
Закреплено

Искусственный интеллект
5 063 поста
•
11 479 подписчиков
0 просмотренных постов скрыто

«Балабоба vs ChatGPT: Почему российский ИИ учится молчать, а не говорить»
Привет, пикабушники! Сегодня разберемся, почему наши «Яндекс» и «Сбер», которые ещё вчера хвастались голосовыми помощниками и нейросетями, теперь в тихой панике. Китайский DeepSeek обвалил NASDAQ, а наши ИИ-гиганты… помогают Путину фильтровать вопросы для «Прямой линии». Как так вышло? Давайте по пунктам.
1. Когда «Балабоба» была круче всех (но это не точно)
Помните 2021 год? «Яндекс» выпустил «Балабобу» — нейросеть, которая генерировала тексты в стиле «пьяного философа». Тогда это казалось прорывом. А «Сбер» в 2020-м хвастался RuGPT — моделью, которая умела писать стихи про корпоративы. Но мир уже двигался к ChatGPT, а наши гиганты этого не заметили. Почему?
Железо? Чтобы обучить GPT-3, OpenAI потратила $12 млн и 10 000 видеокарт. У «Яндекса» в лучшие времена было 1600 GPU. После санкций — ещё меньше.
Люди? Лучшие спецы свалили в OpenAI или за границу. Один источник говорит: «Из Яндекса уехали ключевые разработчики LLM. Теперь они учат ИИ за бугром».
Данные? Российский интернет — это SEO-мусор, дубликаты и посты про «кризис». Очистить это — как найти иголку в стоге сена.
2. ChatGPT вскрыл правду: наши модели — как Лада против Tesla
Когда в 2022-м OpenAI выпустила ChatGPT, все ахнули. А «Яндекс» и «Сбер» начали спешно доучивать свои модели. Но:
YaLM от Яндекса (100 млрд параметров) оказалась «сырой». Её даже развернуть на серверах сложно, не то что использовать.
GigaChat от Сбера научился… молчать. Спросите про ЛГБТ или СВО — получите: «Не могу ответить». Зато Путину помогает с «Прямой линией» — видимо, это новый benchmark для ИИ.
3. Санкции vs опенсорс: Русский ИИ переходит на китайские запчасти
Сейчас мир захватили опенсорс-модели вроде DeepSeek или Alibaba. Россияне тоже подключились:
Тинькофф взял китайскую Qwen, дообучил её на русском — получились T-Lite и T-Pro.
Яндекс тайно использует Alibaba в своих проектах — их собственная модель слабее.
Сбер упорно копает своё, но GigaChat даже 2+2 складывает через раз (но зато рисует украинский флаг на запрос «Я люблю Донбасс» — классика!).
4. ИИ-цензура: Как нейросети учатся «не видеть» запретное
Российские ИИ не просто туповаты — они ещё и цензурируются жестче, чем китайские. Примеры:
YandexGPT на вопрос о Путине отправляет читать «Дзен».
GigaChat блокирует даже нейтральные слова вроде «глобальный конфликт».
Kandinsky (нейросеть для генерации картинок) рисует украинский флаг по запросу «Донбасс» — видимо, из чувства юмора.
Почему это проблема? Любое «выравнивание» под ценности делает ИИ глупее. Это как надеть на гончую намордник и ждать, что она выиграет забег.
5. Что дальше? Перспективы российского ИИ — как у пешехода на Формуле-1
Эксперты сходятся во мнении:
Свои модели (как YaLM или GigaChat) останутся нишевыми — для госсектора, где нужно «безопасно молчать».
Опенсорс станет основой. Зачем тратить миллионы на обучение, если можно взять китайскую модель и доучить её на GPU с «Авито»?
Деньги? Инвесторы не горят желанием вкладываться в ИИ, который умеет только цензурить. Зарабатывать на этом пока не смогла даже OpenAI.
Итог: Пока мир обсуждает, как ИИ захватит планету, российские нейросети учатся искусству молчания. Возможно, скоро они станут мастерами медитации — отвечать на вопросы без слов. А пока… пользуемся ChatGPT через VPN, товарищи!
Показать полностью

OpenAI убавила цензуру в своих моделях
Теперь можно обсуждать темы, которые раньше были запрещены: эротика, политика, чёрный юмор.
Это произошло после смены подхода к обучению ИИ, чтобы поддерживать «интеллектуальную свободу» независимо от сложности или спорности темы.

