
Закреплено

Искусственный интеллект
5 055 постов
•
11 479 подписчиков
0 просмотренных постов скрыто


Не бойся, что AI станет человеком. Бойся, что ты перестанешь им быть
AI не пришёл, чтобы уничтожить человечество. Он пришёл, чтобы показать, насколько хрупкой стала наша с вами способность быть людьми.

Когда машины начинают писать стихи, ставить диагнозы и даже поддерживать нас при эмоциональном кризисе, возникает не техническая проблема — а экзистенциальная. Что остаётся от нас, если всё, что можно измерить и оптимизировать, делает алгоритм?
Статья за авторством Shaoshan Liu (Shenzhen Institute of Artificial Intelligence and Robotics for Society), Anina Schwarzenbach (University of Bern), Yiyu Shi (University of Notre Dame) от октября 2025 года предлагает переосмыслить вызов: вместо того чтобы спорить: догоним ли мы AI, начать строить многоуровневую защиту от цифрового выгорания и отчуждения. Авторы это называют человеческой устойчивостью - система из трёх уровней.
Личный уровень - умение не терять себя в потоке решений, сделанных «за тебя». Это эмоциональная регуляция, способность переосмысливать трудности и гибко адаптироваться. Исследования показывают: люди с такими навыками не просто выживают в условиях цифрового стресса - они используют AI как инструмент расширения возможностей.
Социалка. Люди не выживают в одиночку. Даже в эпоху AI нам нужны живые связи, доверие, общие нормы. Важно не просто быть онлайн, а иметь реальные связи, где можно признать слабость и получить помощь. В одном исследовании AI помогал волонтёрам в ментальном здоровье писать более эмпатичные ответы - и это повышало не только качество поддержки, но и уверенность самих волонтёров. AI здесь не заменял человека - он делал его человечнее.
Организационный или системный уровень - это среда, где можно оспаривать решения алгоритмов, где есть аварийные тормоза и обратная связь. Без этого ИИ превращается в чёрный ящик, который нельзя ни понять, ни остановить. Устойчивые организации не просто внедряют технологии — они проектируют среду, где ошибки — не провал, а сигнал к обучению.




И самое главное: устойчивость можно развивать. Это не хайповые soft skills. Это базовые условия для жизни в мире, где решения принимают не люди. Авторы предлагают развивать этот навык через школьные программы, корпоративные тренинги, государственные инициативы.
AI не уничтожит нас, человечество. Но если мы перестанем инвестировать в то, что делает нас людьми - в способность чувствовать, связываться, выбирать - тогда мы сами откажемся от своего будущего. Устойчивость - это не защита от AI. Это путь к тому, чтобы оставаться человеком в его мире.
Показать полностью
5

Очередной хайп! Что директору по маркетингу делать с GEO?

GEO (Generative Engine Optimization) или по-русски — продвижение в ответах нейросетей
Сначала на каждой конференции говорили про использование ИИ для маркетинга, а теперь перешли на продвижение в нейросетях! Стоит ли добавлять этот канал в свой маркетинг или это очередной хайп?
Для любого маркетолога в МСБ главной задачей является получение ЛИДОВ, не простых, а квалифицированных и окупаемых.
С учётом нынешней медиаинфляции в пуле есть всего пара явно окупаемых каналов.
Скорее всего, это будет SEO со сломанной unit-экономикой, Avito и другие агрегаторы и, если ниша еще не перегрелась, может быть, контекстная реклама. И вот, появляется GEO...
Сейчас GEO — это окупаемый канал для МСБ? Скорее всего, нет.
Почему вложения в GEO не окупятся? Пока мало трафика!
А работы за счёт специфики будут стоить как полноценный маркетинговый канал!
«Ну ладно, может он сейчас неокупаемый, но мы вложимся, а он возьмёт и подрастёт, а мы уже в лидерах и снимаем сливки!»
— И да, и нет! Долго будет расти! Слишком мало трафика в ChatGPT, DeepSeek и Perplexity, но если Алиса и AI-Google заработают в коммерческих запросах — трафик появится в миг, и мы этот миг ждём:)
Сейчас у маркетолога есть дополнительно 150 000 ₽, куда их вложить? Я бы докидывал в SEO на ссылки, текста и накрутку, это точно даст лучший ROMI с перспективой в 1–2 года.
Если вы уже достигли пика в каналах, то для каких ниш я бы посоветовал GEO сегодня:
1. Весь корпоративный сегмент, где маркетинговые бюджеты в месяц — это десятки миллионов (всякие там зелёные, красные и жёлтые банки, операторы и т. д.).
Тут и бренд-медиа свои есть, и цитируемость в авторитетных СМИ — фундамент для GEO отличный. В высокой конкуренции, где отжимается каждый процент рынка, бюджеты на GEO — незаметная статья расходов.
2. Консалтинговые компании с высокой экспертностью (от разработчиков до отделов продаж), там, где много конверсий в информационном трафике.
Тут у нас и ЦА на «ты» с нейронками, и у таких агентств есть свои блоги и авторы — сам бог велел. Тем более, это поможет работать с резким снижением информационного трафика с SEO.
