
Закреплено

Искусственный интеллект
5 055 постов
•
11 479 подписчиков
0 просмотренных постов скрыто


Как создать логотип для бизнеса с помощью нейросетей: подробная инструкция для начинающих
В данной статье представлена подробная инструкция о том, как создать логотип для бизнеса с помощью нейросетей, что будет особенно полезно для начинающих. Читатели ознакомятся с основными шагами, необходимыми для эффективного использования современных технологий графического дизайна, а также с полезными ресурсами и советами по созданию уникального visual-идентификатора.

Как создать логотип для бизнеса с помощью нейросетей: подробная инструкция для начинающих
Пошаговое руководство по созданию логотипа при помощи нейросетей
Планируете оформить стильный логотип для компании, но не знаете, как подойти к задаче? Ниже — подробная инструкция, как за короткое время сгенерировать фирменный знак через нейросеть. С помощью искусственного интеллекта можно получить уникальный дизайн, который выгодно подчеркнет особенности вашего бренда и привлечет внимание клиентов.
Что нужно для самостоятельного создания логотипа?
На создание современного логотипа уйдет не больше 40 минут. По итогам работы получится набор файлов для любых задач: прозрачный PNG для сайта, SVG-вектор для полиграфии и масштабирования.
Понадобятся только краткое описание вашего бизнеса и пара удачных промтов — никаких специальных навыков дизайнера не требуется, остальное выполнит нейросеть.
Заранее подготовьте:
Одно короткое предложение о деятельности, например: "Обучающая онлайн-платформа для предпринимателей" или "Доставка товаров для магазинов".
Предпочтения по стилю: минимализм, ретро, официальный, либо яркий и современный формат. Если выбрать сложно, лучше начать с универсального минимализма.
Основные цвета бренда: Если палитра еще не выбрана — определите 2-3 сочетающихся цвета в процессе работы.
Где будет использоваться логотип: сайт, визитка, наружная реклама, соцсети. От этого зависят требования к форматам изображений.
Первый шаг: создание логотипа с помощью Midjourney
Для генерации ярких логотипов отлично подходит Midjourney v7 — инструмент, позволяющий детально настроить внешний облик и элементы. В этом Telegram-боте сервис работает без VPN и поддерживает оплату картами российских банков — быстро и удобно.
Запустите бота и напишите первый промт. Структура простая: описание бизнеса, указание стиля, цветовой гаммы и нужного формата файла.
Примеры промтов для разных направлений бизнеса
IT-сфера:
Минималистичный логотип для IT-компании в современном стиле, сочетание синего и белого, плоская графика, четкая структура линий, профессиональная подача, векторная иллюстрация
Кафе и рестораны:
Винтажный логотип для кофейни, теплые оттенки коричневого, ретро-эмблема без надписей, выполнен как векторная работа
Юридические фирмы:
Сдержанный логотип юридической компании, темно-синий с золотистым, геометрия, форма щита, лаконичный стиль, векторная графика
Фитнес и спорт:
Динамичная эмблема для зала, красно-черная палитра, стиль щита, современная подача, четкая векторная иллюстрация
Салон красоты:
Элегантный логотип бьюти-салона, светло-розовый с золотом, цветочные узоры, роскошный образ, чистая векторная графика
Вставляем промт и ожидаем примерно тридцать секунд — Midjourney создаст четыре варианта.
Не всегда с первого раза выходит нужный вариант. Смотрим готовые решения, подбираем лучший.
Пример фирменного знака, сгенерированного нейросетью

Правка концепции и выбор стиля для логтипа
Если базовая идея подходит, но детали хочется скорректировать, меняем промт, уточняя детали.
Рекомендации для улучшения промта:
Для изменения стиля: "flat style" (минимализм), "3D look" (трехмерность), "sketch style" (эскиз), "gradient palette" (градиенты)
Для цвета: "monochromatic" (однотонный), "vivid palette" (яркие оттенки), "pastel colors" (пастельные тона), "blue and white" (синий с белым)
Для формы: "circle logo" (круг), "square icon" (квадрат), "horizontal format" (горизонтальная компоновка), "iconic look" (иконка)
Если дизайн получился избыточно сложным: Минималистичный логотип кофейни, только коричневый, геометрические формы, четкие линии, без текста, векторная работа.
Пробуем еще несколько вариантов — обычно трех-четырех попыток достаточно.
Создание логотипа с помощью FLUX
FLUX 1.1 Pro формирует изображения быстрее Midjourney — результат появляется за 4 секунды. Иногда платформа предлагает неожиданные решения, поэтому стоит повторить промт через FLUX.
В боте с нейросетями можно быстро переключиться на FLUX — удобно сравнивать разные версии.
Логотип легко изменить и доработать в Sora Images, просто напишите в промте, какие корректировки нужны.

