Записывал песню на диктофон в телефоне, а он у меня типа умный, делает краткое содержание, но язык при этом нужно выбирать вручную, а тот стоял на русском. И так, дамы и господа, краткое содержание песни Teddy Swims - Lose Control, по мнению моего диктофона:
И сам текст песни
Как он из этого то содержание сделал, я хз)
Текст песни : Something's got a hold of me lately No, I don’t know myself anymore Feels like the walls are all closin' in And the devil's knockin’ at my door, woah Out of my mind, how many times did I tell you I'm no good at bein' alone? Yeah, it's taken a toll on me, tryin' my best to keep From tearin' the skin off my bones, don't you know
[Chorus] I lose control When you're not next to me (When you’re not here with me) I’m fallin' apart right in front of you, can’t you see? I lose control When you're not next to me, mhm Yeah, you're breakin' my heart, baby You make a mess of me
На подходе очередной гаджет, стартап Sandbar и их кольцо Stream. Производитель называет его «голосовой мышью». С помощью этого кольца можно делать голосовые заметки, общаться с ИИ-помощником и листать треки, не роясь в карманах. Микрофоны в нем по умолчанию выключены - они просыпаются только когда вы касаетесь сенсорной панели. То есть можно вслух наговорить свои внезапные мысли и сразу их сохранить. Потом всё это великолепие можно в приложении расшифровать в текст, а в будущем - еще и выгрузить прямиком в Notion. Внутри еще живет чат-бот, с которым можно поболтать голосом.
Серебряная версия обойдется в $249 или примерно 20,1 тысячу рублей, а золотая - уже в $299, то есть около 24,1 тысячи. И куда же сейчас без подписки! За $10 (примерно 808 рублей) в месяц вам откроют безлимит для заметок и чатов, а также доступ к новым функциям. В общем, если часто генерируете идеи и не боитесь разговаривать с рукой - возможно, это ваш вариант.
Яндекс представил компактный диктофон с Алисой Про, ориентированный на корпоративный сектор.
Диктофон маленький и лёгкий, по размеру сопоставим с пластиковой картой, управляется переключателем и кнопкой, оснащён индикатором записи.
Устройство позволяет записывать всё самое важное, от лекций и совещаний до заметок вслух для самого себя. Алиса Про расшифровывает записи, выделяет ключевые тезисы и извлекает нужные факты из архива.
Все записи в памяти защищены аппаратным шифрованием. Ключ хранится на смартфоне пользователя. Даже если диктофон утерян, данные будут в безопасности.
Диктофон — собственная разработка Яндекса; его будет производить Яндекс Фабрика.
Продажи начнутся в первой половине 2026 года, тогда же будут раскрыты и другие подробности о новом продукте.
Часто встречаются видео или примеры проектов, где используют транзисторы серий BC547, BC546 и т.д. для каких либо самоделок и начинающих радиолюбителей отпугивает поиск аналогов и тратиться не охота. Такие транзисторы вряд ли вам будут встречаться в старой радиоаппаратуре, чаще всего вы встретите там транзисторы 9014 или 8050 один из них и будем использовать, а так же будем использовать всё, что завалялось дома, например адаптер SD карты под Micro SD и микрофон из сломанного планшета. Из всего этого начинающие радиолюбители и не только, могут собрать минималистичный, рабочий, максимально простой предусилитель на одном транзисторе, а так же задействовать его, как рабочее устройство через Arduino Nano с возможностью записи аудио на SD карту. Скачать скетч и другие файлы можно с моего Google диска https://drive.google.com/file/d/1cL2mGv0qy9diJRJkwgeh4W1-lgI...
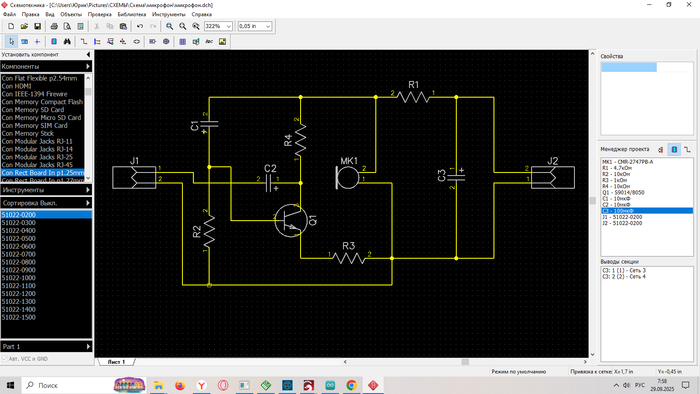
Принципиальная схема предусилителя микрофона. Компоненты и их номиналы указаны в справа, в Менеджере проекта.
