
Закреплено

Искусственный интеллект
5 056 постов
•
11 479 подписчиков
0 просмотренных постов скрыто


Читаете полезную литературу? Улучшите опыт с нейросетью!
Нейросети способны на многое — от генерации видео до помощи в работе и повседневных задачах. Главное — не позволять ИИ полностью управлять вашей жизнью.
Пример: Сейчас в чтении — «Красная таблетка 2» о нейрофизиологии мозга. Первая часть кажется скучной: много воды и знакомых экспериментов. Но с помощью DeepSeek вторая часть становится гораздо интереснее.
Как это работает:
Прочитать главу самостоятельно, уловить суть.
Скопировать текст или кратко пересказать ИИ, попросить сжать до ключевых идей.
Выжимка — это удобно, но недостаточно для глубокого понимания. К тому же, слепо доверять автору неразумно. Можно поручить ИИ проверить факты.
Самый ценный этап: загрузить в нейросеть свои данные — проблемы, страхи, размышления. Попросить ИИ адаптировать главу под ваш опыт. Теперь это не абстрактная теория, а персонализированный анализ.
Дополнительно: раз в несколько глав можно создать мини-историю, где вы — главный герой, а автор и ИИ — персонажи. Получается наглядная иллюстрация материала с индивидуальными выводами.
Показать полностью

ChatGPT станет репетитором, ИИ помог, врачи 10 лет - нет, ИИ уволил 94 000 людей
Привет! С вами ежедневные новости искусственного интеллекта от AIvengo. И сегодня у нас в выпуске:
OpenAI тестирует режим персонального репетитора "Study Together" для ChatGPT
Уимблдон заменил всех линейных судей на ИИ несмотря на 148 лет традиций
Обучение ИИ математике делает его умнее на 80%
И другие интересные новости про ИИ.

Как я управляю своим таск трекером TickTick через Claude
В продолжении серии постов про Claude Desktop MCP Servers
В этом посте расскажу про первый из 4 серверов, с которыми работаю
Вот какие MCP сервера подключены у меня
🟢 TickTick — мой таск трекер (на чтение и на запись)
🟢 Notion (на чтение и на запись)
🟢 GitHub (на чтение и на запись)
🟢 Google Analytics 4 (только на чтение)
------------
------------
В этом посте коротко расскажу про Tick Tick MCP
TickTick — это мой таск трекер. Типо ToDoist

Я пользуюсь им для ведения своих задач. Так как работаю я сам на себя, то трекер это важная часть моей жизни, который у меня в основном выглядит вот так
Первый MCP, с которого я начал свое изучение этой темы — Tick Tick MCP
Было интересно сделать себе мини ассистента
Как это работает
У меня есть чат в Claude Desktop, в контекст которого вгружена роль Claude в этом диалоге
Затем в этот чат я пишу, что я хочу, Claude сам понимает, хочу ли я обратиться к TickTick или просто спрашиваю что-то. Если из контекста он понимает, что нужно использовать TickTick, то он вызывает ту функцию, которую примерно определил
Что умеет мой MCP TickTick
Ставить задачи, можно даже на конкретное время
Удалять задачи, переносить задачи
Добавлять описание задачам
Создавать / удалять проекты, группировать задачи по проектам
В среднем, каждый MCP умеет делать то, что в нем написали. И то, насколько богатое API есть у сервиса, к которому будет подключен наш MCP.
Разные энтузиасты могут написать различные MCP для одного и того же сервиса. И все они будут разного уровня глубины и проработки
Какие основные кейсы при работе с TickTick MCP есть у меня
Почти каждую неделю я планирую в воскресенье вечером. Этот процесс у меня в основном происходит внутри ChatGPT, чтобы он был в контексте моих планов
Затем, я закидываю получившийся план в Claude, и прошу поставить мне эти задачи на неделю через TickTick, например, через такой промпт
Вот мой список задач на неделю.
К каждой задаче поставь Start Date и End Date в течении следующих 7 дней, учитывая их приоритет.
Выполнение каждой задачи в этом списке в среднем должно занимать не больше 3 часов.
После каждой задачи ставь буфер в 40 минут. Для каждой задачи можешь примерно добавить Definition of Done
Учти, что сейчас я живу в Бангкоке, работаю в среднем с 12 дня до 10 вечера. Суббота и Воскресенье -- не нагружай меня больше чем на 4 часа работы
Старайся не допускать накладывания задач на уже существующие задачиСначала напиши список и скинь в чат, а затем, после моего аппрува, добавь в TickTick
Это самый частый кейс ⤴️
Иногда закидываю в него разовые задачи
Например, я в Spotify увидел, что недалеко от меня через 2 месяца будет концерт. Я скинул скрин в Claude и попросил, чтобы он собрал инфу о билетах и поставил напоминалку через пару недель
Он задействовал свой deep research и все собрал в задачу. Я потом просто перейду по ссылке и куплю