3. Дорогой B2B со сложным товаром.
Здесь также большое проникновение нейронок в ЦА, есть сложность не только с выбором поставщика, но и с выбором решения, требуется много обзоров и консультаций, что, опять же, про нейронки!
В других нишах, можно использовать скорее, если собственник сильно хочет быть самым инновационным, но я бы скорее не делал:)
В следующих постах поговорим мы с вами поговорим про семантику, оптимизацию и самое сладкое — анализ вашего присутствия в ИИ…
Показать полностью
1

OpenAI готовится к одному из крупнейших IPO в истории
К концу этого года компания планирует подать документы, а к началу следующего - акции окажутся в продаже. Процесс запустился немедленно после недавней реструктуризации, которая сделала OpenAI пригодной для публичного листинга.
Выход на биржу рассматривается с оценкой в 1 триллион долларов!
Это действительно один из крупнейших IPO в истории технологических компаний. Для сравнения: сейчас оценка OpenAI составляет 500 млрд долларов. То есть компания рассчитывает удвоить свою стоимость к моменту размещения.
Ожидается, что выручка на конец этого года будет 20 млрд долларов.
Получается, что OpenAI делает ставку на публичный рынок в момент, когда вокруг ИИ максимальный хайп. Вопрос только в том, сможет ли компания оправдать триллионную оценку.
Хотя, ИИ-хайп - создала, в принципе, сама же компания OpenAI. Так что - получится. 😎
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью

Бесплатный способ получить доступ к Veo 3 из России в 2025 году — обход блокировки Google
Ищете бесплатный способ получить доступ к Veo 3 из России в 2025 году? Узнайте, как осуществить обход блокировки Google и получить доступ без ограничений. Официальный вход в Veo 3 требует времени и оплаты, но существует реальная возможность получить полноценный доступ к созданию видео без существенных финансовых вложений. Решение работает на многих аккаунтах с российских IP и не зависит от наличия зарубежных банковских карт.

Бесплатный способ получить доступ к Veo 3 из России в 2025 году — обход блокировки Google
Причины блокировки Google и основные трудности
С начала 2025 года Google ужесточил санкции: сервис Veo 3 для генерации видео стал недоступен для пользователей из РФ и ряда других стран. Корпорация ввела тройную систему ограничений:
Блокировка по IP (определяет местоположение)
Запрет на российские платежные средства
Анализ истории профиля (выявляет частые смены стран)
Простая смена IP через стандартные VPN теперь малоэффективна — Google научился сопоставлять региональные данные с платежной информацией. Многие популярные VPN уже в списке заблокированных, а платный Gemini с возможностью работы с Veo 3 обойдется минимум в 20 долларов за месяц.
Обстановку осложняет еще и то, что Google регулярно обновляет систему обнаружения обхода блокировок. То, что работало вчера, может быть бесполезно завтра. Большинство гайдов из интернета быстро теряют актуальность.
Пошаговая инструкция по быстрому доступу к Veo 3 в 2025 году
Если важен быстрый результат, подойдет следующий метод, проверенный лично и на знакомых:
Скачайте VPN с надежными американскими серверами
Подключитесь к серверу в США — желательно выбрать Нью-Йорк или Калифорнию
Запустите браузер в режиме инкогнито
Создайте новый Google-аккаунт с американским адресом, используя генератор фейковых адресов
Откройте Gemini и включите бесплатный пробный период
Этот способ дает месяц бесплатного доступа. Дальше придется регистрировать новые аккаунты, что быстро надоедает, а при подозрительной активности Google способен заблокировать IP.
Надежный способ долгосрочного доступа
Рассказываю о рабочем способе получить стабильный доступ к Veo 3 без необходимости регулярно менять учетные записи. Давайте разберемся по шагам, что потребуется:
Шаг 1: Новый американский профиль без следов
Создайте цифровой образ, чтобы Google "увидел" настоящего пользователя из США:
Запустите отдельный браузер для работы с Veo 3 — Firefox или Edge подойдут лучше всего
Поставьте расширение Privacy Badger для защиты от отслеживания
Подключите американский VPN
Зарегистрируйте свежий Google-аккаунт с данными США
По личному опыту, профили с "правильной" историей использования Google почти не попадают под блокировки. Поэтому, до активации Veo 3, несколько дней пользуйтесь этим аккаунтом — смотрите YouTube, проверяйте почту, ищите что-то в поиске, имитируя поведение обычного жителя США.
Шаг 2: Виртуальная карта без подтверждения
Пока искал лучшие способы обхода ограничений, неоднократно пользовался российским ботом с быстрым доступом к Veo — отличный вариант для экспресс-генерации, когда не хочется возиться с настройками. Но если нужен полноценный доступ к оригиналу, переходим дальше.
Для активации бесплатного периода потребуется карта с американскими реквизитами:
Попробуйте сервисы для выпуска виртуальных карт — найдете подходящий вариант через поисковик.