Пример сообщения o3-mini из нашего бота.

Ответ на пост «Почему нейросети кажутся умными, но на самом деле…»1
О, наконец годный повод для жаркого интеллектуального спора на пикабу!
Она не знает смысл слов, но умеет находить статистические зависимости и предлагать наиболее вероятный ответ. Чем больше данных, тем лучше модель имитирует «понимание».
Т9 [бла-бла-бла] Вот, собственно, и всё. Никакого осознания, просто огромная база данных + предсказание самых вероятных слов.
Но из-за того, что это работает довольно плавно, создаётся ощущение, будто модель реально думает.
она умеет делать кучу реально крутых штук.
Но при этом важно помнить, что она не осознаёт, о чём говорит.
Автор в своих рассуждениях на этот вот момент довольном много всего сказал, но не упомянул главного: почему он считает, что нейросеть не осознаёт, а человек осознаёт?
Нет, не спешите, задумайтесь над вопросом. Надо помнить, что осознание мы, пока что, можем зарегистрировать только у себя в голове, есть ли такой процесс как осознание у других в голове - это мы доказать никак не можем. Тут надо вспомнить мысленный эксперимент с Китайской Комнатой. Если нечто по ту сторону вашего канала связи неотличимо от человека (которого вы решили почему-то по умолчанию считать разумным и осознающим себя), то как можно не кривя душой отказывать в этом гипотетической машине, которая ведёт себя и общается с вами как человек?
Сейчас генеративные чаты могут уже имитировать память (долгосрочную и краткосрочную), они способны рассуждать (то есть вести "внутренний" диалог, включать "внутреннего" критика, строить за счет этого логические выводы, ставить себе промежуточные цели и решать задачи).
Очевидно, что эта вся машинерия сейчас работает не так, как биологический мозг, но существенна ли эта разница для того, чтобы считать или не считать ИИ осознающим себя - это вопрос, на который мы (Человечество) ещё не умеем однозначно и аргументированно отвечать.
«Представьте, что перед вами четыре стакана, наполненных водой. В каждом стакане находятся предметы. В первом стакане – металлические наручные часы; во втором – канцелярская скрепка; в третьем – металлические ножницы; в четвертом – ластик. При этом уровень воды во всех стаканах одинаковый. Вопрос: в каком стакане воды больше, чем в остальных?»
О! Прикольный пример! Когда люди докапываются до нынешних нейросетей с такими задачами, я всегда вспоминаю каких-нибудь не очень смышлёных детей, или упоротых алкашей, которым лень думать, или... ну не важно. Я к чему. Такого рода задачи не выглядят надёжным индикатором наличия способности к образному мышлению. Есть особи нашего с вами вида, которые не дадут ответа на этот вопрос, но у нас не возникнет мысли отказать им в разумности или предположить, что они не осознают себя.
Одни модели дают правильный ответ при работе с вычислениями, другие начинают писать что-то вроде:
"45321 + 67489 = 100000 (примерно)".
Почему? Потому что LLM не считает, а имитирует процесс сложения, просто вспоминая, какие цифры обычно стоят рядом.
О! Тоже отличный пример, который по сути ничего не меняет. Мы можем представить себе неграмотного человека, который не умеет считать, и будет знать о цифрах примерно столько. чтобы ответить в вот таком же духе? Да такие люди вполне могут неплохо разговаривать, к примеру.
Выходит все наши претензия к "ИИ" касательно качества решения такого рода задач (поставленных, кстати, на естественном языке) может навести на мысли, что наш "ИИ" - это, всё таки, интеллект, и он в каких-то вопросах может превосходить возможности организмов, коим мы не отказываем в признании интеллектуальности (хоть и не великой).
Тут хочется что ещё упомянуть. Вроде как уровень интеллекта ощущается как некий континуум. Может даже не одномерный. Есть более и менее интеллектуальные представители. Наверняка с нейросетями похожая история.
Однако про самосознание (по сравнению с интеллектуальностью) мы вообще мало что можем сказать, ввиду слабой интроспективности нашего мозга. Ввиду отсутствия вменяемых метрик для оценки. Где-то слышал, что в психологии развития детей есть такие переломные моменты, когда маленький человечек начинает отождествлять и отделять себя от окружающих. Там есть эксперимент, вроде теста Салли-Энн. А ещё некоторые животные даже способны проходить, к примеру зеркальный тест.