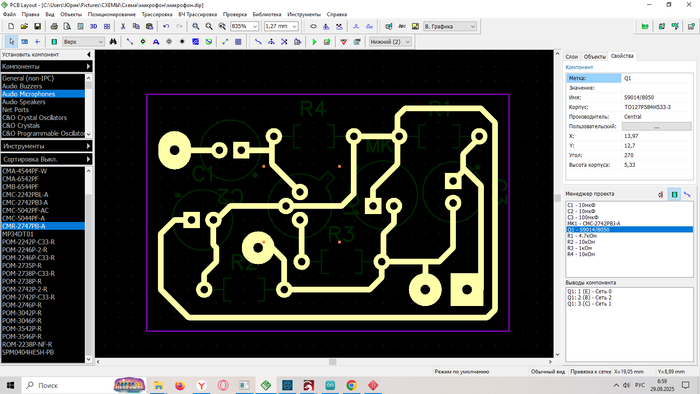
Трассировка дорожек для платы. Квадратные площадки это плюсовые соединения, большие круглые, это минус, овальный вывод, это выход сигнала с микрофона.
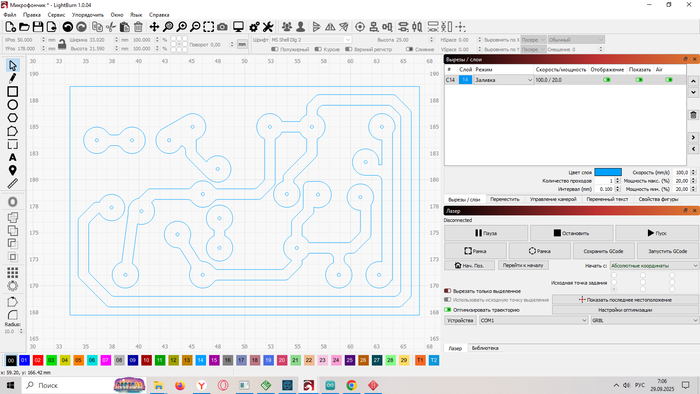
В архиве так же будет лежать файл Light Burn, что бы можно было плату сделать на диодном лазерном станке, дорожки оптимизированы под станок. Для это необходимо покрасить поверхность фольгированного текстолита, высушить, сжечь лазером лишнюю краску, оставив дорожки, сделать травление платы любым доступным способом, смыть краску с дорожек растворителем 646.
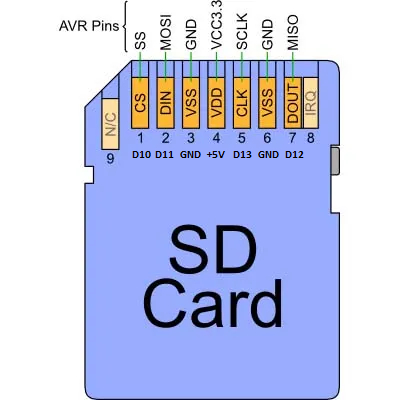
Распиновка SD карты/адаптера для подключения к Arduino. Используются выводы Arduino (D10, D11, GND, 5V, D13, D12)
Сборка предусилителя навесным монтажом, если лень делать плату.
Плата, вид снизу.
Плата, вид сверху.
Распаянный SD адаптер для Arduino.
Подключение предусилителя к Arduino: Минус предусилителя к выводу (GND) Плюс предусилителя к выводу (5V) Выход сигнала предусилителя к выводу (A1) Отдельное питание предусилителя не требуется, питание осуществляется через Arduino.