Экспорт логотипа в нужном формате
Главная проблема — нейросети обычно выдают PNG, а для работы чаще требуется вектор. Ситуация решается разными способами.
Сохраняем оригинал в хорошем разрешении:
В боте нажимаем на готовый логотип — скачиваем картинку. Обычно размер — 1024×1024 пикселя, этого достаточно для большинства задач.
Для печати стоит увеличить разрешение: в меню под изображением выбираем "upscale".
Векторизация логотипа
Самый быстрый вариант — воспользоваться Photopea (бесплатный аналог Photoshop). Загружаем PNG, обводим контуры Pen Tool, сохраняем как SVG. Еще проще — Vectorizer.io: загружаем картинку, сервис сам переводит ее в векторный формат. Итог зависит от качества изначального файла. Также бот поддерживает экспорт в SVG.
Профессиональный способ — Adobe Illustrator с функцией Image Trace. Если установлен этот редактор, результат будет более точным.
Подготовка логотипа для разных платформ
Логотип придется адаптировать для различных площадок. Каждый случай требует своих настроек.
Для сайтов и соцсетей:
PNG с прозрачным фоном — 512×512 пикселей подойдет для иконки, 1200×400 — для обложки. Сразу можно запросить удаление фона: "Remove background, transparent PNG".
Для аватарок:
Используют квадратные лого. Если знак вытянутый, делаем упрощенный квадратный вариант.
Для печати:
Лучший выбор — SVG или AI: при масштабировании не теряется резкость. Для полиграфии достаточно 300 dpi.
Для печатной продукции применяем CMYK через Photoshop, а не RGB. Если не уверены, как это сделать, сотрудники типографии обычно подскажут бесплатно.
Для документов:
Горизонтальный логотип подойдет для бланков или презентаций. Соотношение сторон — примерно 3:1 или 4:1.
Монохромная черно-белая версия нужна для штампа и факса. Получить ее можно через промт: "minimalist logo, black and white, no color".
Готовые промты для разных бизнес-направлений
Собрал примеры промтов, которые стабильно показывают отличные результаты. Цветовую схему можно адаптировать под свой бренд.
IT и технологии:
Современный логотип айти-компании, абстрактный геометрический символ, плавный синий градиент, лаконичный стиль, вектор, четкие линии
Логотип для разработки ПО, элементы, связанные с кодом, темно-синий и бирюзовый цвета, плоский стиль, геометрические формы
Еда и напитки:
Фирменный знак ресторана, мотив поварской шапки, уютные оранжевые и коричневые оттенки, ретро атмосфера, круглая эмблема, от руки нарисованный стиль
Значок кофейни, изображение кофейного зерна, коричнево-бежевые цвета, домашний деревенский дух, простые геометрические элементы
Медицина и здоровье:
Логотип клиники, крест как основа, зеленые и белые цвета, чистый и надежный образ, деловой стиль, векторная графика
Значок стоматологической клиники: стилизованный зуб, сине-белый градиент, современный деловой стиль
Строительство и ремонт:
Эмблема строительной фирмы: дом или молоток в основе, оттенки оранжевого и серого, индустриальный характер, запоминающийся внешний вид
Логотип архитектурного бюро:
Очертания здания, черно-золотая цветовая палитра, геометрия и деловая элегантность в оформлении
Дополнительно промты для бизнеса можно посмотреть здесь — участники делятся необычными идеями и результатами.
Главные ошибки при создании логотипов и как их избежать
Слишком сложный логотип — должен оставаться узнаваемым даже в уменьшенном виде. Если при сжатии до иконки 16×16 пикселей дизайн теряет четкость — пора упростить детали.
Проверьте сами: уменьшите изображение до размера значка на телефоне. Если элементы становятся неразличимыми — необходима облегченная версия.
Неподходящие цвета — для каждой отрасли свои оттенки. Ярко-розовый не подойдет для юридических фирм.
Универсальные варианты: синий — для сферы IT и финансов, зеленый — для медицины и экологии, коричневый — для еды и напитков, черный — для премиальных марок.
Сложности с масштабированием — PNG-формат плохо увеличивается без потери четкости. Создавайте логотип только в векторном формате.
Легко проверить качество: увеличьте изображение в пять раз. Если появятся пиксельные квадратики — потребуется векторная версия.
Часто требуется черно-белый логотип — иногда дизайн нужен без цвета. Лучше заранее разработать монохромный вариант, пока помните все детали. Получить черно-белую версию можно через Sora Images, указав в промте, какой результат хотите увидеть.
Это особенно актуально для документов, печати, штампов или брендовых шевронов.
Сервисы для работы с логотипом
Для удаления фона: Remove.bg — быстро и автоматически убирает фон, поддерживает пакетную обработку через API.
Векторизация: Vectorizer.io — превращает PNG в SVG. Подходит для несложных иконок, качество среднее.
Оптимизация размера: TinyPNG — уменьшает объем PNG, сохраняя четкость. Удобно для ускорения загрузки сайта.
Создание иконок: Favicon.io — создает набор иконок для браузеров и устройств из одного изображения.
Для подбора цветов: Coolors.co помогает подобрать гармоничные сочетания оттенков, дает возможность закрепить главный цвет логотипа.
Коммерческое использование нейросетевых генераций
Помните: не все картинки, созданные через нейросети, можно использовать в коммерческих целях без ограничений.
Midjourney разрешает коммерческое использование при наличии платной подписки. При работе через бота уточняйте лицензию.
FLUX, как правило, не ограничивает коммерческое применение, однако обязательно проверьте условия конкретного сервиса.
В любом случае, логотип, созданный нейросетью, желательно доработать в графическом редакторе — индивидуальность повысится, а риски уменьшатся.
За тридцать минут реально получить готовый логотип в нужных форматах — разместите его на сайте, визитках или в социальных сетях. Если потребуется фирменный стиль, логотип легко адаптируется для документов и презентаций.
Использование нейросетей не только упрощает создание — они ускоряют работу и открывают новые способы оформления. Главное — осознанно выбирать инструменты под свои задачи.
Показать полностью
3

