Изучаем основы Regex. Применяем Regex в Java. Заключительная часть

В предыщущей статье мы ознакомились с базовыми элементами. в этой части мы рассмотрим более сложные примеры. И затем, применим эти знания для реальных задач.
Квантифаеры (Quantifier) + * ?
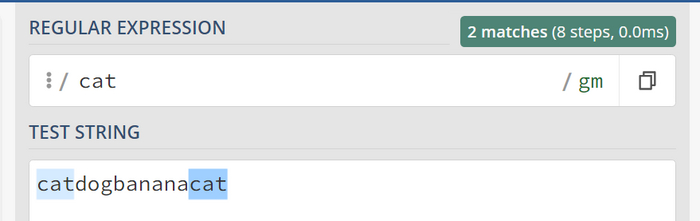
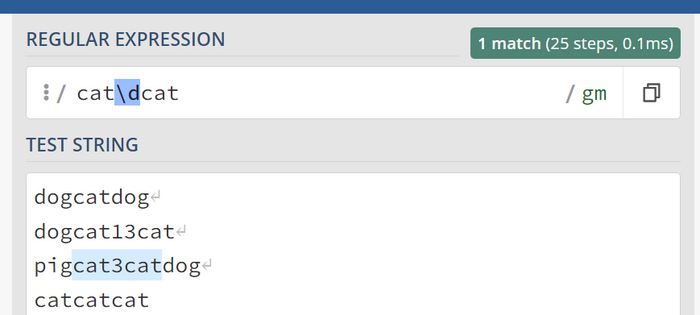
Предположим, в нашем выражении один из символов может быть опциональным или повторяться несколько раз. Например, мы ищем слово cat, которое может начинаться с "ca", но последующий символ "t" может быть опциональным или повторяющимся. Здесь у нас есть несколько вариантов в зависимости от наших требований:
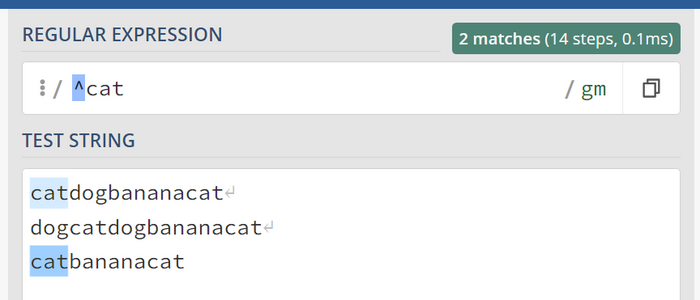
Символ вопроса ? или {0,1}
Симол t может отсутсвовать или присутствовать в рамках символа { } это { 0 , 1 }.
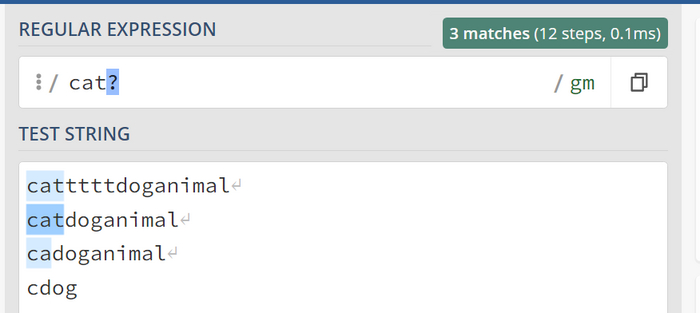
Как видно первые три варианта совпали но мы не задели больше одного символа t. Мы бы достигли такого же результата через cat{0,1}
DOS атаки вошли в чат. Catastrophic Backtracking (Катастрофический возврат)
Далее переходим к выражениям, неоптимальность которых может стать уязвимостью для атак типа DOS (Denial of Service - отказ в обслуживании) а точнее RegexDOS или ReDOS. Неоптимальные и сложные регулярные выражения могут потребовать экспоненциальной сложности для их обработки. Злоумышленник, зная об этом, может заспамить нас строками, которые быстро истощат наши процессорные ресурсы. Более подробную информацию по этой теме можно найти здесь. В качестве примера рассмотрим следующий запрос:

Regex101 достаточно умен чтобы даже не пытаться его запустить, он аналитически предотвратил запуска поиска.
Не стоит паниковать, так как регулярные выражения позволяют нам написать защищенные от атак типа DOS выражения.