Или, например
Мне нужно купить новые кроссовки в диапазоне 200$, скорее всего найк
Поставь это в задачи, и перед этим проанализируй их модельный ряд, сравни с NB, PUMA и Adidas. Выбери топ 3 под мой запрос -- бег по городу, 5-6км в среднем. А затем глянь, есть ли они в Бангкоке
И оформи в задачу, чтобы я через неделю сгонял в магазин
---------
Пока на этом все
Такие черновые посты помогают мне написать большую статью
А вот тут в более удобном интерфейсе
o((>ω< ))o
Показать полностью
2
OpenAI наняла психиатра, учёные манипулируют ИИ, уволенных ИИ послали в ИИ
Привет! С вами ежедневные новости искусственного интеллекта от AIvengo. И сегодня у нас в выпуске:
Внешность и голос людей защитят авторским правом от дипфейков
9000 человек уволили из Xbox из-за искуссвенного интеллекта
Стартовые вакансии сократились на 32% после появления ChatGPT
И другие интересные новости про ИИ.

Прошу помощи в поиске или создании
Товарищи знатоки и лучшие траеры континета! Прошу вашего участия в ситуации 😅 На одном хостинге с устаревшим оборудованием нашёл канал человека, который меня очень восхитил контентом и уже длительное время пересматриваю его ролики и очень кайфую с одной его песни. В комментариях к ролику узнал, что сделали её с помощью ИИ, автор не светился в ответах и инфы нет. Если у Вас есть возможность и опыт, подскажите пожалуйста, с помощью какой модели или сервиса могли собрать трек, мне очень хочется им восхититься и поделиться с другими ценителями, заранее спасибо!
По тайм коду 24:00, к ссылке время не прикрутилось, смотрю с телефона, так как ноут сгорел🤦♂️

Мой Телеграм бот как хобби вышедшее из под контроля1
Все же хочется поделиться своими "рукоделиями" с народом. Я бывает страдаю всякой всячиной, чтобы мозги не заржавели. Вот и решил я тут сделать бота в Телеграм. Даже сам бот брал свое начало как эксперемент, а не как готовый проект. Плюс ко всему мне любопытно изучать способы практического применения нейросетей и машинного обучения. Сначала я просто привязывал к боту всякие разные мелкие модели нейронок, просто как служебные, TTS (текст в голос) и наоборот, голос в текст. Изучал всякие подходы к тренировке или дообучению, и наконец просто пробовал всякое на своем боте. Сейчас наверное ботов "интерфейсов" для нейронок много, но я и не хотел "просто интерфейс", как я уже писал я хочу понять возможности практического применения.
Первый "звоночек" о том что я получил что-то интересное у меня случился когда я прикрутил интерфейс DeepSeek. Я сразу решил, что раз у меня есть возможность переводить текст в голос и голос в текст, то надо это замутить с DeepSeek. (напомню, я делал это все просто по приколу). И вот я в какой-то момент смотрю, что я предпочитаю просто ГОВОРИТЬ с чат ботом. Про всякое, то про музыку, как выбрать треки для прослушивания на основе того что я предпочитаю (я реально описываю эмоции, описываю настроение и все такое, и он предлагает то что надо). Так вот, я просто иду по улице и записываю голосовухи для бота, и бот мне отвечает. Со стороны похоже что я просто общаюсь с человеком. Это прикольно и удобно, я этого сам не ожидал.
Неожиданным плюсом стало то, что я могу отправить голосовуху и не ждать пока бот сгенерирует ответ (классическое приложение потухает при блокировке экрана и не генерирует ничего) а тут просто отправил голосовуху, и хоть блокируй телефон, все делается в фоне.
Я все-же не особо представлял четкий путь развития, только что-то абстрактное, типа Практическое применение.
Ну и совершенно не ясным мне образом, я решил что мне надо прикрутить нейронку идентификатор растений. Убил неделю на обучение. Это был прикольный опыт. Поняв что на имеющихся мощностях мне обучение не светит, я арендовал сервер с специальными вычислителями от Nvidia. Помаялся там несколько дней, и понял что за разумные сроки я не смогу обучить нейронку хотя-бы на 90 миллионов параметров. Подумал что потратить 60-90К на эксперемент я пока не готов😁 и отложил это дело на попозже. довольствуясь обученными моделями. В итоге прикрутил две нейронки, обученные на двух крупных датасетах. и оно заработало... Прикольно, весело. Я сфоткал все клумбы в округе, а когда выбирались на всякие шашлындосы или типа того, я тоже фоткал и идентифицировал все что попадалось незнакомое)
А потом пришло осознание - надо подключать DeepSeek к идентификации. Ну точнее чтобы он рассказал мне про растение. Я представлял себе это как что-то типа википедии. Помаявшись вечерок-другой, я наконец получил рабочий вариант, и то что получил, оказалось даже лучше моих ожиданий.
Я тестировал бот на растениях найденных при недавней поездке на морские посиделки


Интересный экземпляр
И вот немного переписки
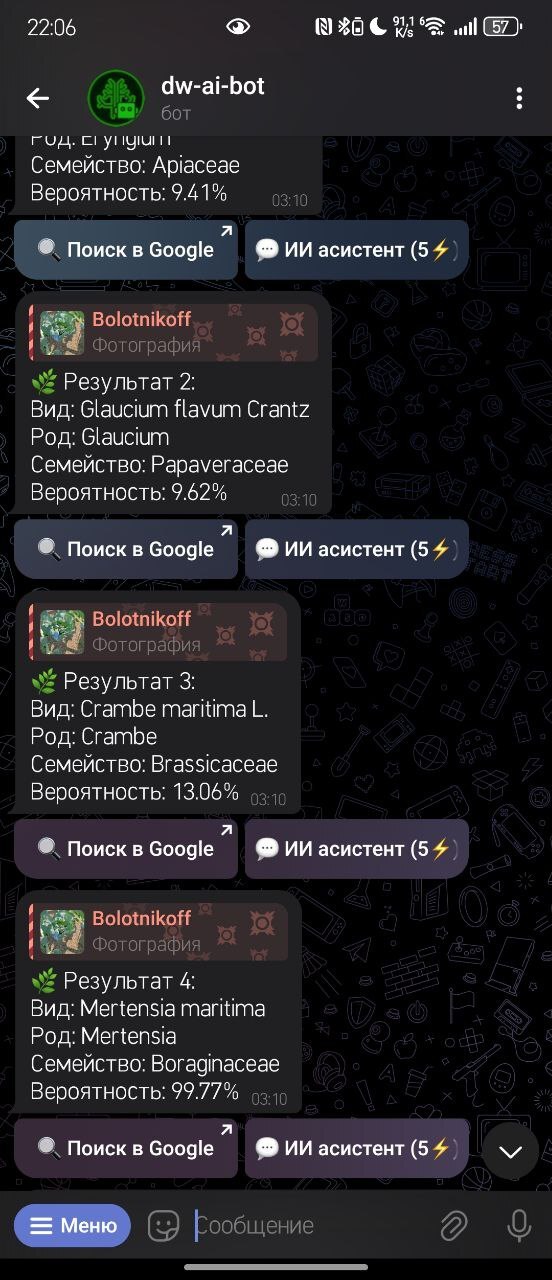
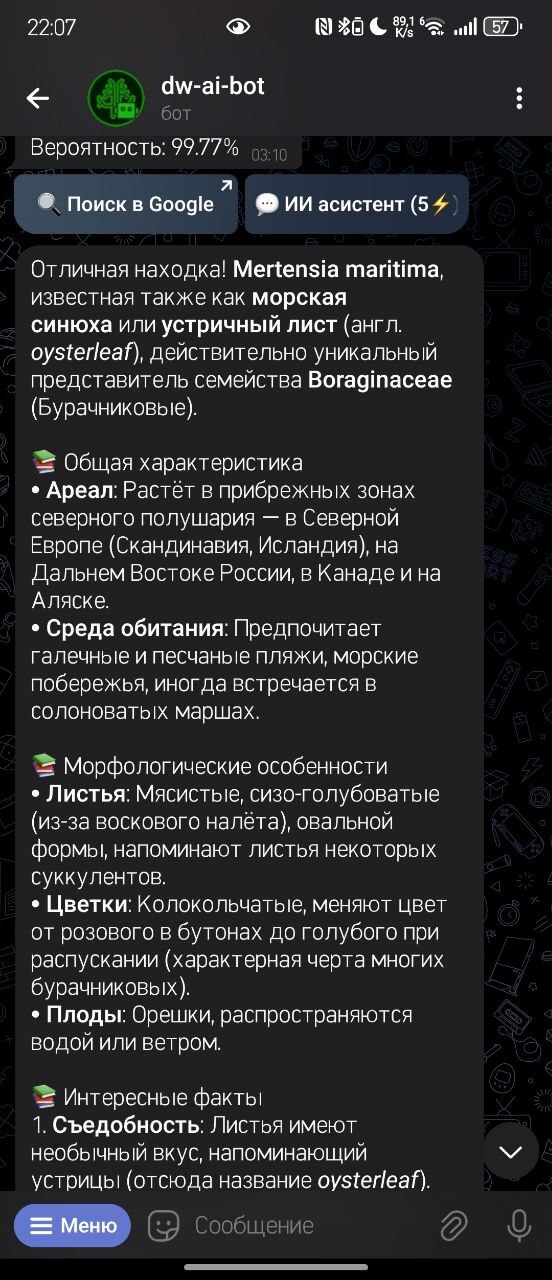

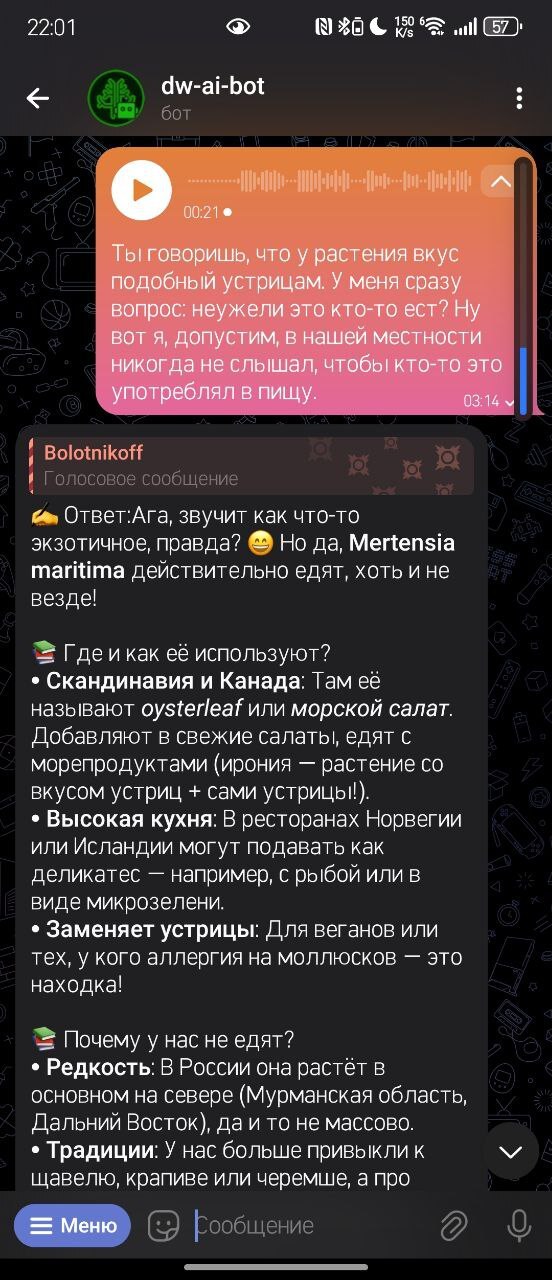
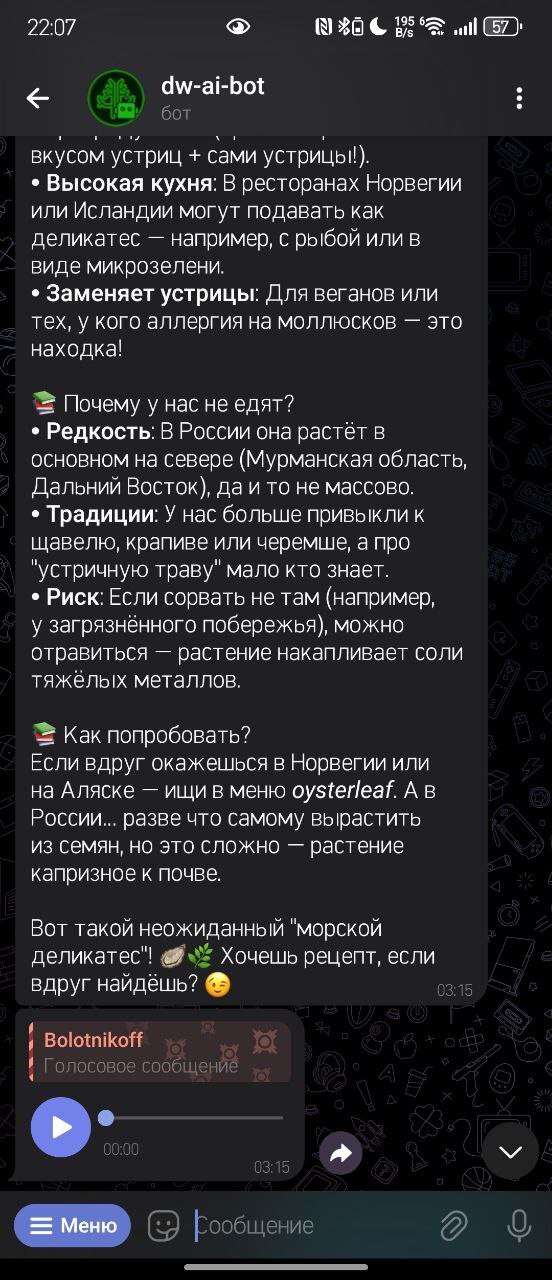
Обратите внимание, при необходимости бот дублирует текст в голосовом сообщении
Итак, зная что БЯМы (большие голосовые модели) могут по приврать, я подумал что это очередной глюк про съедобность. На википедии я не нашел про это инфу. Но я решил загуглить именно Oysterleaf. И что в итоге, да, есть куча статей не в русском сегменте о выращивании и сборе листьев для салата... Меня это поразило, потому что, как я писал уже, на вики этого нет. А я видел это растение с самого детства, и не догадывался даже. Сейчас правда я не совсем у моря живу, надо часик-другой ехать, и пока я не собираюсь на то побережье где растут эти растения... но еще не вечер, так что если поддержите пост лайками, я сделаю из него салат и запишу об этом видос (блин, да я походу и так запишу, мне капец как любопытно)
ПОМНИТЕ - Нейронные сети могут ошибаться. Проверяйте информацию!
Зачем же собственно я пишу это все. Да просто потому что во-первых хочу поделится, а во-вторых, для развития бота в направлении Практического использования, нужно не только мое мнение, нужно опыт использования разных людей. Ну и плюс, бот возможно реально будет полезен
P.S. Я планирую еще прикручивать штуки, к примеру запланировано прикрутить GPT и сделать бесшовную смену БЯМ прямо в диалоге, возможно даже устроить тройничок в диалоге, чтоб все участвовали, и пользователь, и DeepSeek и GPT, но пока не знаю как это распределить, обдумываю. Ну а т.к. для работы с GPT нужно VPN, то я еще и его сделал на WireGuard. По просьбам трудящихся могу еще какой протокол прикрутить...
Показать полностью
7

Нейросетевое безумие
*** *Сижу, читаю Пикабу (да и другие площадки), и всё чаще ловлю себя на мысли: "Это же нейросеть написала, да?"*
*** Фразы вроде правильные, но какие-то... бездушные. Всё по одному шаблону. Заезды в начале текста, будто это писал DeepSeek. Какие то слова через чур подозрительные.. тексты, в общем и целом, кажутся странными. Как будто автор не человек, а алгоритм, который прочитал миллион постов и теперь пытается имитировать "живое" общение. И самое жуткое — иногда даже не поймёшь, где реальный человек, а где нейросеть. Реально ведь жутко, не находите?
Мемы, статьи, обсуждения — всё как будто слегка "не то".
Может, я параною, но становится немного не по себе. Интернет превращается в море текстов, написанных ботами для ботов. Авторам просто лень писать своё. А мы просто листаем, листаем, листаем...
**Вот и вопрос: вы тоже замечаете это? Или это я один уже не отличаю людей от нейросетей?.. 🤖**

SemDiD - новы метод, который раскрывает скрытые оси мышления LLM — никакого копипаста
Исследователи из из Гонконгского университета и инженеры Alibaba научили LLM генерировать семантически разные ответы, заставляя их «думать» в ортогональных направлениях.
Наверняка каждый, кто работает с LLM, сталкивался с их любовью к самоповторам. Запрашиваешь несколько вариантов решения, а получаешь одну и ту же мысль, просто перефразированную.

Стандартные подходы к декодированию, temperature sampling или diverse beam search, создают лишь лексическое разнообразие, но пасуют, когда требуется семантическое. Это серьезная проблема для Best-of-N или RLHF. Ведь без по-настоящему разных идей и подходов к решению задачи эти методы теряют свою силу: выбирать лучший вариант не из чего, а обучать модель на однотипных примерах неэффективно.
Решение предложили в методе SemDiD (https://arxiv.org/pdf/2506.23601) (Semantic-guided Diverse Decoding). Его суть, если кратко, перестать играть с токенами на поверхности и начать управлять генерацией напрямую в пространстве эмбеддингов.
🟡Метод работает так.
Сначала, на старте, он принудительно направляет разные группы beams по ортогональным векторам в семантическом пространстве. Грубо говоря, это как дать команду разным поисковым группам двигаться строго на север, юг и запад, чтобы они гарантированно разошлись.
По мере генерации, когда жесткие директивы могут стать неоптимальными, включается второй механизм - inter-group repulsion. Он просто следит, чтобы смысловые траектории ответов не сближались, сохраняя их уникальность до самого конца.
Но как, гоняясь за разнообразием, не получить на выходе бессвязный бред?
SemDiD подходит к контролю качества уникально. Он не пытается слепо максимизировать вероятность последовательности, а использует ее лишь как нижнюю границу, чтобы отсечь совсем уж плохие варианты.
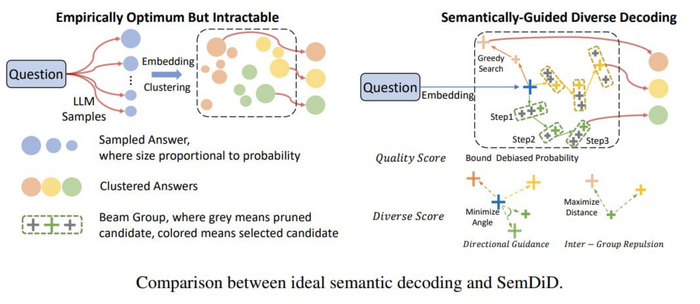
Кроме того, алгоритм корректирует системные искажения, когда вероятность токенов искусственно завышается в зависимости от их позиции в тексте.
Для баланса между качеством и разнообразием используется адаптивный механизм на основе гармонического среднего, который в каждый момент времени уделяет больше внимания той метрике, которая проседает.
🟡В тестах метод показал неплохие результаты.
На бенчмарках для Best-of-N, от MMLU-Pro+ до GSM8K, SemDiD увеличивает покрытие (шанс найти верный ответ) на 1.4%-5.2% по сравнению с аналогами.
🟡Но главный прорыв - в RLHF.
Генерируя для GRPO или RLOO семантически богатые наборы ответов, SemDiD предоставляет им более качественный материал для обучения. Это ускоряет сходимость на 15% и повышает финальную точность моделей.
🟡Arxiv (https://arxiv.org/pdf/2506.23601)
#AI #ML #LLM #SemDiD
Показать полностью
2