
Закреплено

Искусственный интеллект
5 075 постов
•
11 487 подписчиков
0 просмотренных постов скрыто


Большие поведенческие модели (LBM): новый этап в развитии ИИ

Представьте робота, который изучает, как вы готовите еду, и с каждым приготовленным вами блюдом он сам становится всё более искусным поваром. Разбираемся, как большие поведенческие модели (LBM) помогут роботу в этом деле.
Несмотря на впечатляющие достижения больших языковых моделей (LLM) в обработке и генерации текста, они не умеют обрабатывать изображения или сенсорные данные, необходимые роботу для ориентации в физическом пространстве, “понимания” объектов и обучения действиям пользователя. Так Visual Language Models (VLM), обрабатывающие визуальные данные, могут “понимать” содержимое изображений и отвечать на вопросы по изображениям.
Large Action Models (LAM) обучены на данных о действиях (в том числе из сенсоров). LAM превращают LLM в автономных агентов, способных выполнять комплексные задачи, ориентированные на вызов определённых функций, улучшенное понимание и планирование.Salesforce уже начали выпускать такие модели для автоматизации процессов.
Visual Language Action Models (VLA) обучены на визуальных данных и данных о действиях. Они дают LLM возможность быть “воплощённым” агентом (Embodied Agent) в физическом мире. Например, RT-2 демонстрирует способность робота выполнять сложные команды благодаря использованию цепочки рассуждений. PaLM-E — мультимодальная языковая модель с 562 миллиардами параметров, демонстрирующая высокую универсальность и эффективность. А OpenVLA — открытая модель с 7 миллиардами параметров поддерживает управление несколькими роботами одновременно.
Для обучения агентов применяется обучение с подкреплением. Существуют различные RL-методы, но в целом обучение агента построено на политике вознаграждений и наказаний за совершение определённых действий. Среди RL-методов также есть обучение с подкреплением на основе обратной связи от пользователя.
Комплексно задачу по обучению роботов действиям человека решают LBM (Large Behavior Models) — большие мультимодальные поведенческие модели, представляющие новое направление в ИИ. LBM направлены на понимание, моделирование, адаптивное обучение и генерацию человеческого поведения в физическом мире (похоже на RLHF на основе данных из физического мира).
Большие поведенческие модели уже используются на практике:
1. В Lirio разработали первую в мире LBM для здравоохранения. Их модель создаёт гиперперсонализированные рекомендации для пациентов на основе медицинских данных и данных о поведении пациента от различных датчиков.
2. Toyota Research Institute совершил прорыв в обучении роботов новым сложным навыкам с помощью метода Diffusion Policy. Их роботы могут быстро осваивать новые действия, такие как наливание жидкостей или использование инструментов, без необходимости перепрограммирования.
3. Стартап Physical Intelligence привлёк $400 миллионов инвестиций от Джеффа Безоса, OpenAI и других крупных игроков. Они стремятся создать роботов, которые смогут выполнять любые задачи по запросу пользователя, будь то уборка, сборка мебели или обслуживание клиентов.
Однако, как отмечал философ Людвиг Витгенштейн в своём "Логико-философском трактате": "Границы моего языка означают границы моего мира". Это актуально для LBM, так как они всё ещё ограничены данными, на которых обучены. Их "мир" определяется теми модальностями, что они могут воспринимать через сенсоры и понимать с помощью алгоритмов.
Для обучения качественной поведенческой модели нужно больше датчиков для сбора данных из различных модальностей. Так данные электроэнцефалографа позволили бы лучше распознавать и имитировать эмоции. А обучение моделей с помощью синтетических данных из симуляций делает "картину мира" LBM более разнообразной.
В реальном мире мы пока можем отличить робота от человека. Но возникает вопрос: а как мы будем отличать человеческое поведение от ИИ в цифровом мире?
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Показать полностью
1

Вопрос к специалистам ИИ
Всем доброго времени суток! Подскажите возможно ли дообучить LLM такую как deepseek на пользовательских данных (данные которых нет в интернете, данные на которых почему то не обучали LLM) ?
Есть ли для этого инструменты доступные не специалистам или за такой задачей нужно обращаться в сбер или яндекс?

ИИ-ассистент для кодеров
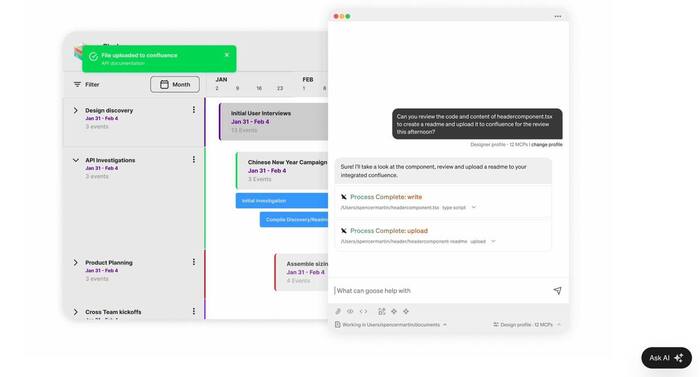
ИИ-ассистент для кодеров от основателя Твиттера — Джек Дорси дропнул Goose, который заберет ВСЮ рутину кодеров и сократит даже самые сложные задачи до пары минут.
• Нейропомощник пишет ЛЮБЫЕ программы за один промпт, САМ меняет код в файлах, тестирует скрипты, делает СКРИНШОТЫ, фиксит баги.
• Работает полностью локально — никакие данные не просочатся в сеть.
• За секунду подключается к GitHub, Google Drive, всем популярным IDE и другим инструментам.
• На выбор целая куча LLM.
• Ограничений — НЕТ. Подключаем ассистента к любым серверам и API.
Показать полностью
Может ли ИИ помочь нам стать счастливее?

Нобелевский лауреат по физике Лев Ландау считал, что быть счастливым — это обязанность каждого человека. Но что значит «быть счастливым»?
С точки зрения нейрофизиологии, в моменты счастья у нас вырабатываются серотонин, дофамин и эндорфины. Но на биохимическом уровне история не заканчивается: если в жизни есть хронический стресс, отсутствие социальных связей и негативные установки, «укол эндорфинов» дает лишь кратковременный эффект. Именно поэтому так важен комплексный подход — от мыслей и привычек до физических нагрузок и здоровых отношений.
Хотя базовый уровень счастья предопределен генетически, все же интересно провести эксперимент с целью проверить, сможет ли ИИ помочь нам стать чуть счастливее. Для этого я разработал Landao AI — бесплатного ИИ-коуча по счастью.
Landao AI предлагает годовой курс по практике стоицизма с ежедневными уроками. Стоицизм — древнегреческая философия, которая помогает отделять внешние обстоятельства от нашей реакции на них. Стоики учили, что «страдания порождаются скорее нашими суждениями, чем самими событиями». А еще призывали отличать то, на что мы можем повлиять (собственные мысли и поступки), от того, что нам неподвластно (погода, слова других людей, репутация). Практики стоицизма позволяют сохранять спокойствие, не зацикливаться на негативе и жить более осмысленно.
Вторая важная функция ИИ-коуча — побуждение к самоанализу и возможность смотреть на свои мысли в формате когнитивно-поведенческой терапии (КПТ). КПТ основывается на идее, что наши эмоции и действия во многом зависят от мыслей, которые мы не всегда осознаем — так называемых «автоматических мыслей», которые нужно проверять на «реальность» и заменять более конструктивными. Этот подход давно и успешно применяется психологами: он помогает снизить тревожность, избавиться от непродуктивных шаблонов мышления и, как следствие, повысить общий уровень счастья.
ИИ-коуч предоставляет возможность анонимно делиться своими эмоциями, получать поддержку от других людей и знакомиться с единомышленниками. Согласно «Гарвардскому исследованию счастья», которое ведется с 1938 года, ключевым фактором счастья оказались не деньги и не громкие достижения, а социальные связи. Исследователи наблюдали за 724 участниками, собирали медицинские данные, разговаривали с семьями испытуемых и выяснили, что люди с крепкими социальными связями более здоровы, дольше живут и в целом ощущают себя счастливее.
В планах — расширение функционала в сторону дейтинга и нетворкинга, ведь, по мнению Ландау, счастье складывается из трех главных слагаемых: работа, любовь и общение с людьми.
Нельзя забывать и о том, как влияет на наше самочувствие и другие факторы:
Физические нагрузки и прогулки на свежем воздухе помогают «выключать» стресс-реакцию и восстанавливать нервную систему.
Здоровый сон: хронический недосып — прямой путь к выгоранию.
Питание: равномерное снабжение мозга питательными веществами связано с когнитивной устойчивостью.
Цифровой детокс: хотя бы 15–30 минут в день без гаджетов — маленькая, но мощная перезагрузка для мозга.
Отделять эмоции от внешних обстоятельств — важный навык для человека любой эпохи. Надеюсь, в совокупности с другими методами ИИ-коуч поможет многим людям. Главное, помните: ИИ — лишь помощник. Главная работа происходит в ваших мыслях, привычках и повседневных решениях. Но с хорошим коучем этот путь пройти легче и интереснее.
Я уже использую Landao AI и собираю обратную связь от первых участников. Приглашаю и вас присоединиться к эксперименту по ссылке, буду рад обратной связи. Помогает ли регулярная «инъекция» стоицизма и КПТ стать чуть счастливее?
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Показать полностью
Большой потенциал малых языковых моделей
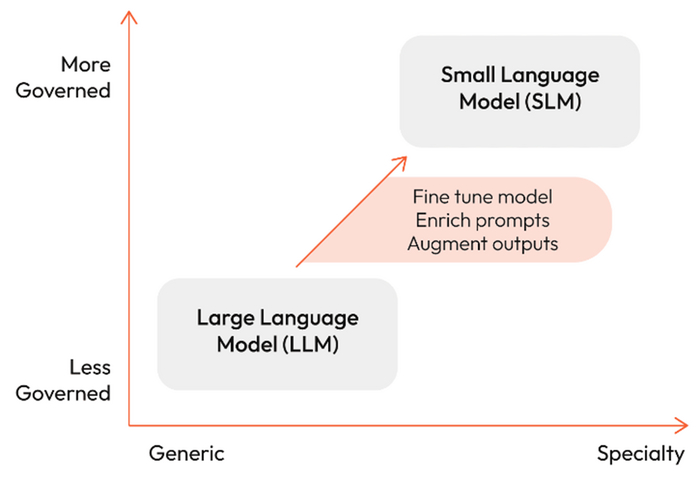
Современный бум ИИ уже давно не сводится к крупным разработкам от гигантов вроде OpenAI или Anthropic, инвестирующих миллиарды в большие языковые модели. Наоборот, всё чаще в фокус внимания попадают малые языковые модели (Small Language Models, SLMs), способные решать узкоспециализированные задачи не хуже (а порой и лучше) своих «старших собратьев».
Яркий пример — стартап Patronus AI со своей моделью Glider, имеющей 3,8 миллиарда параметров. Большинство компаний применяют для оценки своих продуктов большие закрытые модели вроде GPT-4. Но это дорого, не всегда прозрачно и несет риски для конфиденциальности. Glider же, будучи относительно компактной, способна работать на более простом «железе» и при этом давать детальное объяснение своих оценок по сотням критериев (точность, безопасность, стиль, тон и т. д.).
По результатам тестов Glider превосходит GPT-4o mini по нескольким метрикам и отвечает в среднем менее чем за секунду, что делает ее практически идеальным решением для генерации текста в реальном времени.
Большие языковые модели, безусловно, продолжают впечатлять своей универсальностью, но их недостатки очевидны:
- Высокие затраты на ресурсы. Обучение и инференс больших моделей требуют колоссальных вычислительных мощностей, что приводит к дополнительным расходам на инфраструктуру, электроэнергию и обслуживание;
- Низкая конфиденциальность. Использование больших закрытых моделей предполагает отправку данных во внешний облачный сервис, что критично для финансовых организаций и здравоохранения;
- Зависимость от интернета. При отсутствии доступа к сети такие модели попросту недоступны;
Малые языковые модели, напротив, легко разворачиваются на локальном сервере или даже на обычном пользовательском устройстве, снижая задержки при ответах и повышая контроль над безопасностью. Им не нужны сотни гигабайт видеопамяти, а адаптация к узконаправленной задаче и интеграция в собственную инфраструктуру обходятся заметно дешевле и проще. Дополнительно малые модели экономят электроэнергию и бережнее относятся к экологии.
Малые языковые модели можно либо обучать с нуля под конкретную задачу, либо «сжимать» уже готовые большие модели, используя методы прунинга, квантизации и дистилляции знаний, сохраняя высокое качество при сокращении числа параметров.
Набирают популярность и гибридные системы, в которых несколько малых моделей берут на себя простые запросы, а большая модель выступает их «роутером» и используется для более сложных задач.
Помимо Glider, существуют такие модели, как Gemma (Google), GPT-4o mini (OpenAI), Ministral (Mistral AI), Phi (Microsoft) и Llama 3.2 (Meta). Все они ориентированы на локальное использование в задачах, где высоки требования к приватности и быстроте отклика.
Малые языковые модели незаменимы там, где требуется локальная обработка данных: в медицине (электронные записи пациентов, выписки, рецепты) или финансовой сфере (работа с регулятивными документами). Их размер снижает риск «галлюцинаций», помогает быстрее достичь высоких результатов в узкоспециализированных областях и защищает конфиденциальную информацию.
В действительности большие и малые языковые модели — это две параллельные ветви эволюции, которые не исключают, а взаимно дополняют друг друга. Большие модели лучше справляются с универсальными задачами, требующими миллиарды параметров и богатого контекста, а малые эффективнее работают над узкоспециализированными кейсами, обеспечивая локальную приватность и минимизируя затраты.
В ближайшие годы мы увидим стремительный рост гибридных решений, где оба типа моделей будут работать вместе. В результате мы получим еще более умные, надежные и быстрые ИИ-сервисы, способные удовлетворить самые разнообразные потребности практически любого бизнеса.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Показать полностью

Чудо-машина

Показать полностью
1

Нейросеть vs Экскаватор
Видели это море коротких видео роликов как экскаваторщики виртуозно копают траншеи?
Чем больше таких роликов они снимают, тем раньше появится нейросеть которая научится, на этих роликах, все это делать без экскаваторщика и оставит их без работы.

Продолжение игр(и не совсем игр) с нейросетью Яндекс
Продолжение игр с нейросетями: Нейросеть к интеллекту не имеет никакого отношения
На этот раз нейросети был задан вопрос - "использование математической статистики для анализа производительности СУБД PostgreSQL".
Результат получился , скажем так - прикольным.

Прикол в том, что 3 ссылки это ссылки на мои статьи и 2 ссылки это не совсем о мат. статистике и производительности СУБД PostgreSQL.
Очень интересный и многозначительный вывод/вопрос из ответа нейросети - кроме меня никто по теме мат.статистики для анализа производительности не публикуется/не занимается ?

Ну и следствие , описанное ранее, предложенная информация уже устарела . Методика анализа уже другая , но нейросеть об этом ничего пока не знает. Просто не успела обработать статьи на Дзене и Пикабу.
Как было указано ранее - называть интеллектом математические алгоритмы это просто хайп и кликбейт. Интеллект не способный создать новое это не интеллект . Это всего лишь математический алгоритм и не более того.
Но реальный интеллект , не описывается математически .
Показать полностью
1