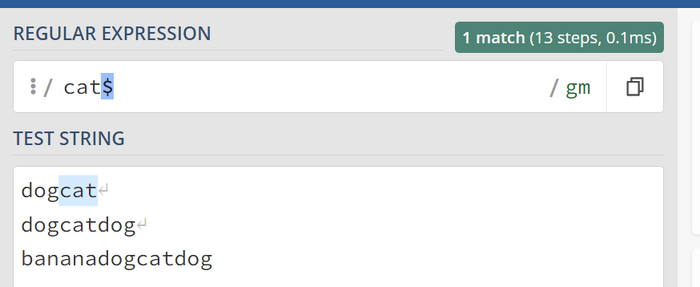
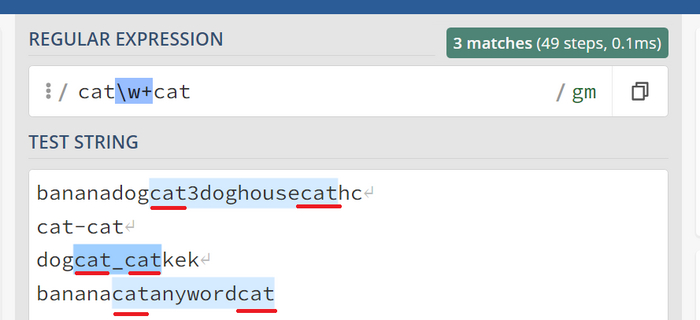
Символ плюса + или {1, } (от 1 до бесконечности)
Предположим, что символ "t" должен присутствовать, и при этом мы допускаем его повторение. Это эквивалентно записи {1,} (от 1 до бесконечности). Для этого используем символ "+":
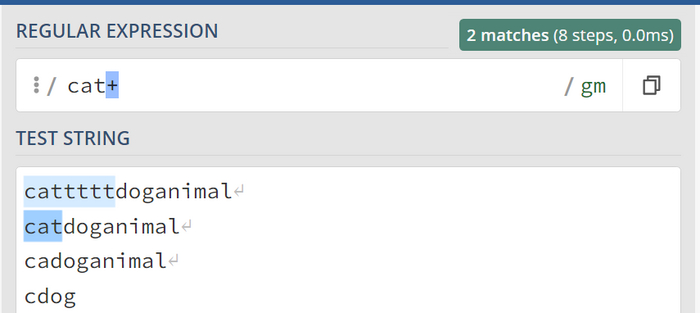
t элемент должен обязательно присутствовать.
Символ звездочки * или {0, } (те от 0 до бесконечности)
В последнем варианте предположим, что символ "t" может быть не включен, и при этом может иметь бесконечное количество повторений. То есть это эквивалентно записи {0,} или от 0 до бесконечности:
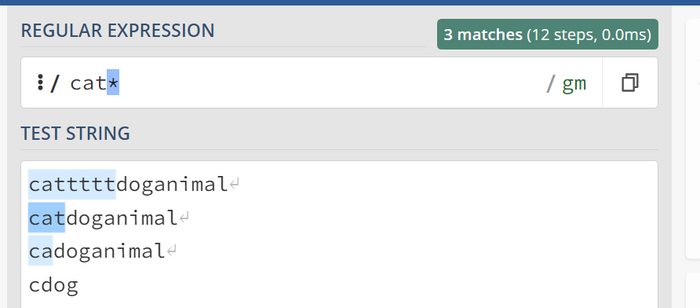
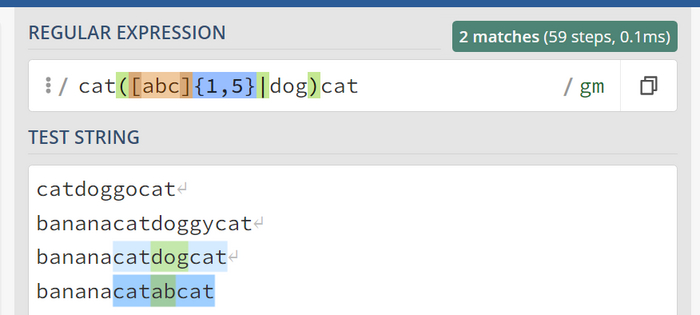
Сравним каждый из квантифаеров
Пересмотрим еще раз каждый из них и эквивалентное к ним { }:
? эквивалентна { 0 , 1 }
* эквивалентна { 0, }
+ эквивалентна { 1, }
Cимволы \w \d \s и их отрицания \W \D \S
Некоторые из этих символов я уже упомянул в первой статье, но давайте повторим и добавим немного новых:
\w - любый алфавитный символ (a-z,A-Z) и цифры 0-9 и подчеркивание _
\d - цифры 0-9
\s - символ пробелов такие как - пробелы, табы, переносы строк итд
В regex есть удобная функциональность инверсии выражений. Например если вместо \d мы напишем \D то выражение будет искать все символы исключая цифры.