Подключение кнопки начала/остановки записи к Arduino: Один вывод кнопки к выводу (GND) Второй вывод кнопки к выводу (D2)
Подключение светодиода для индикации записи: Минус (катод) светодиода к выводу (GND) Плюс (анод) светодиода к выводу (D5)
Керамический конденсатор 100нФ параллельно кнопке, опционально (антидребезг кнопки)
Пример записи. Качество конечно так себе, но работает. Запись сохраняется в формате WAV, для прослушивания, возможно понадобятся соответствующие аудиокодеки или можно конвертировать в mp3 через онлайн-сервисы.
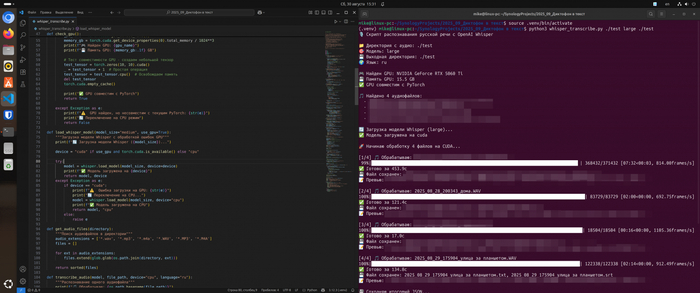
Несколько недель назад я опубликовал статью о том, как превратить обычный диктофон в инструмент для расшифровки речи с помощью OpenAI Whisper. Идея была создать бесплатную и приватную систему ИИ диктофона, которая избавляет от необходимости переслушивать аудиозаписи лекций или выступлений. Тогда статья нашла своего читателя, собрав 16К просмотров и 120 закладок.
ИИ и обычные диктофоны
В процессе настройки я боролся с несовместимостью библиотек, подбирал нужные версии драйверов и вручную собирал рабочее окружение. В комментариях мне справедливо заметили: «Вместо всей этой возни можно было найти готовый Docker-контейнер и поднять всё одной командой». Звучало логично, и я с энтузиазмом принял этот совет. Я ведь верю людям в интернете.
Новая идея - не просто расшифровывать речь, а разделять её по голосам - как на совещании или встрече. Это называется диаризацией, и для неё существует продвинутая версия - WhisperX. Цель была проста - получить на выходе не сплошное полотно текста, а готовый протокол встречи, где понятно, кто и что сказал. Казалось, с Docker это будет легко.
Но я заблуждался. Путь «в одну команду» оказался полон сюрпризов - всё сыпалось одно за другим: то скрипт не видел мои файлы, то не мог получить к ним доступ, то просто зависал без объяснения причин. Внутри этой «волшебной упаковки» царил хаос, и мне приходилось разбираться, почему она не хочет работать.
Но когда я всё починил и заставил систему работать, результат превзошёл мои ожидания. Новейшая модель large-v3 в связке с диаризацией выдала не просто текст, а структурированный диалог.
Это был настолько лучший результат, что я смог передать его большой языковой модели (LLM) и получить глубокий анализ одной очень важной для меня личной ситуации - под таким углом, о котором я сам бы никогда не задумался.
Именно в этот момент мой скепсис в отношении «умных ИИ-диктофонов», которые я критиковал в первой статье, сильно пошатнулся. Скорее всего их сила не в тотальной записи, а в возможности превращать хаос в структурированные данные, готовые для анализа.
В этой статье я хочу поделиться своим опытом прохождения этого квеста, показать, как обойти все скрытые сложности, и дать вам готовые инструкции, чтобы вы тоже могли превращать свои записи в осмысленные диалоги.
В комментариях меня критиковали за то, что я опять написал статью про Linux. Да, у меня на домашнем компьютере стоит Ubuntu в режиме двойной загрузки - и многим непонятно, почему я не сделал всё под Windows. Ответ прост: для задач с нейросетями Linux даёт меньше неожиданностей и больше контроля. Драйверы, контейнеры, права доступа - под Linux их проще исследовать и чинить, особенно когда начинаешь ковырять CUDA и системные зависимости.
Ещё меня критиковали за RTX 5060 Ti 16GB - мол, не у всех такие видеокарты. Согласен, это не смартфон в кармане. Но для работы с большими моделями и диаризацией нужна мощь GPU: я использую её как инструмент. К тому же подходы, которые я описываю, работают и на более скромных конфигурациях - просто медленнее.