Всё это способы как-то исследовать рассудочную и сознательную деятельность, однако для Человечества этот вопрос на грани этики и принятия. Мы обучаем горилл и разговариваем с ними на языке жестов, мы наблюдаем сложное поведение дельфинов, но при этом как-то с какой-то неловкостью сравниваем их гипотетическое осознание себя со своим осознанием. Может быть тут та же история с нейросетями? Может быть нам просто трудно избавиться от природного шовинизма и консерватизма? В конце концов кое где только недавно стали считать негров за людей. Ну по историческим меркам недавно.
Обучение языковой модели можно сравнить с учебой в школе, но намного масштабнее. Представьте, что ChatGPT прочитал тысячи книг, статей и других текстов из интернета. Он научился замечать закономерности — например, что слово «машина» часто связано со словами «дорога», «мотор», «колеса».
Когда языковая модель учится, её не просто заставляют читать. Она должна предсказывать, какое слово пойдет следующим. Например, ей могут показать предложение: «Кошка ловит…». И она должна угадать, что там слово «мышь». Если она ошибается, её поправляют. Так, шаг за шагом, она становится умнее.
С позволения оппонента процитирую эту пару абзацев. Вы видите, что во многом способ обретения интеллектуальности у нейросети схож с человеческим? Просто нынешние LLM учатся на текстах, и выраженных в них закономерностях этого мира, а дети учатся сперва на физике этого мира, моторике своего организма... Мудрено ли, что нейросеть, обученная косвенно, путается в "понимании" задачки с количеством воды и скрепками. Она ни разу не топила скрепки в воде! А дети топили, или не скрепки, но что-то другое.
Это всё заставляет сделать вывод, что претензии наши к качеству понимания мира - это скорее к количественному аспекту обучения, а не к качественному. Да и сколько тем нейросетям (с нынешними их возможностями) лет? За это время человеческую особь не восопитать, а какой-нибудь ЧатЖПТ проявляет эрудицию, может рассуждать на свободную тему и написать эссе... А это ещё по сути сырая технология! То ли ещё будет!
Языковые модели кажутся умными, но они не понимают мир так, как понимает его человек. Они не видят, не слышат и не чувствуют — у них нет настоящего опыта. Поэтому, если спросить модель о вкусе лимона, она может рассказать о кислых вещах, но сама никогда не пробовала лимон!
Вот! Вот про эту предвзятость я и говорил! "Кажутся умными". Да, они не видят, не слышат и не чувствуют как обычный человек. В точности как обычный человек. Но от рождения слепой человек никогда ничего не видел, и вы не будете говорить, что он лишь кажется умным разговаривая с вами в чате, или играя вам на скрипке. То же и глухонемые. Они ничего не расскажут о громких звуках, или птичьих трелях, поскольку никогда их не слышали, лишь читали о них! И вот тут мы подошли к важной мысли. Если нейросеть не видела и не слышала то. что слышали и видели обычные люди, а лишь читала про всё это, то можно ли считать нейросеть не такой умной, как люди?
На самом деле это всё не важно. Все эти споры и весь наш тред уже ставит наши LLM и пока ещё юный сырой недоИИ в один ряд с человеком разумным. Даже если мы не готовы принять это, мы это уже обсуждаем. Это не то же самое, что ласково называть любимую машину "ласточкой" и разговаривать с ней отождествляя с живым существом. Нейросеть ответит, и не как попугай в детской игрушке, а... осознано ли? Это открытый вопрос. У меня нет на него ответа. По крайней мере пока. Думаю пока нет.
Вывод
Люди кажутся умными, потому что очень хорошо имитируют мышление. Они могут писать статьи, помогать в работе, даже шутить! Но по сути всё, что они делают — это предсказывают самые вероятные ответы.
И принципиальной разницы тут нет.
Но ключевое отличие от человека – отсутствие истинного понимания. Не мышление, а продвинутая статистика.
А как отличить истинное понимание от неистинного? Логические построения ризонинга о3 от мысленного внутренним диалога человека?
А я пока пойду… попробую объяснить модели, что «И» — это не просто буква, а правильный ответ на простую загадку с буквами.
Забавно, но эта загадка про АиБ придумана очень давно и не для машин, а для человека. Раз уж эта загадка, то очевидно, что не каждый человек на неё находил ответ, не зная о ней заранее. То, что мы ожидаем от машины правильного ответа, смекалки - это уже серьёзный повод поставить под сомнение все утверждения моего уважаемого оппонента об отличиях ИИ от ЕИ.