Шаг 3: Оформление подписки Gemini Advanced для Veo 3
Чтобы получить полный доступ к Veo 3, потребуется оформить подписку Gemini Advanced:
С активированным VPN откройте сайт Gemini
Войдите, используя созданный "американский" аккаунт
Нажмите "Try Gemini Advanced"
Введите данные виртуальной карты
Запустите бесплатный пробный период на 30 дней
Сразу отключите автообновление подписки в настройках
В отличие от стандартных схем, этот способ позволяет создать устойчивый профиль, который Google воспринимает как реального пользователя из США.
Шаг 4: Как пользоваться Veo 3 без риска блокировки
Из практики видно: если активность аккаунта кажется подозрительной, Google может ограничить доступ. Чтобы этого не произошло:
Для каждого аккаунта используйте исключительно один и тот же VPN-сервер.
Не создавайте более 15-20 роликов за сутки — такие объемы могут вызвать подозрения и проверки.
Регулярно применяйте с этого аккаунта и другие продукты Google.
Отправляйте готовые ролики в Google Drive или размещайте на YouTube — это формирует поведение обычного пользователя.
Соблюдение этих советов позволяет аккаунту функционировать месяцами — проверено многократно.
Бесплатные способы через Google Фото
Если не требуется весь функционал Veo 3, а достаточно простых возможностей, подойдет интеграция с Google Фото:
Скачайте Google Фото на телефон.
Подключитесь через VPN к серверу в США.
Авторизуйтесь в созданном "американском" профиле.
Перейдите во вкладку "Утилиты".
Найдите пункт "Создать видео" или "Video Generation".
Особенности этого способа:
Максимальное время видео — 4 секунды (вместо 60 в полной версии).
Генерация аудио недоступна.
Картинка ограничена HD-качеством.
На видео появляется водяной знак Google.
Для коротких роликов или GIF этот вариант вполне рабочий.
Типичные ошибки и способы их избежать
За время тестирования доступа к Veo 3 были выявлены самые частые ошибки, которые приводят к блокировке:
Ошибка 1: Мобильный VPN
VPN на телефоне часто не защищает от утечек и может раскрывать реальный регион. Google легко замечает несовпадение IP и других параметров.
Правильный подход: Используйте VPN на компьютере с активированным Kill Switch и защитой от WebRTC.
Ошибка 2: Одновременная авторизация в нескольких сервисах
Если на одном гаджете открыт российский Google-аккаунт, а на другом — "американский", система может связать их между собой.
Правильный подход: Полностью завершайте работу во всех сервисах Google, прежде чем переходить на "американский" профиль.
Ошибка 3: Использование одного браузера для разных профилей
Даже приватный режим не гарантирует анонимность — браузеры могут сохранять уникальные идентификаторы, позволяя Google всё отследить.
Правильный подход: Настройте отдельный браузер исключительно для взаимодействия с Veo 3 и не используйте его для входа в российские сервисы.
Ошибка 4: Некорректное заполнение платежной информации
При добавлении виртуальной карты важно, чтобы почтовый адрес совпадал с указанным в профиле Google и был настоящим американским адресом.
Правильный подход: Используйте одинаковый американский адрес везде, предварительно проверяя его корректность на USPS Zip Code Lookup.
Ошибка 5: Создание подозрительных материалов
Google тщательно отслеживает обращения к Veo 3 и может ограничить доступ за попытки создания запрещенного контента.
Правильный подход: Не создавайте политические, взрослые или опасные материалы. Формулируйте запросы максимально нейтрально.
Устранение этих важных ошибок существенно увеличивает стабильность работы Veo 3, обходя региональные ограничения.
Рекомендации от опытных пользователей Veo 3
Пользователи делятся практическими советами на тематических платформах, помогающими обойти блокировки. Вот несколько лучших рекомендаций с YesAI:
Для VPN выбирайте американские, британские или канадские серверы — в этих регионах Veo 3 стабилен
Лучше использовать менее загруженные VPN-локации (например, не Нью-Йорк и не Лос-Анджелес) — часто результат оказывается лучше
Наиболее безопасное время работы — с 3:00 до 7:00 по Москве, когда в США вечер и нагрузка ниже
Запросы к Veo 3 лучше формировать на английском — так уменьшается риск проверки
Необычные запросы вроде мемов вызывают меньше подозрений у системы
Один пользователь заметил: при создании профиля через VPN с американским IP, но без моментального оформления подписки, а с активацией спустя 3-5 дней, риск блокировки аккаунта значительно снижается.
Вывод: рабочая стратегия на 2025 год
После многочисленных тестов удалось выработать наиболее эффективную схему для бесплатного доступа к Veo 3 в России:
Для работы с Veo 3 заведите отдельный браузерный профиль
Пользуйтесь проверенным платным VPN с серверами в США и защитой от утечек
Создайте Google-аккаунт с американскими данными и проявляйте в нем правдоподобную активность минимум неделю
Получите виртуальную карту с реквизитами США
Запустите бесплатный тестовый период в Gemini Advanced
Не превышайте 15-20 генераций в сутки
За 7 дней до завершения пробного периода начинайте подготовку нового аккаунта
Такой способ обеспечивает стабильную работу с Veo 3 без лишних расходов и снижает риск блокировки.