А теперь начнём с самого начала - что такое Docker простыми словами? Представьте, что вместо того, чтобы настраивать компьютер под каждую программу, вы берёте готовую «коробку» и в ней уже есть всё: нужные версии Python, библиотеки, утилиты. Эта «коробка» запускается одинаково на любой машине - как виртуальная мини-кухня.
То есть мой план действий был такой:
Установить Docker.
Скачать готовый образ с WhisperX.
Запустить одну команду и получить готовый протокол встречи.
Так что могло пойти не так?
Первое столкновение с реальностью
Уже на первом шаге начались сюрпризы:
Секретный токен, который не дошёл до адресата
Чтобы запустить диаризацию, WhisperX использует модели от pyannote, а они требуют авторизации через токен Hugging Face. Я передал его как переменную окружения Docker (-e HF_TOKEN=...), будучи уверенным, что этого достаточно. Но утилита внутри контейнера ожидала его совсем в другом виде - аргументом командной строки (--hf_token). В итоге модель упорно отказывалась работать, и я долго не понимал, где ошибка.
Война за права доступа
Следующая засада - PermissionError при попытке записи в системные папки /.cache. Контейнер как гость в доме: ему разрешили пользоваться кухонным столом, а он пошёл сверлить стены в гостиной. Разумеется, система его остановила. Решение оказалось простым - создать отдельную «полку» для кеша (~/.whisperx) и явно указать путь.
Загадочное зависание
Запускаешь скрипт - и тишина. Ни ошибок, ни логов, будто процесс замёрз. На деле работа шла, просто механизм вывода в контейнере «затыкался». Решение - добавить индикатор прогресса.
Так что Docker - не магия, а всего лишь ещё один инструмент, который тоже нужно приручить.
Решение: два скрипта
Я написал две утилиты - один раз подготовить систему, второй - управлять обработкой. Это простая, надёжная пара: установщик устраняет системные «подводные камни», оркестратор - закрывает все проблемы запуска (HF-token, кэш, права, прогресс).
Назначение: однократно подготовить Ubuntu - поставить Docker, NVIDIA toolkit, скачать образ WhisperX, создать рабочие папки и общий кэш ~/whisperx. Что делает:
проверяет дистрибутив и наличие GPU (nvidia-smi);
устанавливает Docker и добавляет пользователя в группу docker;
ставит NVIDIA Container Toolkit и настраивает runtime;
Когда все технические баталии были позади, я наконец смог оценить, стоила ли игра свеч. Результат был отличный.
В первой статье обычный Whisper выдавал сплошное текстовое полотно. Информативно, но безжизненно. Вы не знали, где заканчивается мысль одного человека и начинается реплика другого.
Было (обычный Whisper):
...да, я согласен с этим подходом но нужно учесть риски которые мы не обсудили например финансовую сторону вопроса и как это повлияет на сроки я думаю нам стоит вернуться к этому на следующей неделе...
Стало (WhisperX с диаризацией):
[00:01:15.520 --> 00:01:19.880] SPEAKER_01: Да, я согласен с этим подходом, но нужно учесть риски, которые мы не обсудили. [00:01:20.100 --> 00:01:22.740] SPEAKER_02: Например, финансовую сторону вопроса и как это повлияет на сроки? [00:01:23.020 --> 00:01:25.900] SPEAKER_01: Именно. Я думаю, нам стоит вернуться к этому на следующей неделе.
WhisperX с диаризацией превращает этот монолит в сценарий пьесы. Каждый спикер получает свой идентификатор, а его реплики - точные временные метки. Разница колоссальная. Теперь это не просто расшифровка, а полноценный протокол.
Мой личный кейс
Но настоящая магия началась, когда я решил пойти дальше. Я взял расшифровку одного личного разговора, сохранённую в таком структурированном виде, и загрузил её в нейросеть бесплатную нейросеть от гугла Gemini 2.5 Pro с простым запросом: «Действуй как аналитик. Проанализируй этот диалог».
Именно из-за структуры Gemini смогла отследить, кто инициировал темы, кто чаще соглашался или перебивал, как менялась тональность и динамика беседы. В итоге я получил анализ скрытых паттернов в общении, о которых сам никогда бы не задумался. Это был взгляд на ситуацию с абсолютно неожиданной стороны, который помог мне лучше понять и себя, и собеседника.