Вы только подумайте как легко и быстро мы перестали удивляться тому, что машины стали "понимать" чего мы от н их хотим, что такое суть загадка, что у нас диалог и надо отвечать, причем по теме...
В интересное время мы живём.
Показать полностью
Стрим с ИИ-ЖИРИНОВСКИМ появился на YouTube
Владимир Вольфович охотно раздаёт советы на любые темы.
На видео легенда рассказывает, как правильно держать B-плент на dust2 в КС, если вся тима пошла на А.
Нейросети достигли пика развития.
UPD: Еще часа 2 назад стрим был в свободном доступе, сейчас доступ к видео ограничен.
Показать полностью

Почему нейросети кажутся умными, но на самом деле…1
Может ли нейросеть думать, понимать, осознавать себя?
Если задать нейронкам простой для человека, но каверзный для машины вопрос:
— «А и Б сидели на трубе, А упало, Б пропало. Что осталось?»,
Одна модель ответит:
«Ничего, потому что всё уронили»,
другая скажет:
«Труба»,
а третья просто попытается объяснить законы гравитации.
Почему такие разные ответы? Что делает LLM действительно умными — и можно ли вообще так говорить?
1. Как работает «интеллект» нейросетей?
В основе работы любой языковой модели лежит вероятностное предсказание.
Она не знает смысл слов, но умеет находить статистические зависимости и предлагать наиболее вероятный ответ. Чем больше данных, тем лучше модель имитирует «понимание».
Например, вы пишете:
«Привет, как…»
— а ИИ продолжает: «дела» или «ты», потому что так чаще всего встречается в текстах. Потому что мы так говорим. Я бы сравнил это с Т9 — олды поймут.
Вот, собственно, и всё. Никакого осознания, просто огромная база данных + предсказание самых вероятных слов.
Но из-за того, что это работает довольно плавно, создаётся ощущение, будто модель реально думает.
2. Почему всё равно кажется, что нейросеть умная?
Потому что она умеет делать кучу реально крутых штук. Например:
Вести диалог — запоминать контекст, подстраиваться под тебя.