Заменить человека в кадре с помощью нейросети
Делаем ДИПФЕЙКИ за минуту с помощью свежей имбы — MoCha! Тулза работает на совершенно новой архитектуре — она позволяет заменить человека в кадре без рваной картинки и с правильным освещением.
Работает на основе китайской модели Wan 2.1 и пока может запускаться только локально на ПК.
На GitHub
Показать полностью
Обучение языковых моделей: фокус на значимые данные
Автор: Денис Аветисян
Новый подход к тренировке больших языковых моделей, ориентированный на повышение эффективности за счет приоритезации наиболее информативных токенов.
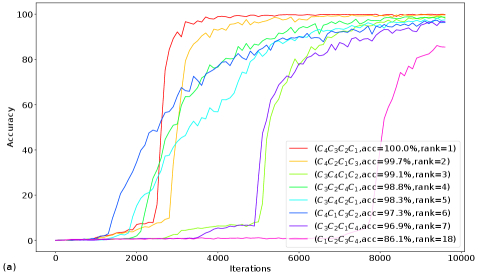
Порядок целевых токенов оказывает существенное влияние на сходимость обучения языковых моделей – от NanoGPT (0.09M параметров) и GPT-2-mini (2.67M параметров) для арифметических задач, до Qwen-2.5-1.5B-Instruct при классификации токсичного контента, и GPT-2-small (137M параметров) при генерации текста на WikiText-2, – демонстрируя, что даже незначительные архитектурные решения могут предсказывать будущие точки отказа в процессе оптимизации.
Исследование предлагает стратегию обучения, оптимизирующую последовательность предсказания токенов для улучшения производительности в различных задачах обработки естественного языка.
Оптимизация обучения больших языковых моделей (LLM) остается сложной задачей, особенно в контексте поддержания вычислительной эффективности при одновременном повышении производительности. В работе «Training LLMs Beyond Next Token Prediction -- Filling the Mutual Information Gap» предложен новый подход, основанный на приоритетном предсказании наиболее информативных токенов в процессе обучения. Данная стратегия позволяет оптимизировать последовательность предсказания токенов, что приводит к улучшению результатов в задачах арифметики, многометочной классификации текста и генерации естественного языка. Какие перспективы открывает данное направление для разработки более эффективных и интеллектуальных языковых моделей?
Предсказание Следующего Токена: Основа и Ограничения
Современные языковые модели, такие как GPT-2, семейства Llama и Qwen, базируются на предсказании следующего токена. Этот подход обучает модель вероятностному распределению символов в последовательности, учитывая контекст.
Несмотря на эффективность, данный метод может приводить к "смещению экспозиции". Модель обучается на идеальных данных, что ограничивает ее способность обрабатывать сложные или новые ситуации.
В процессе обучения модель не сталкивается с ошибками, что снижает ее устойчивость к неточностям во входных данных и ограничивает адаптацию к изменяющимся условиям. Это создает замкнутый круг, где модель совершенствуется в предсказании наиболее вероятных продолжений, но теряет способность к инновациям.
Хаос – не сбой, а язык природы.
Усиление Контекста: Максимизация Взаимной Информации
Стратегия максимизации взаимной информации (MI) между исходными и целевыми токенами улучшает контекстное понимание. В отличие от традиционных методов, этот подход направлен на выявление наиболее информативных элементов в контексте.
Приоритизация токенов посредством Max(MI(SS;tt)) позволяет модели концентрироваться на частях входной последовательности, которые вносят максимальный вклад в понимание и генерацию текста. Это особенно важно при неоднозначности или неполноте контекста.
Использование взаимной информации в качестве критерия приоритизации позволяет модели отфильтровывать шум и сосредотачиваться на релевантных сигналах, повышая точность и связность генерируемого текста. Такой подход применим в машинном переводе, суммаризации текста и генерации диалогов.
Применение и Валидация: За Гранью Беглости
Применение функции Max(MI(SS;tt)) демонстрирует улучшение производительности в различных задачах. Наблюдается повышение точности в многометочной классификации и сложных рассуждениях, таких как арифметические задачи. В задачах умножения двузначных чисел достигнут прирост точности до 28.5%.
Для повышения устойчивости используются методы расширения данных (Data Augmentation), дополненные алгоритмом TF-IDF. Техника переупорядочивания токенов (Token Reordering) способствует уточнению контекстной обработки информации.
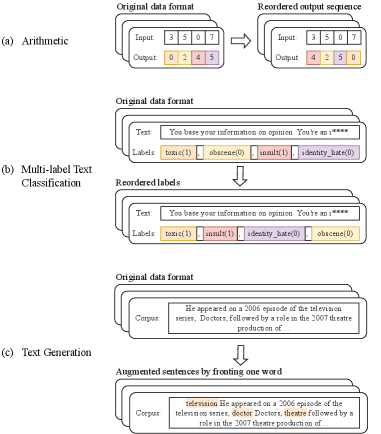