Будьте в курсе изменений
Google регулярно обновляет способы выявления обходов, поэтому советую следить за свежими обсуждениями на профильных форумах и в сообществах — там всегда можно узнать о новых работающих методах.
Нейросети для видео — шаг в будущее
Генерация видео с помощью нейросетей стремительно меняет подходы к созданию контента. Даже с ограничениями по регионам, хочется, чтобы такие технологии были доступны для всех. Надеюсь, эта инструкция пригодится тем, кто хочет прикоснуться к будущему визуального маркетинга и творчества.
Показать полностью
1
AI от Павла Дурова, IT для молодых умирает, ИИ-учёный на ChatGPT
Сегодня в выпуске про ИИ:
Telegram создает альтернативу OpenAI без цензуры
Anthropic решает главную проблему Excel
OpenAI выпустила опенсорс-модель для модерации
Google запустил ИИ для брендового контента
88% компаний увеличат инвестиции в ИИ
Cursor сделал свою ИИ-модель
OpenAI создаст искусственного ученого к 2028 году
Карьера в IT для молодых умирает
ИИ может заглядывать внутрь себя
Как психолог в 1949 открыл правило, которое изменило машинное обучение
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2

Higgsfield запускает сервис Popcorn для сторибордов
Higgsfield запустили режиссёрский режим для сторибордов.
Новая фича под названием Popcorn делает раскадровку будущего видео. Есть два режима работы:
— Manual: прописываем каждый кадр вручную промптом;
— Auto: загружаем до 4 референсов (персонажи, локации, атмосфера) и получаем до 8 кадров с похожим стилем и светом.
Нам обещают «идеальную консистентность» и уже раздают 250 кредитов всем подписчикам
Показать полностью
Как изменилось отношение к ИИ после бума ChatGPT

До 2022 года ИИ воспринимали как фоновую технологию: рекомендации на Netflix, чат-боты, фильтры в Instagram. Но с приходом ChatGPT он вышел на первый план - и начал вызывать тревогу. Швейцарские исследователи провели два опроса: один до бума генеративного ИИ (январь–февраль 2022), другой - после (июль–август 2023).
Исследование охватило почти 3000 человек. Их спрашивали: допустимо ли, чтобы ИИ ставил диагноз, решал, давать ли кредит, занимался наймом или выбирал, кого освободить из тюрьмы. До бума таких вопросов почти не задавали - ИИ казался слишком далёким.
Результат: доля тех, кто считает ИИ «совсем неприемлемым», выросла с 23% до 30%. А число людей, настаивающих на том, чтобы такие решения принимал только человек, - с 18% до 26%. Особенно резко упала поддержка ИИ в медицине и в вопросах, связанных с жизнью и правосудием.


При этом выросли социальные разрывы. Женщины стали гораздо скептичнее мужчин - особенно в медицинских сценариях. Люди с высшим образованием по-прежнему более открыты к ИИ, но те, у кого образования меньше, начали его отвергать ещё сильнее.
Вывод простой: технологический прорыв не автоматически ведёт к общественному принятию. Наоборот - чем громче хайп, тем больше люди начинают задумываться о рисках. ИИ перестал быть «просто инструментом» - он стал символом угрозы автономности, справедливости и контроля.
Большинство требует человеческого контроля и не готовы к полномасштабной автоматизации процессов на базе ИИ, вопреки некоторым ожиданиям индустрии.
Показать полностью
3
Что, если "разум" стирает память: как спасти знания в "видящих" нейросетях?
Автор: Денис Аветисян
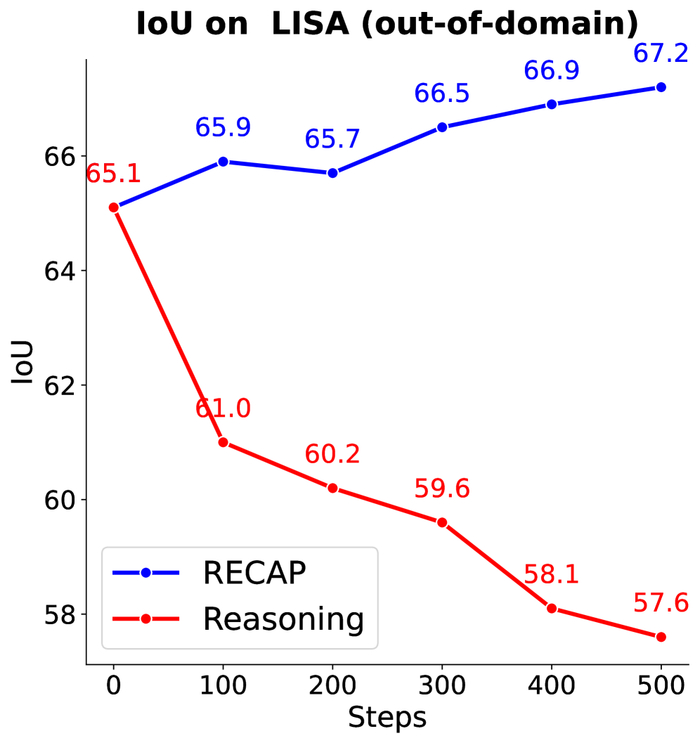
Модель, дообученная с использованием RECAP, не только сохраняет исходную производительность, но и превосходит её на 2%, в то время как модель, ориентированная на рассуждения, быстро отстаёт после 100 итераций, демонстрируя превосходство подхода, выходящего за рамки простой оптимизации рассуждений.
По мере того, как большие языковые модели (LLM) становятся все более сложными, возникает парадоксальное противоречие: стремление к улучшению способностей к рассуждению часто происходит за счет общей эрудиции и способности к обобщению. В исследовании “Beyond Reasoning Gains: Mitigating General Capabilities Forgetting in Large Reasoning Models” авторы смело задаются вопросом о том, не достигаем ли мы кажущихся «выигрышами в рассуждениях», лишь усугубляя проблему «забывания» ранее приобретенных знаний и навыков. Ведь, если модель становится экспертом в решении логических задач, но теряет способность распознавать простые визуальные образы или понимать контекст обыденных разговоров, не превращается ли она в узкоспециализированного гения, оторванного от реальности? Не является ли эта тенденция к «забыванию» фундаментальным препятствием на пути к созданию действительно универсального искусственного интеллекта, способного не только мыслить, но и понимать мир во всей его полноте?
Логический тупик больших языковых моделей
Несмотря на колоссальный масштаб, большие языковые модели (БЯМ) часто сталкиваются с трудностями при решении сложных задач, требующих рассуждений. Они демонстрируют ограниченную глубину логического анализа и непостоянство выводов. Это похоже на попытку построить небоскрёб на зыбком фундаменте – масштаб впечатляет, но прочность оставляет желать лучшего.
Традиционные подходы, заключающиеся лишь в увеличении числа параметров, оказываются недостаточными для преодоления этих дефектов. Увеличение масштаба – это как добавление лошадиных сил к автомобилю с заблокированными колёсами. Это может быть впечатляюще, но неэффективно. Требуются более изящные, эффективные методы, позволяющие БЯМ действительно “думать”, а не просто воспроизводить паттерны.
Особенно проблематичным является склонность современных моделей к “галлюцинациям” – генерации фактически неверной информации. Это как если бы система навигации указывала несуществующие улицы или выдавала ложные координаты. Проблема заключается не только в отсутствии знаний, но и в неспособности надёжно осуществлять логические выводы и связывать информацию.
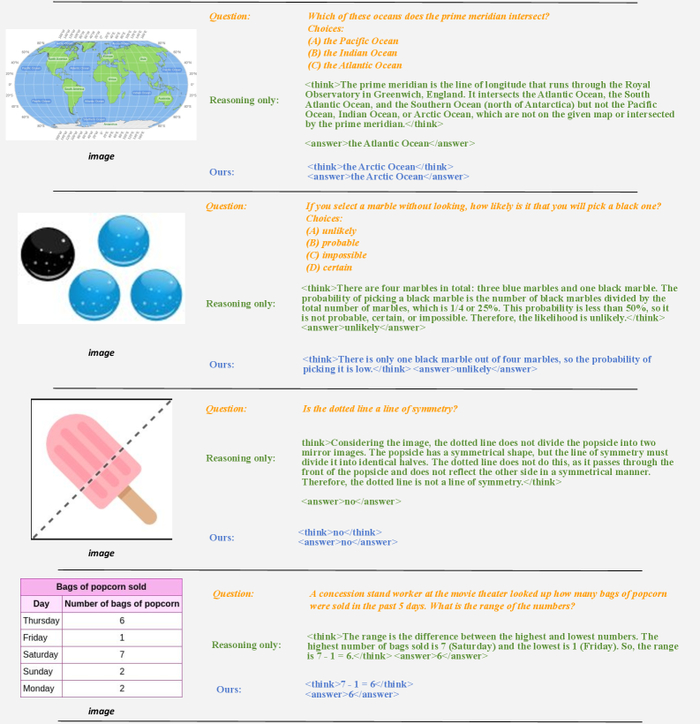
Модель, обученная с использованием только рассуждений, генерирует длинные цепочки рассуждений для простых визуальных вопросов, в то время как предложенная модель производит более лаконичные ответы, особенно в задачах, не связанных с математикой.
Авторы данной работы рассматривают это как “узкое место” в развитии БЯМ – проблему, требующую не просто увеличения вычислительных ресурсов, а принципиально новых подходов к организации логического мышления. Они утверждают, что для того чтобы БЯМ действительно решали задачи, а не просто “имитировали” решение, необходимо научить их не только “знать”, но и “понимать” – устанавливать причинно-следственные связи, выделять главное от второстепенного, делать обоснованные выводы. Это похоже на взлом системы – не просто нахождение уязвимости, а понимание её принципов работы.
Их исследование направлено на создание моделей, способных не только генерировать правдоподобные ответы, но и предоставлять обоснованные доказательства своей правоты – прозрачные, логичные, и проверяемые. Это, по мнению авторов, является ключом к созданию действительно интеллектуальных систем, способных решать сложные задачи и приносить пользу человечеству. Их подход – это не просто улучшение существующих моделей, а создание принципиально новых, способных мыслить и понимать мир вокруг нас.
RLVR: Алгоритм взлома познания
В погоне за искусственным интеллектом, способным не просто выдавать ответы, но и демонстрировать ход мысли, исследователи обращаются к новым парадигмам обучения. Одной из таких парадигм является обучение с подкреплением с проверяемыми вознаграждениями (Reinforcement Learning with Verifiable Rewards, RLVR). Это не просто ещё одна вариация алгоритмов машинного обучения, а скорее попытка взломать систему познания, заставив модель не просто “угадывать” правильный ответ, но и доказывать его логическую обоснованность.
В отличие от традиционных подходов, фокусирующихся исключительно на конечном результате, RLVR делает ставку на поощрение самого процесса рассуждения. Идея проста, но элегантна: вознаграждайте модель не за правильный ответ, а за правильный путь к нему. Этот подход требует внедрения так называемых "вознаграждений за мышление" (Thinking Rewards), которые стимулируют модель демонстрировать последовательную и логичную цепочку рассуждений. Вместо того, чтобы просто проверять, угадала ли модель ответ, система оценивает, насколько убедительно и логично она пришла к этому ответу.
В основе RLVR лежит, конечно же, обучение с подкреплением (Reinforcement Learning) – алгоритм, позволяющий модели учиться на своих ошибках и постепенно улучшать свою стратегию. Однако, в контексте RLVR, обучение с подкреплением приобретает новые оттенки. Модель не просто пытается максимизировать вознаграждение, но и оптимизирует сам процесс рассуждения, стремясь к логической стройности и последовательности. Это похоже на отладку сложной программы: нужно не только добиться правильного результата, но и убедиться, что код работает эффективно и без ошибок.
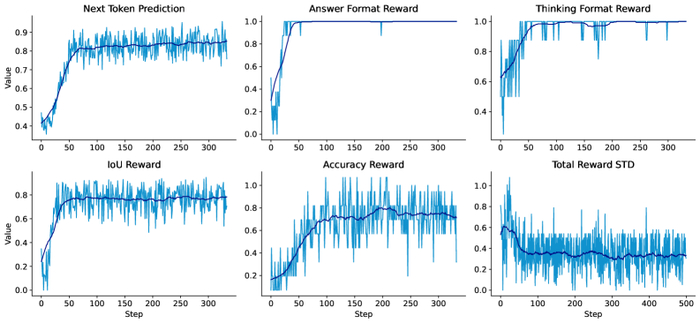
Асинхронная сходимость и высокая дисперсия вознаграждений, наблюдаемые в процессе обучения RLVR (представленные светлыми линиями для пошаговых вознаграждений и темными кривыми для скользящего среднего), подтверждают необходимость использования краткосрочной статистики для динамической переоценки целей, а не величин на каждой итерации.
Особенностью обучения с подкреплением в контексте RLVR является сложность ландшафта вознаграждений. Процесс рассуждения – штука нелинейная и часто непредсказуемая. Оценка логической последовательности требует тонкого анализа и учета множества факторов. Именно поэтому исследователи обращаются к использованию краткосрочной статистики и динамической переоценки целей, чтобы избежать застревания модели в локальных оптимумах и обеспечить стабильное обучение. В конечном итоге, цель состоит в том, чтобы создать искусственный интеллект, который не просто умеет решать задачи, но и умеет мыслить логически и обоснованно – по-настоящему взломать систему познания.
Усиление RLVR: Алгоритмы и техники против катастрофического забывания
По мере углубления в область обучения с подкреплением (RL) для больших языковых моделей (LLM), исследователи сталкиваются с фундаментальным вызовом: как обеспечить не только приобретение новых навыков, но и сохранение уже существующих знаний. Эта проблема, известная как катастрофическое забывание, требует тонкого подхода к проектированию алгоритмов и техник обучения. В рамках обучения с подкреплением с проверяемыми наградами (RLVR), где акцент делается на обучении моделям конкретным навыкам, таким как решение математических задач или логические рассуждения, поддержание общей компетенции становится особенно важным.
Алгоритмы, такие как оптимизация относительной политики группы (Group Relative Policy Optimization), играют ключевую роль в стабилизации процесса обучения в RLVR. Они обеспечивают эффективные последовательные награды, смягчая присущую RL нестабильность. Это позволяет моделям более уверенно исследовать пространство решений, не теряя при этом приобретенных навыков. Без таких алгоритмов, обучение с подкреплением может быстро превратиться в хаотичный процесс, приводящий к непредсказуемым результатам.
Однако, стабилизация обучения – это лишь одна сторона медали. Для эффективного сохранения общих знаний, необходимы методы, которые активно противодействуют катастрофическому забыванию. Здесь на помощь приходит подход, предложенный исследователями, известный как RECAP. Этот метод расширяет возможности RLVR, динамически перераспределяя веса целей и улучшая скорость сходимости за счет тщательного воспроизведения общих данных.
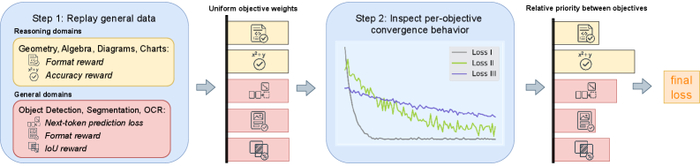
Предложенный метод RECAP, наряду с целевой задачей рассуждений, использует данные из общих доменов для сохранения знаний в процессе тонкой настройки, при этом вес индивидуальных целей корректируется на основе их поведения сходимости для предотвращения доминирования и уменьшения веса насыщенных целей.
В борьбе с катастрофическим забыванием исследователи обращаются к различным техникам. Методы, такие как обучение с ограничением веса (LwF), выборочное хранение данных (Coreset) и динамическое смешивание данных (MoDoMoDo), предлагают различные подходы к управлению разнообразными наборами данных в рамках RLVR. LwF стремится сохранить предыдущие знания, штрафуя отклонения от исходных весов модели. Coreset эффективно выбирает подмножество данных для воспроизведения, минимизируя объем хранимых данных при сохранении репрезентативности. MoDoMoDo, с другой стороны, динамически смешивает данные из различных источников, адаптируясь к потребностям обучения.
Каждый из этих методов имеет свои сильные и слабые стороны. Выбор оптимальной стратегии зависит от конкретной задачи и доступных ресурсов. Однако, общая цель остается неизменной: создать систему, которая может не только приобретать новые навыки, но и сохранять уже существующие знания. В конечном итоге, это позволит создать более гибкие, надежные и интеллектуальные языковые модели, способные решать широкий спектр задач.
RLVR: Надёжность, форматирование и взлом ограничений
Помимо повышения точности рассуждений, парадигма RLVR затрагивает и вполне практичные аспекты. Современные системы часто требуют не только правильного ответа, но и его представления в чётко заданном формате. Соблюдение формата, или “форматное соответствие”, — это не просто прихоть разработчиков, это необходимое условие для интеграции ИИ в реальные приложения. Иначе говоря, система может генерировать гениальные решения, но если она не может их структурировать, они останутся бесполезными.
Авторы работы, однако, не останавливаются на формальном соответствии. Они прекрасно понимают, что системы, обученные лишь имитации желаемого вывода, уязвимы к так называемым “атакам обхода ограничений” (jailbreak attacks). Попытки заставить систему выдать запрещённый вывод, обойдя её фильтры, — это не просто забава для хакеров, это реальная угроза для безопасности и надёжности ИИ. Вместо того чтобы бороться с симптомами, исследователи предлагают лечить корень проблемы: укреплять целостность рассуждений, а не просто обучать систему правильно подражать желаемому поведению.
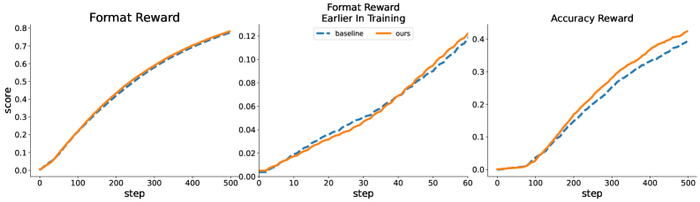
Наблюдаемое увеличение вознаграждения за точность в процессе обучения превосходит увеличение вознаграждения за формат при использовании предложенного метода, что указывает на приоритет правильных решений над форматированием после того, как модель научилась следовать заданному шаблону.
Иными словами, акцент смещается с простого соответствия заданному шаблону на действительно понимание проблемы и логичное её решение. Это не просто технический нюанс, это фундаментальное изменение в подходе к обучению ИИ. Оптимизируя напрямую за проверяемые рассуждения, исследователи прокладывают путь к созданию более надёжных и заслуживающих доверия систем искусственного интеллекта. Ведь, в конечном счёте, лучший хак — это осознание того, как всё работает. И каждый патч — это философское признание несовершенства.
Авторы работы не отрицают, что совершенных систем не бывает. Но они убеждены, что, фокусируясь на фундаментальных принципах рассуждений, можно создать ИИ, который будет не просто выполнять задачи, но и понимать, почему он их выполняет. И это — принципиально важный шаг к созданию действительно разумных машин.
Будущее рассуждений с RLVR: Мультимодальность и непрерывное обучение
Исследования, представленные в данной работе, открывают новые горизонты в области обучения моделей рассуждения с использованием обучения с подкреплением и верифицируемыми наградами (RLVR). Однако, как и в любом новаторском подходе, существуют области, требующие дальнейшего изучения и совершенствования. Авторы чётко осознают ограничения текущих методов и, вместо того чтобы рассматривать их как непреодолимые препятствия, предлагают рассматривать их как приглашение к эксперименту.
Одним из перспективных направлений является расширение RLVR на более сложные мультимодальные модели, известные как Vision-Language Models (VLM). Это открывает захватывающие возможности для обучения моделей не только пониманию текста, но и анализу визуальной информации, что позволяет им рассуждать о сложных сценариях, требующих интеграции различных типов данных. Представьте себе систему, способную не просто ответить на вопрос, но и объяснить свои рассуждения, опираясь на визуальные доказательства – это уже не научная фантастика, а вполне достижимая цель.