Даже бесплатное приложение в телефоне может служить источником
Я понял, что их главная ценность «ИИ-диктофонов» - не в способности записывать каждый ваш шаг, а в умении превращать хаос человеческого общения в структурированные, машиночитаемые данные. Это открывает возможности: от создания кратких сводок по итогам встреч до глубокого анализа коммуникаций, который раньше был невозможен.
Заключение
В итоге путь от «просто используй Docker» к рабочей связке WhisperX показал очевидную вещь: контейнеры - удобный инструмент, но не магия.
Подготовка системы и правильная оркестровка запуска - это то, что превращает хаос в рабочий процесс. Если вы готовы потерпеть небольшие сложности ради удобства в дальнейшем - результат оправдает усилия: структурированные протоколы и возможность глубокого анализа бесед.
В новостях всё чаще говорят об «ИИ‑диктофонах» — гаджетах, которые записывают каждый ваш разговор в течение дня, отправляют аудио в облако, превращают его в текст и даже готовят краткую сводку по итогам. Звучит футуристично, но такие решения стоят дорого, требуют постоянной подписки и вызывают вопросы о приватности.
Лично мне идея тотальной записи кажется избыточной. Зато куда практичнее другая задача: получить точную текстовую расшифровку лекции, доклада или публичного выступления. Чтобы потом не переслушивать часы аудио, а быстро найти нужную цитату или мысль простым поиском по тексту.
Мой купленный за 2 т.р. диктофон с возможностью подключения внешнего микрофона на фоне коробки с ESP32
В этой статье я покажу, как построить такую систему без платных подписок и полностью под вашим контролем. Всё, что нужно — обычный диктофон за 1–3 тыс. рублей или даже просто приложение на телефоне — тогда затраты вообще равны нулю, и набор бесплатных, открытых программ, которые работают на вашем компьютере. Я купил диктофон для теста и поделюсь результатами.
Сердцем решения станет OpenAI Whisper — мощная технология распознавания речи от создателей ChatGPT. Главное её преимущество — она может работать полностью автономно на вашем ПК, не отправляя никуда ваши данные. К тому же Whisper распространяется как open‑source: исходный код и модели доступны бесплатно — вы можете скачать, использовать и при необходимости даже модифицировать.
За последние пару лет появилось немало open‑source решений для распознавания речи, но именно Whisper стал фактическим стандартом. Его модели обучены на колоссальном массиве данных, что обеспечивает высокую точность распознавания. По сравнению с другими бесплатными движками, Whisper даёт результат ближе всего к коммерческим сервисам вроде Google Speech‑to‑Text и при этом работает автономно. Важный плюс — мультиязычность. Русский язык поддерживается «из коробки».
Модели Whisper бывают разных размеров: от tiny до large. На данный момент наиболее актуальной и точной является large-v3. Главный принцип здесь — компромисс между скоростью, точностью и требуемыми ресурсами (в первую очередь, видеопамятью). У меня видеокарта NVIDIA GeForce RTX 5060 Ti 16 ГБ, поэтому на тестах использую large модель, она требует ~10 ГБ VRAM, но можно начать и со small модели — для неё достаточно ~2 ГБ VRAM.
Не стоит забывать и о приватности: все данные остаются у вас на компьютере. Никаких облачных серверов, никаких подписок. Что понадобится для запуска?
Железо: компьютер с Linux (я использую Ubuntu, но у меня стоит двойная загрузка Windows & Linux через rEFInd Boot Manager). Рекомендуется видеокарта NVIDIA — GPU многократно ускоряет работу, хотя на CPU тоже всё запустится, только медленнее. В качестве источника звука я тестировал обычный диктофон за пару тысяч рублей.
Диктофон за 1–3 тыс. рублей. Много их
Софт:
Python — язык, на котором работает весь стек.
FFmpeg — универсальный конвертер аудио/видео.
PyTorch — фреймворк, на котором обучены модели.
NVIDIA Drivers и CUDA — для связи с видеокартой.
Практическая часть: пошаговая инструкция
Теперь перейдём от теории к практике и соберём рабочую систему распознавания. Я разбил процесс на несколько шагов — так будет проще повторить.
Чтобы избавить вас от всего этого «удовольствия», я написал универсальный bash‑скрипт setup_whisper.sh. Он берёт на себя всю грязную работу по настройке окружения на Ubuntu 24:
обновляет систему и ставит базовые пакеты, включая Python и FFmpeg;
проверяет драйверы NVIDIA и при необходимости устанавливает их;
подтягивает CUDA Toolkit;
создаёт виртуальное окружение Python и внутри него ставит PyTorch (учитывая модель видеокарты);
загружает сам Whisper и полезные библиотеки;
запускает тест, проверяющий, что GPU действительно работает.
Чем лучше исходная запись, тем меньше ошибок. Записывайте ближе к источнику звука, избегайте шумных помещений и треска. Whisper работает с самыми популярными форматами: mp3, wav, m4a, так что конвертировать вручную не придётся.
После обработки вы получите полный набор файлов. Например:
some_lecture.txt — текст лекции;
some_lecture.srt — субтитры вида:
12 00:04:22,500 --> 00:04:26,200 Здесь спикер рассказывает о ключевой идее...
all_transcripts.txt — всё сразу в одном документе.
Я проверил систему на часовом файле. Модель large на моей RTX 5060 Ti справилась за ~8 минут.
Разделение по спикерам (диаризация) - почему это сложно?
А если записывать не лекцию, а совещание? На записи говорят пять человек, и вам нужно понять, кто именно что сказал. Обычный Whisper выдаёт сплошной текст без указания человека. Здесь на помощь приходит диаризация — технология, которая анализирует голосовые характеристики и помечает фрагменты как «Спикер 1», «Спикер 2» и так далее.
Для этого существует WhisperX — расширенная версия Whisper с поддержкой диаризации. Однако при попытке установки я опять столкнулся с классической проблемой ML‑экосистемы: конфликтом зависимостей. WhisperX требует определённые версии torchaudio, которые несовместимы с новыми драйверами NVIDIA для RTX 5060 Ti.
Решение мне подсказали: Docker‑контейнеры NVIDIA. По сути, это готовые «коробки» с предустановленным софтом для машинного обучения — разработчики уже решили все проблемы совместимости за вас. NVIDIA поддерживает целую экосистему таких контейнеров через NGC (NVIDIA GPU Cloud), а сообщество создает специализированные образы под конкретные задачи. Вместо многочасовой борьбы с зависимостями достаточно одной команды docker pull, и вы получаете полностью рабочую среду с предустановленным WhisperX, настроенным PyTorch и всеми библиотеками. В данном случае контейнер ghcr.io/jim60105/whisperx включает диаризацию из коробки и отлично работает с современными GPU.
Диаризация откроет новые возможности: автоматическую генерацию протоколов встреч с указанием авторства реплик, анализ активности участников дискуссий, создание интерактивных расшифровок с навигацией по спикерам.
Это тема для отдельной статьи, которую планирую выпустить после тестирования Docker‑решения на реальных многоголосых записях.
Заключение
Мы собрали систему, которая позволяет бесплатно и полностью автономно расшифровывать лекции, выступления, а в перспективе и совещания. В основе — OpenAI Whisper, а все настройки и запуск упрощают мои open source скрипты. Достаточно один раз подготовить окружение — и дальше вы сможете регулярно получать точные транскрипты без подписок и риска приватности.
Следующий шаг — диаризация. Это позволит автоматически разделять текст по спикерам и превращать расшифровку совещания в полноценный протокол с указанием авторства.
ИИ-диктофоны - это специальные устройства, автоматически записывающих и анализирующих разговоры. Они выпускаются в различных видах — браслеты, кулоны, заколки. И продаются по цене от $99 до $199, ещё и с годовой подпиской от $50 до $168.
Эти устройства поддерживают множество языков, создают расшифровки и краткие сводки с возможностью полнотекстового поиска.
Вот примеры использования:
Основатель стартапа Buddi Анит Патель: "Когда на встрече больше десяти человек, сложно всё удержать в голове. Лучше записать".
Руководитель Accelr8 Пэт Сантьяго: "ИИ замечает детали, ускользающие от человеческого внимания".
Директор компании Mostly Serious Джарад Джонсон: "Есть тенденция к корпоративным закупкам этих устройств для целых отделов, особенно в сфере продаж".
Почему-то есть у меня устойчивое мнение, что это всё просто очередные понты 😎.