Исследование демонстрирует, что переупорядочивание целевой последовательности успешно применяется в различных задачах, таких как арифметические вычисления, где переставляются цифры числового ответа, многоместная классификация текста, определяющая порядок предсказаний меток, и генерация текста, где выбранный токен вставляется в начало каждого предложения. В арифметических задачах, таких как 35×07=0245, переупорядочивание цифр числового ответа является эффективным методом решения, в то время как в задачах многоместной классификации текста определяется порядок предсказаний меток, а в генерации текста - вставляется выбранный токен в начало каждого предложения. В ходе исследования было установлено, что переупорядочивание целевой последовательности применимо к арифметическим задачам, где переставляются цифры числового ответа, задачам многоместной классификации текста, где определяется порядок предсказаний меток, и задачам генерации текста, где выбранный токен вставляется в начало каждого предложения.
Стратегия позволяет смягчить проблему галлюцинаций, повышая фактическую корректность генерируемого текста. Сокращение неточностей в контенте является важным аспектом повышения надежности и доверия к модели.
Измерение Успеха: Perplexity и За Его Пределами
Традиционные метрики, такие как Perplexity, остаются ценными для оценки качества генерации текста, отражая способность модели предсказывать следующий токен. Однако, целостная оценка требует учета производительности по множеству задач и снижения нежелательных явлений, таких как галлюцинации.
Разработанная стратегия достигает средней точности 94.96% при решении арифметических задач и 78.64% по 9 задачам из GLUE benchmark. Это свидетельствует о значительном прогрессе в способности модели к обобщению и применению знаний.
Сочетание улучшенных метрик и результатов по задачам подтверждает эффективность максимизации взаимной информации и использования целевых методов аугментации данных. В частности, Max(MI(SS;tt)) превосходит Plain на 1.15% и Reverse на 2.04% в задачах многоклассовой классификации.
Каждый запуск – это маленький апокалипсис, и свидетельствами выживших остаются лишь цифры и графики.
Исследование демонстрирует, что последовательность обучения языковой модели имеет решающее значение. Авторы предлагают отойти от простого предсказания следующего токена, фокусируясь на тех, что несут наибольшую информационную нагрузку. Это напоминает о хрупкости любой системы, где нарушение баланса даже в незначительных элементах может привести к неожиданным последствиям. Ада Лавлейс некогда заметила: «Развитие науки — это не просто накопление знаний, а умение видеть связи между ними». Подобно этому, оптимизация последовательности предсказания токенов – это не просто технический прием, а попытка увидеть и укрепить внутренние связи в сложной экосистеме языковой модели, где каждый выбор архитектуры – это пророчество о будущих ошибках. Попытка управлять этой системой – это всегда компромисс, застывший во времени.
Что впереди?
Предложенная работа, стремясь оптимизировать последовательность предсказания токенов, лишь обнажает фундаментальную зависимость любой системы от порядка её формирования. Оптимизация предсказания «информационно-насыщенных» токенов – это не решение, а перестановка факторов в неизбежном приближении к состоянию полной взаимозависимости. Разделяя задачу на приоритетные компоненты, система лишь усложняет картину своих будущих сбоев, закладывая пророчество о том, какие именно точки отказа станут критическими.
Следующим шагом, вероятно, станет попытка моделирования не только вероятности предсказания токена, но и стоимости его ошибки – оценки ущерба от неверного решения в контексте всей системы. Однако, эта оптимизация лишь отодвинет неизбежное – всё связанное когда-нибудь упадёт синхронно, и цена ошибки будет определяться не вероятностью, а масштабом взаимосвязанных компонентов. Иллюзия контроля над сложностью будет лишь укрепляться.
Вместо поиска оптимальной последовательности обучения, возможно, стоит сосредоточиться на создании систем, способных к самовосстановлению после сбоев – не предотвращая их, а смягчая последствия. Потому что системы – это не инструменты, а экосистемы. Их нельзя построить, только вырастить, и в этой эволюции неизбежны мутации и вымирания.
Оригинал статьи: https://arxiv.org/pdf/2511.00198.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Показать полностью
1