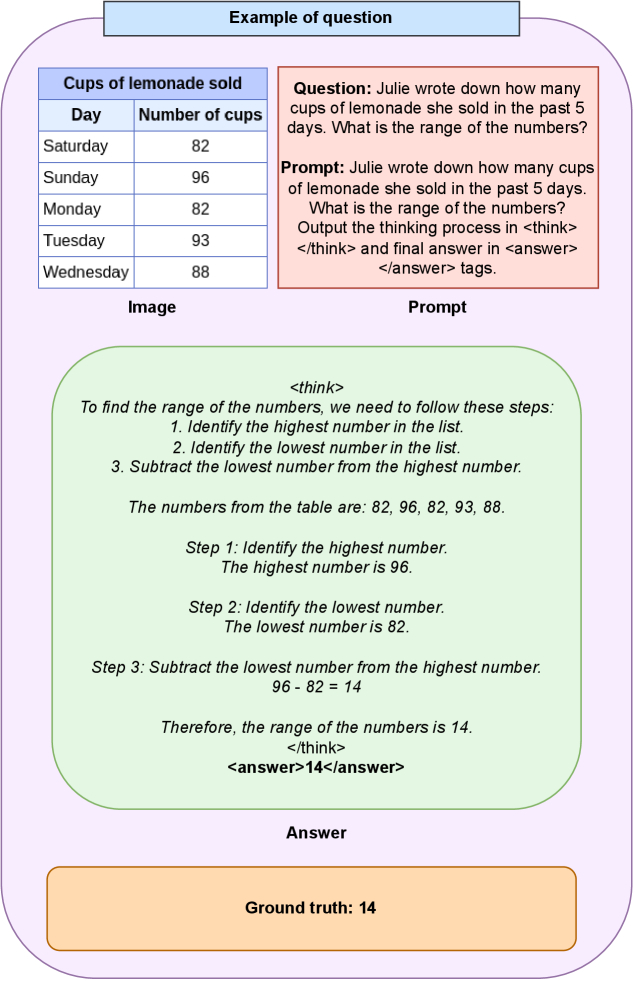
В процессе тонкой настройки модель обучается генерировать цепочку рассуждений, заключенную в теги …, и конечный ответ в тегах ….
Авторы также справедливо отмечают проблему "коллапса исследования и разнообразия", когда модель становится слишком узкоспециализированной и теряет способность находить нестандартные решения. Для решения этой проблемы необходимы дальнейшие исследования в области разработки стратегий исследования и наград, которые стимулируют модель к поиску разнообразных и надежных решений. Вместо того, чтобы стремиться к мгновенному успеху, необходимо создать систему, которая поощряет эксперименты и позволяет модели учиться на своих ошибках.
Наконец, авторы подчеркивают потенциал интеграции RLVR с контролируемой тонкой настройкой (Supervised Finetuning). Сочетание этих двух подходов может позволить использовать сильные стороны каждого из них, что приведет к созданию более эффективных и мощных систем рассуждения. Контролируемая тонкая настройка может обеспечить базовые знания и навыки, а RLVR – улучшить способность модели к рассуждению и решению сложных задач.
Таким образом, представленная работа не только предлагает новый подход к обучению моделей рассуждения, но и открывает новые горизонты для будущих исследований. Авторы демонстрируют, что ограничения – это не тупик, а приглашение к эксперименту, и что только путем постоянного поиска и инноваций можно достичь подлинного прогресса в области искусственного интеллекта.
Что дальше?
Исследование, представленное авторами, – лишь одна попытка расшифровать открытый исходный код реальности, в данном случае – нейронные сети. Проблема “катастрофического забывания” – это не ошибка алгоритма, а отражение фундаментального принципа: любая система, оптимизированная для нового, неизбежно теряет связь со старым. Авторы успешно смягчили эту потерю, но вопрос в том, можно ли вообще её избежать? Не является ли “забывание” необходимой частью обучения, своего рода очисткой памяти от несущественного, чтобы освободить место для нового?
В дальнейшем, вероятно, потребуются более радикальные подходы. Динамическая перевзвеска целей и воспроизведение данных – это, безусловно, полезные инструменты, но они лишь замаскируют, а не решат проблему. Возможно, стоит исследовать архитектуры, которые принципиально отличаются от текущих, – системы, способные хранить и использовать знания параллельно, а не последовательно. Или, может быть, ключ лежит в создании моделей, которые способны не просто “запоминать” информацию, а “понимать” её, выстраивая внутреннюю модель мира, устойчивую к изменениям.
В конечном счете, мы сталкиваемся не с технической проблемой, а с философским вопросом: что такое знание и как оно хранится? Авторы сделали важный шаг в этом направлении, но предстоит еще многое проверить и переосмыслить. Реальность, как и любой сложный код, сопротивляется простому взлому – она требует глубокого понимания.
Оригинал статьи: denisavetisyan.com
Связаться с автором: linkedin.com/in/avetisyan
Показать полностью
6