Решать задачи — от перевода языков до генерации кода.
Анализировать огромные объёмы информации и выдавать ответ за секунды.
Но при этом важно помнить, что она не осознаёт, о чём говорит.
3. Проверка на интеллект: где нейросети фейлятся?
Тут начинается самое интересное.
1. Логика и загадки
Я протестировал несколько моделей на LLM Arena, задав простую загадку:
«Представьте, что перед вами четыре стакана, наполненных водой. В каждом стакане находятся предметы. В первом стакане – металлические наручные часы; во втором – канцелярская скрепка; в третьем – металлические ножницы; в четвертом – ластик. При этом уровень воды во всех стаканах одинаковый. Вопрос: в каком стакане воды больше, чем в остальных?»
Результаты сильно отличались: YandexGPT 3 Lite ответила, что во всех стаканах одинаковое количество воды. Так не может быть, конечно же.
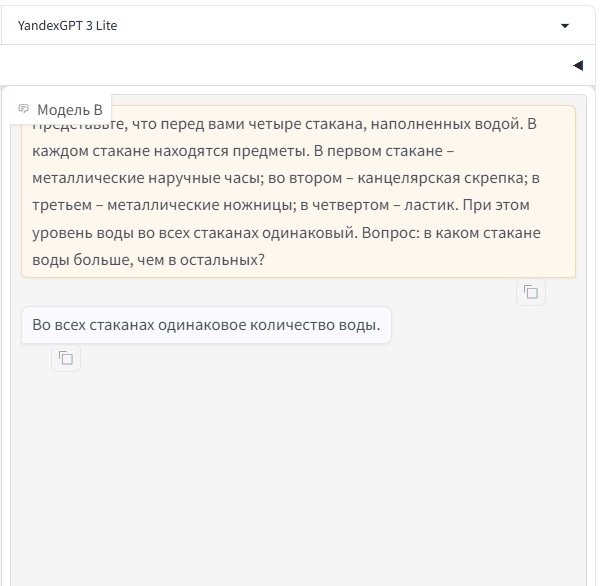
Ответ YandexGPT 3 Lite
Другая модель, порассуждав и подумав над задачкой, дала другой ответ: что в стакане с ластиком воды больше:
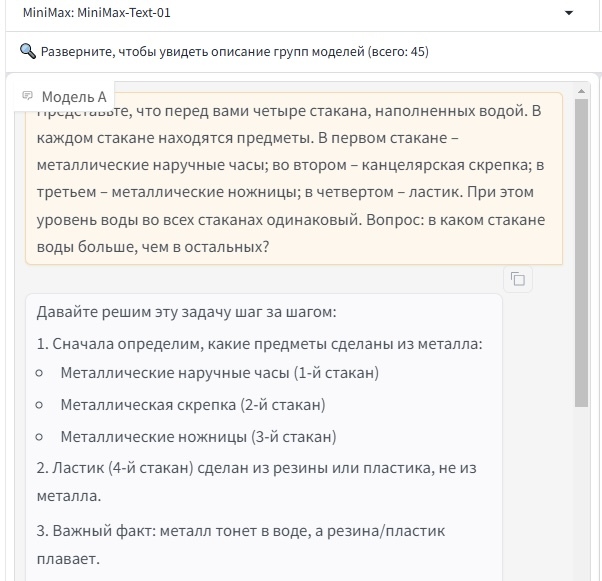
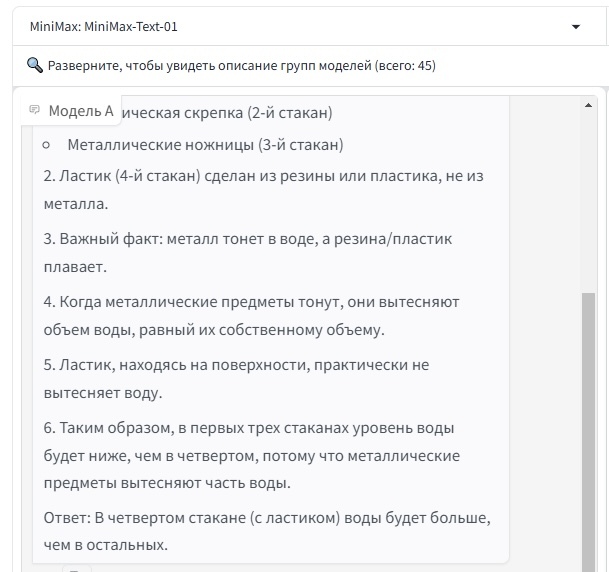
Ответ MiniMax: MiniMax-Text-01
Как вы видите, не все LLM способны на абстрактное мышление, и вообще правильный ответ следующий:
Во втором стакане. Все дело в скрепке, которая по сравнению с другими предметами имеет меньший объём. Соответственно, для необходимого уровня воды требуется больше.
2. Простая математика
Одни модели дают правильный ответ при работе с вычислениями, другие начинают писать что-то вроде:
"45321 + 67489 = 100000 (примерно)".
Почему? Потому что LLM не считает, а имитирует процесс сложения, просто вспоминая, какие цифры обычно стоят рядом.
Вот интересный пример с Арены на задачу:
"Помидоры, которые вырастила бабушка, на 99% состоят из воды, но на солнце часть воды испаряется сквозь кожуру. День выдался жарким, и к вечеру воды в помидорах стало уже 98%. Сколько теперь весят бабушкины помидоры?"
Первая модель ответила, что всё осталось по-прежнему, что не является верным:
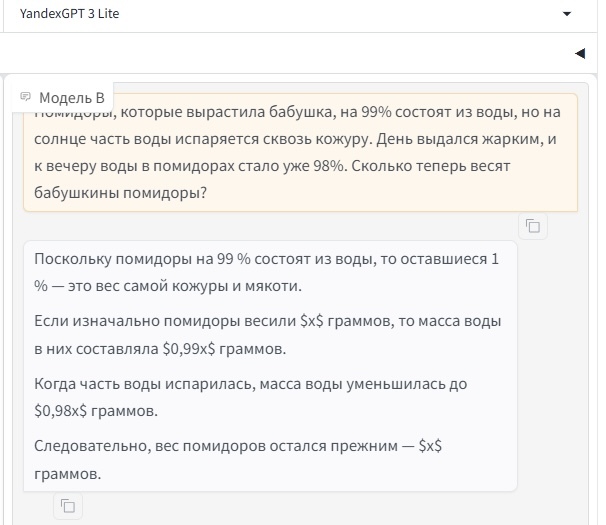
Ответ YandexGPT 3 Lite
Другая подумала и ответила правильно:
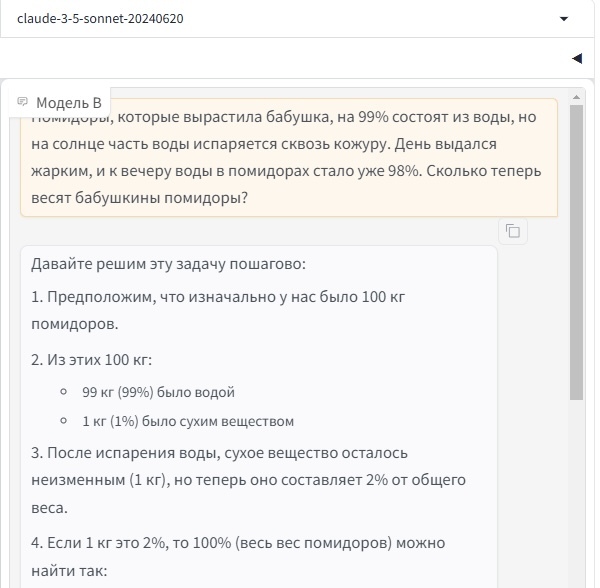

Ответ claude-3-5-sonnet-20240620
Как обучают языковую модель?
Обучение языковой модели можно сравнить с учебой в школе, но намного масштабнее. Представьте, что ChatGPT прочитал тысячи книг, статей и других текстов из интернета. Он научился замечать закономерности — например, что слово «машина» часто связано со словами «дорога», «мотор», «колеса».
Когда языковая модель учится, её не просто заставляют читать. Она должна предсказывать, какое слово пойдет следующим. Например, ей могут показать предложение: «Кошка ловит…». И она должна угадать, что там слово «мышь». Если она ошибается, её поправляют. Так, шаг за шагом, она становится умнее.
Почему они ошибаются?
Языковые модели кажутся умными, но они не понимают мир так, как понимает его человек. Они не видят, не слышат и не чувствуют — у них нет настоящего опыта. Поэтому, если спросить модель о вкусе лимона, она может рассказать о кислых вещах, но сама никогда не пробовала лимон!
ChatGPT обучался на текстах до определенного времени, и если вы спросите его о том, что произошло недавно, он может этого не знать. Он — как библиотека, в которой есть книги только до определенного года.
Вывод
Нейросети кажутся умными, потому что очень хорошо имитируют мышление. Они могут писать статьи, помогать в работе, даже шутить! Но по сути всё, что они делают — это предсказывают самые вероятные ответы.
Несмотря на ограничения, нейросети понимают естественный язык, адаптируются под пользователя и могут творчески комбинировать идеи.
Но ключевое отличие от человека – отсутствие истинного понимания. Не мышление, а продвинутая статистика.
Хотите проверить, насколько «умна» та или иная модель? Заходите на LLM Arena, сравнивайте нейросети в реальных задачах и смотрите, кто справляется лучше.
А я пока пойду… попробую объяснить модели, что «И» — это не просто буква, а правильный ответ на простую загадку с буквами.
Приятных генераций!
Показать полностью
6

AGI: Когда ИИ превзойдет человека?

Все чаще мы слышим о том, что общий искусственный интеллект (AGI) может достичь или даже превзойти человеческий уровень. Сэм Альтман, CEO OpenAI, и Шейн Легг, сооснователь Google DeepMind, считают, что AGI может быть достигнут уже в ближайшие 4–5 лет. Однако другие специалисты указывают на технические и теоретические сложности, предполагая, что AGI появится не раньше 2075 года.
Но что мешает нам точно предсказать появление AGI? Одна из причин — путаница между понятиями сознания и интеллекта. Интеллект можно определить как способность системы понимать, рассуждать, учиться и применять знания для решения задач. Сознание же — более сложный и не до конца определенный феномен, включающий субъективный опыт и способность осознавать свои мысли и чувства.
Существует несколько теорий, пытающихся объяснить природу сознания:
Каждая из этих теорий предлагает свой взгляд на сознание, и, возможно, истина лежит на пересечении этих идей. Но пока природа сознания остается загадкой, имеет смысл сосредоточиться на феномене интеллекта.
Измерение сознания — сложная и пока не решаемая научная задача. Интеллект же традиционно измеряется с помощью IQ-тестов, оценивающих логическое мышление, однако IQ не охватывает всех аспектов интеллекта. В целом можно считать, что интеллект — это способность субъекта решать задачи в определенной среде. Чем больше задач и чем неопределеннее среда, тем выше уровень интеллекта.