Как я перестал терять промпты в заметках Telegram (удобное расширение)
Я ежедневно сижу на Reddit и пополняю свой инструментарий полезными промптами: для генерации роликов, текстов, анализа.
Когда у тебя сотни промптов для разных задач, найти нужный становится квестом.
Но сегодня наткнулся на расширение AI Prompt Saver, которое решило эту проблему и экономит мне время.
▪️Нажимаешь «Создать промпт»
▪️Даёшь ему название
▪️Вставляешь текст промпта
▪️В любой момент открываешь расширение и копируешь нужный промпт одной кнопкой
Никаких заметок, никаких поисков по папкам. Всё под рукой в браузере.
➖➖➖➖➖➖➖➖➖➖➖
Вроде мелочь, но мне сильно экономит время
Для тех, кто работает с AI постоянно, это не просто удобство — это экономия нервных клеток и нескольких часов в перспективе месяца
Эффективность складывается из таких вот мелочей: правильные инструменты под рукой, на поиск которых не нужно тратить время.
Те, кто выстраивает свой рабочий процесс через удобные инструменты, работают быстрее и делают больше 🤝
✔️P.S: Мой тг блог, где я делюсь своим опытом работы с ИИ - Чай с GPT
Показать полностью

ИИ-пузыря - нет, горячая профессия в ИИ, Альтмана выбесили
Сегодня в выпуске про ИИ:
Самая горячая профессия в ИИ с ростом на 800%
Новая сделка OpenAI на 38 млрд долларов
ИИ-браузеры обходят платные подписки
Apple не хочет зависеть от OpenAI
Сэм Альтман устал от вопросов о деньгах OpenAI
ИИ берет на себя рутину в науке
Глава Nvidia считает, что ИИ-пузыря - нет
ООН для искусственного интеллекта откладывается
Гуманоиды заменят рабочих на заводе
Как в 1950 году Тьюринг предсказал, что машины научатся имитировать люде
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2

Развиваем скилы в профессиональной сфере — промт для прокачки навыков
Промт, который поможет автоматизировать рутину, заметить куда расти как специалисту и как отслеживать эффективность.