Также для инверсии любого общего выражения можно достичь символом ^ но указав его внутри скобок. Например любой символ кроме a-b: [^a-b]
Группировка.
Группировка - важная функциональность регулярных выражений, которая позволяет:
Составлять более сложные запросы.
Извлекать данные из выражений.
Чтобы выделить выражение в группу, нужно обернуть его в скобки ( ). Рассмотрим ситуацию, где у нас есть записи о животных в формате "название животного дата рождения цвет" (разделенных пробелом). Давайте напишем выражение для извлечения только кошек (любого года рождения и цвета), выделив цвет и год рождения в группу:
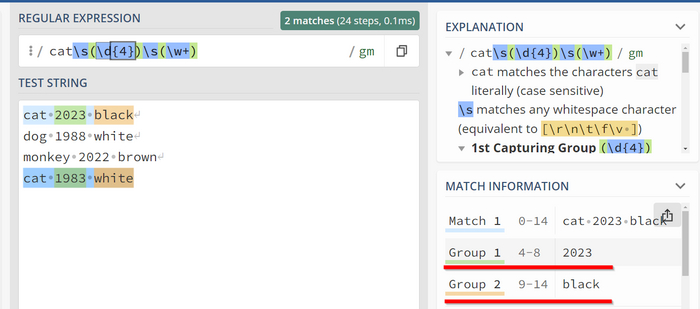
И так мы получили 2 результата и как вы можете видеть справа мы получили две группы Group 1 и Group 2.
Group 1 и Group 2 совпадают с нашими ожиданиями, но могут быть неудобными для чтения. Давайте воспользуемся еще одной возможностью и дадим им ярлыки. Для этого, внутри круглых скобок, нужно в самом начале добавить "?<label>", где "label" - это название группы. Например:
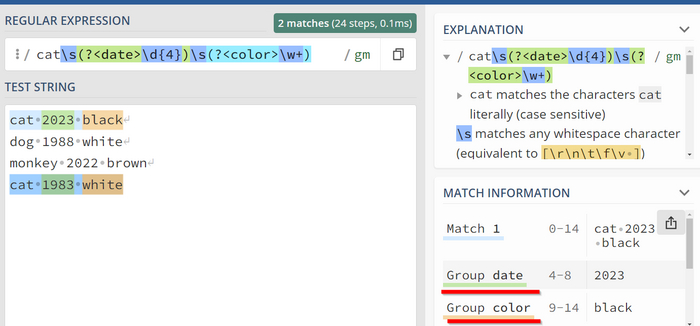
Справа снизу видно что наши группы теперь имеют человеческий вид - date, color.
Применение регулярных выражений для промышленной задачи.
Итак, у нас перед нами задача: мы получили записи из ветклиники и хотим отфильтровать только валидные записи, а затем извлечь их для последующей аналитики.
Анализ входных данных
Теперь, когда у нас есть данные, нам нужно решить:
Какие данные считаются корректными?
Какие "отклонения" мы можем допустить?
Обычно ответы на эти вопросы предоставляются аналитиком, но в данном случае мы выполним все шаги самостоятельно. Итак, рассмотрим данные:

не стоит обращать внимание на хомяков весом почти в 1кг)
Из данных можно сделать вывод:
Первые цифры определяют год, просто 4 фиксированные цифры.
Данные разделены ";" (точкой с запятой) с потенциальными смежными пробелами.
Последняя колонка с весом - это число с плавающей точкой.