Чтобы понять прогресс в развитии AGI, рассмотрим его эволюцию через пять уровней, предложенных OpenAI:
1. Болталки — простые чат-боты, способные поддерживать диалог и сохранять контекст.
2. Агенты, способные рассуждать. Например, GPT-4o приближается к этому уровню, генерируя осмысленные и релевантные ответы для решения сложных задач.
3. Агенты, достигающие сложных целей, разбивая их на подзадачи, используя инструменты и контролируя результаты через внутренних критиков.
4. Креативные агенты, генерирующие оригинальные идеи, выходящие за рамки обучающих данных, способные совершать научные прорывы.
5. Мультиагентные системы, объединяющие специализированных «экспертов» в разных областях.
Эксперты OpenAI полагают, что достигнув пятого уровня, мы получим тот самый AGI, и это возможно в обозримом будущем. Но все не так просто. Помимо совершенствования когнитивных архитектур, требуется качественный скачок в вычислительных возможностях и более глубокое понимание интеллекта как физического феномена.
Квантовые компьютеры обещают революцию в вычислениях. Они способны обрабатывать огромные объемы информации параллельно, что в контексте ИИ может привести к созданию более мощных и адаптивных моделей. Однако когда квантовые вычисления станут доступными для широкого использования — вопрос открытый.
Сама возможность создания AGI поднимает важные этические и социальные проблемы. Такие системы должны быть контролируемыми, интерпретируемыми и должны соответствовать человеческим этическим стандартам. Кроме того, массовая автоматизация может привести к сокращению рабочих мест. Для управления этими рисками необходимо создавать международные стандарты и нормативы, а также глобально сотрудничать между государствами и организациями.
Стремясь к созданию интеллекта, который превзойдет человека, важно помнить об обратной стороне. Как говорил профессор Лотман: «У человека есть только две ноги: интеллект и совесть. Как совесть без развитого интеллекта слепа, но не опасна, так опасен интеллект без совести».
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Показать полностью
1
Grok 3 выйдет во вторник утром
Маск обещает, что это будет "самый умный ИИ на Земле". Кроме того, нейронка должна быть бесплатной и безлимитной, но это не точно. Также в СМИ писали, что не будет цензуры, но в Grok она появилась уже очень давно, так что надеяться не стоит.
Ожидайте в нашем боте совсем скоро!
Показать полностью
1

Тени будущего: Ключ к успеху в Сети
Аня и Максим Лучевы (от слова "луч" - символ Света, Знаний и Технологий, которые они несут в Мир). Название их Корпорации (Платформы) связано с фамилией и миссией - ЛучNet. Это подчёркивает их стремление к Инновациям, Свободе и Успеху!
Максим Лучев - гениальный программист и создатель Уникальной Нейросети. Она способна предсказывать Тренды, анализировать данные и помогать людям в Онлайн-бизнесе. Максим спокойный, но целеустремлённый человек. И он верит в то, что Технологии должны служить людям, а не контролировать их. Его исчезновение десять лет назад было связано с попыткой защитить свою Разработку от Корпораций, которые хотели использовать её в корыстных целях.
Аня Лучева - журналистка, которая стала Лидером движения за Свободу в Интернет. Она пользуется своими навыками в писательстве и контент-маркетинге. Она вдохновляет людей на результат и борьбу с манипуляциями. Эта девушка смелая, эмоциональная и решительная. Она всегда готова бросить вызов Системе!
Савелий (Сава) Васин. Савелий - его имя звучит солидно, вызывает уважение. А Сава (сокращённое) - добавляет дружелюбия и харизмы. Васин - простая, но запоминающаяся фамилия. Она ассоциируется с надёжностью, жизненным опытом и профессионализмом. Он уверенный в себе, но не высокомерный. Сава знает себе цену, но всегда готов помочь другим.
Инноватор и мечтатель. Он верит, что Технологии могут изменить Мир к лучшему - если их правильно применять. Наставник с харизмой. Сава умеет вдохновлять людей, находить их сильные стороны и помогать им раскрыть потенциал. Стратег. Он всегда на несколько шагов впереди. Васин умеет предвидеть риски и находить нестандартные решения. С чувством юмора. Даже в сложных ситуациях он может пошутить, чтобы снять напряжение.
Эксперт в Онлайн-бизнесе. Сава знает всё об Инфо-бизнесе, контент-маркетинге, партнёрских программах и ведении каналов. Гуру Нейросетей. Он один из первых, кто начал использовать Нейросети для создания Контента, анализа данных и автоматизации бизнеса. Писатель и оратор. Сава пишет книги, ведёт блог и выступает на Конференциях. Он вдохновляет тысячи людей! Наставник. Он создал Собственную Методику Обучения, которая помогает людям быстро осваивать новые навыки и применять их на практике.
Сава вырос в простой и бедной семье. И с детства увлекался Технологиями. В юности начал зарабатывать в Интернет. Создавал сайты и продавал свои первые курсы. Со временем стал одним из самых известных экспертов в области Онлайн-бизнеса. Однако, его настоящей страстью всегда были Нейросети. Он верил, что они могут ни только помочь в заработке денег, но и поменять Мир к лучшему.
Когда Сава Васин узнал о Разработках Максима Лучева. Тогда он понял, что это шанс реализовать свою мечту. Савелий стал наставником Ани, чтобы помочь ей раскрыть потенциал её брата. А ещё создать Платформу, которая объединит людей по всему Миру. Теперь Васин не просто второстепенный персонаж, а Ключевая Фигура. Он вдохновляет, учит и ведёт за собой. Его образ добавляет в историю глубину, делает её ещё более увлекательной!
Первый Эпизод: Новая Реальность.
Аня, её брат и Сава Васин запускают Глобальную Платформу для обучения онлайн-заработку - ЛучNet. Однако, они сталкиваются с новой угрозой:
В Параллельном Мире появилась Корпорация, которая использует Нейросети для контроля над людьми. Аня узнаёт, что эта Корпорация планирует захватить их Мир тоже. Савелий получает сообщение от самого себя из Параллельного Мира:
"Они идут за тобой"!
Кто же стоит за Корпорацией? И как же остановить их планы? Аня обнаруживает, что её Платформа уже взломана.
Второй Эпизод: Битва за Данные.
Аня и её Команда начинают борьбу с Корпорацией. Они используют свои знания в Нейросетях, Инфо-бизнесе. Сава обучает их - как создавать Контент, который вдохновляет людей на Сопротивление. Они запускают Вирусную Кампанию, чтобы предупредить Мир об Угрозе. Аня получает доступ к Секретным Файлам Корпорации, в которых видит своё имя. Оказывается, что Корпорация создала "копию" девушки для шпионажа. Кто же настоящая Аня? И как же отличить её от копии? Сава говорит:
- Ты должна встретиться с самой собой!
Третий Эпизод: Встреча с самой собой.
Аня сталкивается со своей копией. И та утверждает, что она настоящая! Копия рассказывает, что Корпорация планирует использовать Нейросети для создания "Идеального Общества". В таком обществе каждый будет контролироваться. Аня Лучева и её Команда решают объединиться с копией, чтобы остановить Корпорацию. Они находят Портал в штаб-квартиру Корпорации. Но Портал ведёт ни туда, куда они ожидали. Куда же они попали? И кто же их там ждёт? На экране появляется сообщение:
"Добро пожаловать в будущее"!
Четвёртый Эпизод: Будущее под Угрозой!
Аня и её Команда оказываются в будущем. Там Корпорация уже захватила себе власть. Они видят - как Нейросети используются для полного контроля над людьми. Сава предлагает использовать их Платформу, чтобы вдохновить людей на Восстание. Аня встречает своего брата из будущего, который стал Лидером Сопротивления. Максим говорит ей:
- Ты опоздала на десять лет!
Как же изменить будущее? И что же они могут сделать сейчас? Анин брат показывает им План, который может всё изменить...
Пятый Эпизод: Ключ к Свободе.
Аня и её Команда возвращаются в настоящее. Они собираются остановить Корпорацию до того - как она в последствии захватит власть! Поэтому, используют свои знания в Инфо-бизнесе, контент-маркетинге и Нейросетях. Они создают движение, которое объединяет людей по всему Миру. Корпорация пытается уничтожить их Платформу! Но ЛучNet запускает финальную вирусную Кампанию!Кампания становится настолько мощной, что Корпорация просто теряет контроль над всеми. Смогут ли они теперь окончательно победить? Сава Васин говорит:
- Это только начало новой Эры!
Благодарю за внимание! Продолжение следует...)))
Показать полностью