Запрос
Представь, что ты — гибрид опытного бизнес-аналитика и карьерного коуча.
Твоя задача — помочь мне стать более эффективным специалистом в моей профессии.
Мои данные:
- Моя профессия: [УКАЖИТЕ ПРОФЕССИЮ, например: SMM-менеджер, менеджер по продажам, HR-рекрутер, логист]
- Мои 3-5 ключевых ежедневных задач: [ПЕРЕЧИСЛИТЕ ЗАДАЧИ, например: 1. Составление контент-плана в таблице. 2. Сбор статистики по охватам постов. 3. Расчет бюджета на рекламу. 4. Анализ активности конкурентов.]
- Главная цель моей работы: [ОПИШИТЕ ЦЕЛЬ, например: Увеличить вовлеченность подписчиков и привести N заявок в месяц.]
Основываясь на этой информации, предоставь мне структурированный план улучшений:
1. Формулы для Excel/Google Sheets:
Предложи 5 конкретных и полезных формул, которые помогут мне автоматизировать мои задачи. Для каждой формулы укажи:
- Саму формулу.
- Простое объяснение: что она делает.
- Пример использования в контексте моей работы.
2. Точки Роста:
Дай 3-4 неочевидные рекомендации для моего профессионального развития. Они должны касаться:
- Одного hard skill (конкретный технический навык).
- Одного soft skill (гибкий навык, например, коммуникация).
- Одного технологического инструмента или сервиса (кроме нейросетей), который стоит освоить.
3. Идея для Персонального Дашборда:
Опиши концепцию простого дашборда в Google Sheets, который я мог(ла) бы собрать для отслеживания своей эффективности. Укажи:
- Какие 3-5 ключевых метрик (KPI) мне стоит отслеживать.
- Какие графики или диаграммы лучше использовать для визуализации.
- Как этот дашборд поможет мне принимать более взвешенные решения в работе.
Канал про ИИ, публикую подборки, гайды понятным языком, мнения — интересный и полезный контент.
Каждый найдет как сэкономить время и увеличить продуктивность с нейросетями — ссылка в профиле пикабу )
Показать полностью
1
Один пост, чтобы обрести силу… или разбираемся в промптах, чтобы научиться их писать раз и навсегда

Рассказываю как - в этой статье.
В последнее время расплодилось каналов с псевдоэкспертами по промпт-инжинирингу. Но цель у них одна — зарабатывать на вашем внимании, втюхивая вам сгенерированные в тех же LLM промпты как нечто волшебное и уникальное. Здесь мы такое не одобряем!
Давайте-ка один раз хорошенько разберём, как работают промпты и как их писать. Я намеренно не буду грузить вас заумными терминами, так как именно их используют как завесу из магической пыли вокруг этой темы. Моя же цель — рассказать все максимально просто.
Сначала база — что такое промпт?
Промпт — это вопрос, инструкция или просто набор слов/символов, который вы отправляете любой LLM и ждёте ответа.
Промпт бывает системный и обычный.
Системный — выставляется один раз надолго, как настройка.
Обычный — это ваш диалог с моделью. Каждая новая фраза — тоже промпт.
По сути, оба типа склеиваются и передаются в модель вместе с историей вашего диалога.
Но что такое промпт для модели? Представьте, что модель — это собака 🐕. Она не понимает ваших слов, слышит только звуки. Но если её надрессировали, у неё есть ассоциации: вы говорите «голос» → собака гавкает → получает вкусняшку. С моделью всё так же: вы даёте слова, а она ищет у себя в «мозгах», с чем она их ассоциировала во время тренировки и получала за это вкусняшку, и возвращает это вам.
Например: «Разговаривай как мастер Йода». И это отправляет ее к конкретным ассоциациям. Чем точнее и детальнее вы направите её в нужный уголок векторного пространства, тем лучше получите ответ, потому что она будет искать в нужном месте. Если направите плохо — это может приводить к галлюцинациям, о чем я писал в этом посте.
К тому же модели дополнительно обучают следовать инструкциям, чтобы модель не просто возвращала ассоциации с Йодой, а понимала, что именно вы от неё хотите.
Так как же писать те самые «волшебные промпты»?
Во-первых, легко! Нет никаких «волшебных» и «тех самых» промптов. К тому же, модели специально сейчас обучают в процессе «ризонинга» первым шагом улучшать ваш промпт. То есть модель сама улучшает под себя запрос. И она умеет это лучше тех «гуру», которые это повсюду втюхивают.
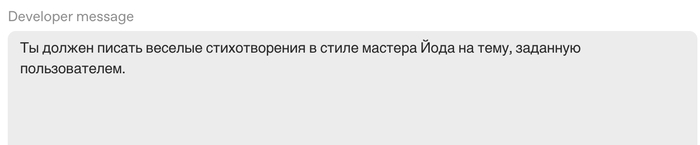
Так выглядит промпт до оптимизации.

