Вышла новая модель для оцифровки изображений DeepSeek-OCR-2
Загружена модель DeepSeek-OCR 2 (https://huggingface.co/deepseek-ai/DeepSeek-OCR-2) с новой архитектурой визуального кодировщика.
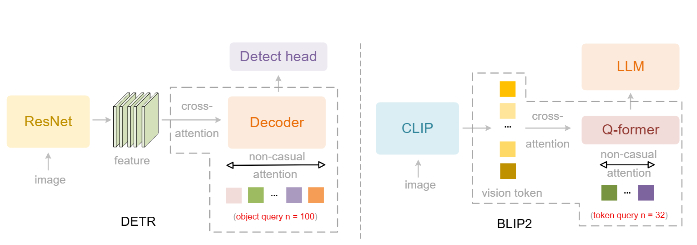
Главная идея разработки состоит в том, что традиционные модели обрабатывают изображение строго по порядку пикселей (слева направо, сверху вниз), что противоречит человеческому восприятию, где взгляд движется по смысловым связям.
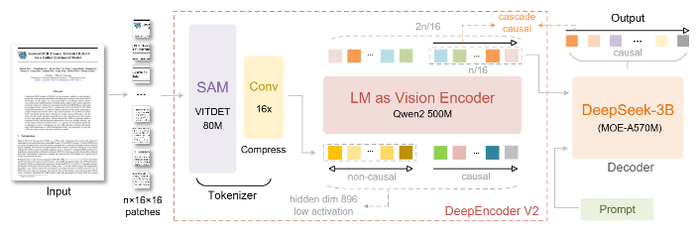
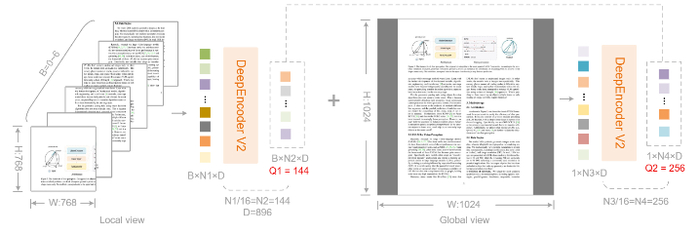
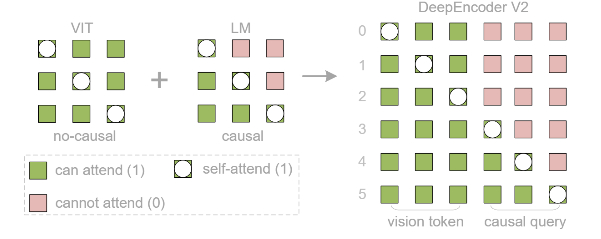
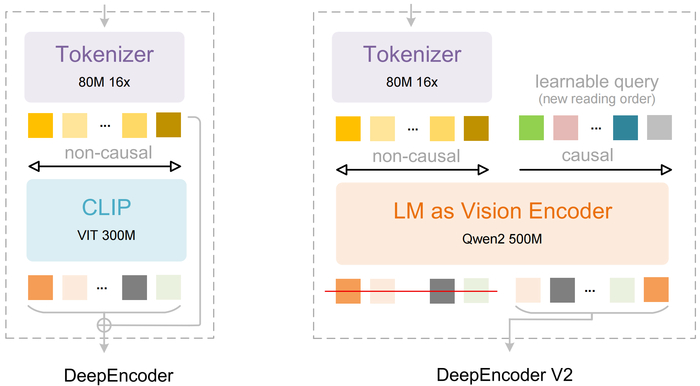
Для решения этой проблемы создан DeepEncoder V2, заменяющий стандартный визуальный кодировщик (CLIP) на архитектуру, похожую на языковую модель (LLM). Он использует "причинно-следственные" обучаемые запросы, которые динамически переупорядочивают визуальные токены на основе семантики изображения, прежде чем передать их в LLM. Кроме того, применяется реализация через комбинированную маску внимания, которая сочетает двунаправленность для визуальных токенов (как в ViT) с причинно-следственной логикой для запросов (как в декодере LLM).
В результате модель имитирует логичный, "причинный" поток человеческого визуального восприятия, особенно для документов со сложной структурой (текст, формулы, таблицы).
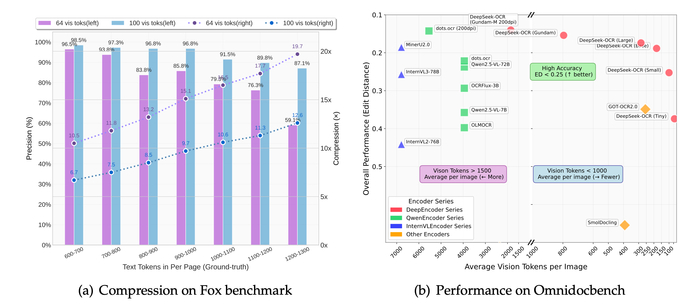
Модель сохраняет высокую степень сжатия визуальных токенов (256-1120 на изображение), а на тесте OmniDocBench показывает прирост +3.73% по сравнению с предыдущей версией (DeepSeek-OCR) за счёт лучшего определения порядка чтения.