Напишем выражение для каждой из групп
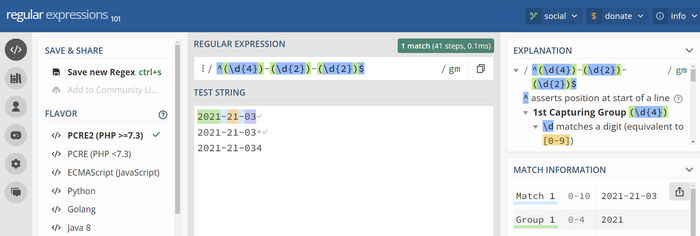
дата (?<date>\d{4}) - ровно 4 цифры
имя (?<name>[a-zA-Z]+) слово длины от 1 до бесконечности состоящие из букв алфавита
животное (?<animal>(dog|cat|snake)) - лишь 3 вида допустимых животных собака, кошка, змея написанные строчными буквами
вес (?<weight>\d+\.\d+) - два числа длины минимум 1 и до бесконечности, разделенные точкой
между разделителями есть пробелы \s* (от нуля до бесконечности)
Итак, полученное выражение:
Предположим, что по требованиям нам нужно анализировать только собак, кошек и змей. Тогда наше конечное выражение будет выглядеть вот так:
(?<date>\d{4})\s*;\s*(?<name>[a-zA-Z]+)\s*;\s*(?<animal>dog|cat|snake)\s*;\s*(?<weight>\d+\.\d+)
Это регулярное выражение соответствует вашим требованиям для анализа записей о собаках, кошках и змеях. Оно разделяет данные на четыре группы: год, имя, вид животного и вес. Теперь проверим это выражение на наших данных:
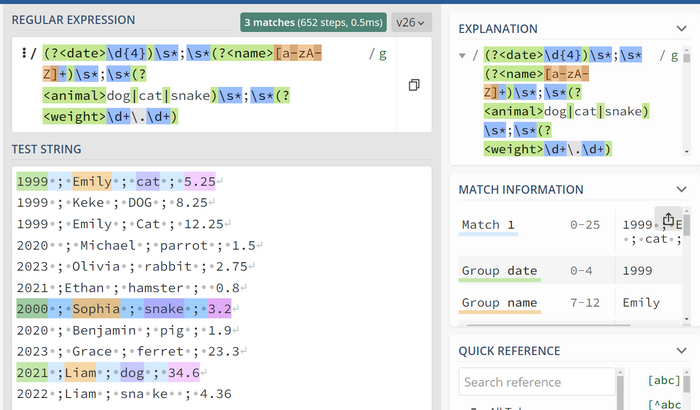
можно заметить что группы совпадают с ожидаемыми значениями
Как мы могли бы улучшить запрос?
Наш первый вариант был слишком "жестким", и мы не предполагали, что животное может иметь заглавную букву. Давайте это поправим:
Добавить ?i что даст нам (?i:(?<animal>dog|cat|snake)) чтобы не учитывать регистр животного
Защита от DOS атак.
Чтобы предотвратить возможность перегрузки системы, уберем использование *, + и укажем максимальный допустимый размер, используя {}.
После всех преобразований получаем:
(?<date>\d{4})\s{0,2};\s{0,2}(?<name>[a-zA-Z]{1,15})\s{0,2};\s{0,2}(?i:(?<animal>dog|cat|snake))\s{0,2};\s{0,2}(?<weight>\d{1,10}\.\d{1,5})
У нас получился классический нечитаемый регекс))

Новое выражение теперь учитывает и DOG и Cat благодаря ?i:. Все предыдущие записи были также включены, хотя все *, + были исключены из выражений.
Воспользуемые полученным выражением в Java.
Цель - отфильтровать все валидные записи и привести к типам Javav. Я не планировал сильно погружаться в детали реализации Regex классов в Java, поэтому ниже просто покажу рабочее решение:
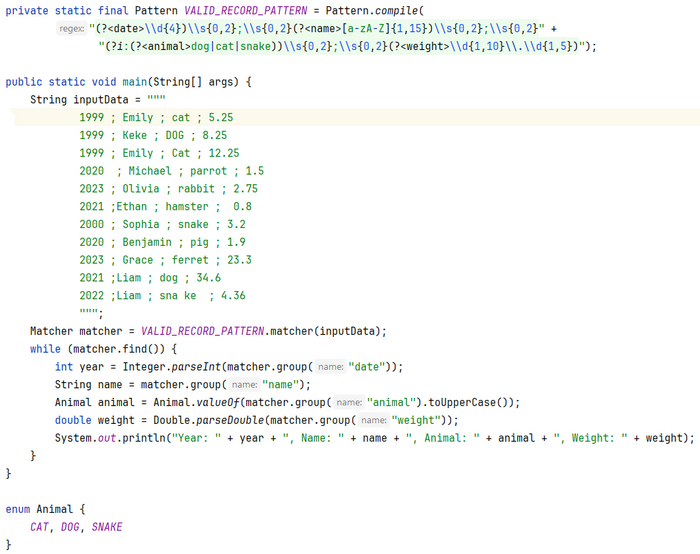
Код далек от идеала но достаточно прост для понимания.
Pattern, Matcher - классы для работы с Regex в Java.
В коде мы создаем объект класса Pattern и затем создаем Matcher на его основе. Класс Matcher позволяет обойти всe валидныe записи которые формирует наш Regex запрос используя метод matcher.find(). И затем вытаскиваем значения групп используя метод group("имя группы"). Результатом работы будет

И последнее. Полученные результаты совпадают с regex101.com, но нужно помнить, что у Java есть свои аспекты поддержки Regex, которые в редких случаях потребуют небольших изменений в регулярном выражении.
На этом рассказ про regex заканчивается, вот материалы. Материалы на которые стоит обратить внимание:
Документация от оракла про Regex в Java
Всем кому интересен мир разработки приглашаю в мой канал