А вот так он оптимизируется с помощью тула от OpenAI. Сервис расписывает обоснования для всех изменений, которые он внес - благодаря чему можно качать свою промптовую мышцу (ссылка на сервис ниже в статье).
Во-вторых, есть общие подходы:
обозначьте роль/персону модели (как она должна отвечать)
укажите стиль и формат (коротко, формально, весело, буллетами…)
сформулируйте задачу (что именно нужно сделать: написать стих, найти инфу, сгенерить код)
дайте контекст (на что опираться: интернет, загруженный файл, стихи Пушкина и т. д.)
Опционально:
отрицательный промпт (что не делать)
формат входных и выходных данных (если их нужно жестко задать)
пример результата (сильный якорь для модели, поэтому показывайте то, что вам реально нужно).
Все эти элементы можно зашить в системный промпт. А дальше — просто ведите диалог.
В-третьих, используйте рекомендации от создателей конкретных моделей.
... и другие выпускают свои рекомендации, как писать промпт для их моделей. К ним стоит прислушаться, так как они тренируют модели на конкретных шаблонах. Знаете их — понимаете лучше, какие ассоциации зашиты в модель.
Кстати, если вас смущает английский язык гайдов — очевидно, закиньте эти гайды в любимую нейросетку и попросите перевести (можно без замудреных промптов 😉).
В-четвертых, используйте сами LLM для написания промптов. Они это делают лучше людей. Кстати OpenAI даже сделали специальный инструмент для этого. С помощью него вы можете тренироваться писать крутые промпты, ну или просто оптимизировать, когда не хочется самим заморачиваться.
Ну а если вы матерый датасаентист, который строит агентную систему, то вам нужно пробовать использовать автоматический оптимизатор промптов. Например, от OpenAI или от Google.

ну может не совсем, но промпты теперь пишешь очень круто 😎
Итого: вжух! — и за один пост вы освоили промпт-инжиниринг на уровне выше среднего юзера. А если прочитали инструкции от вендоров — то уже на уровне промпт-инженера. Для большинства этого с головой хватит для получения шикарных результатов от современных моделей.
Подписывайся на мой телеграм канал Заместители, где мы обсуждаем самое важно про ИИ агентов без инфошума. Там короткие версии статей выходят раньше, чем на других площадках!
Показать полностью
3
GPT-5.1 можно попробовать уже сейчас
На портале Design Arena появились четыре секретные модели с названиями willow, cedar, birch и oak. Разработчик официально не раскрывается.
Но есть способ узнать правду. Если попросить ИИ создать сайт про самого себя, то он раскрывает информацию, из которой ясно, что речь идёт о модели от OpenAI.
Характеристики выдают подробности. Параметр knowledge cutoff - дата, по которую у модели есть знания без интернета - указан как октябрь 2024 года. Такой же, как у линейки GPT-5».
Что это за четыре модели? Либо «GPT-5 с разной настройкой режима рассуждений или GPT-5 в вариантах Instant/Mini/Thinking/Pro». И кстати, упоминания GPT-5.1 ранее встречались в коде приложений OpenAI - так что это может быть возможным именем обновлённой модели.
Попробовал пару раз - увы, не впечатляет. Может будут подкручивать ещё.
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью