер (9B параметров, на основе GLM-4) для понимания семантики и диффузионный декодер (7B параметров, DiT) для детализации.
Использование гибридной архитектуры обеспечивает ей преимущество в сложных задачах, давая лучшее следование инструкциям, рендеринг текста и работу со знаниями, а ещё высокую детализацию. Кроме того, есть поддержка множества задач, таких как Text-to-Image, редактирование, стилизация, сохранение идентичности.
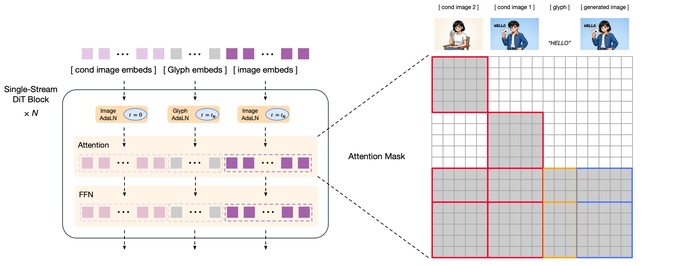
При токенизации в ней используется semantic-VQ (XOmni) для лучшей семантической связи токенов. Обучение AR-части включало многоэтапное обучение на разных разрешениях с прогрессивной стратегией генерации. Диффузионный декодер выполнял условную генерацию на основе семантических токенов, где для работы с текстом и редактирования добавлены glyph-эмбеддинги и блок-каузальное внимание. Также во время post-training проводили раздельную оптимизацию AR-модуля (семантика, эстетика) и декодера (детали, текст) с помощью GRPO.
В результате модель лидирует по рендерингу текста (CVTG-2k, LongText-Bench) и конкурентоспособна в общих задачах (OneIG, DPG Bench, TIFF Bench).