


Сгибай его полностью
Уникальный гибкий ноутбук HP Spectre Fold показали вживую. Девайс раскладывается как трансформер и стоит почти полмиллиона рублей — $4999.
Уникальный гибкий ноутбук HP Spectre Fold показали вживую. Девайс раскладывается как трансформер и стоит почти полмиллиона рублей — $4999.
Автор: CyberexTech
Больше интересных фото и комментариев в оригинале материала

Однажды, когда я искал эффективное решение для преобразования речи в текст (транскрибации), чтобы применить его в своем проекте умной колонки, обнаружил интересное решение под названием Whisper от широко известной компании Open AI. К сожалению, Whisper не подошел для реализации в моем проекте по «аппаратным» причинам, но его функционал отпечатался в моей душе. Прошло время и меня посетила идея: «Почему бы не разработать телеграмм бота, куда бы пользователь мог отправлять аудиофайл, а в ответ получал текстовую расшифровку и перевод (песни) на родной язык». В этой статье я расскажу о реализации данной идеи и Whisper в этом проекте займет одну из ключевых функций.
Во первых, что такое Whisper?
Whisper — это универсальная модель распознавания речи. Она обучена на большом наборе данных разнообразной аудиоинформации и является многофункциональной моделью, способной выполнять мультиязычное распознавание речи, перевод речи и идентификацию языка.
Ну и само название модели «Whisper» переводится как шепот, что само по себе намекает о качестве распознавания речи.
Чтобы не быть голословным, давайте запустим базовый пример использования и посмотрим вывод:
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result)
В результате выполнения скрипта мы получим следующий вывод в формате json:
{'text': ' Солнечное излучение (большой текст обрезал).',
'segments': [
{'id': 0, 'seek': 0, 'start': 0.0, 'end': 4.84, 'text': ' Солнечное излучение является одним из самых мощных источников энергии в Селенной.', 'tokens': [50364, 2933, 20470, 4310, 6126, 3943, 41497, 5627, 29755, 50096, 3943, 37241, 39218, 5783, 12410, 20483, 22122, 40804, 7347, 740, 2933, 21180, 5007, 13, 50606], 'temperature': 0.0, 'avg_logprob': -0.1954750242687407, 'compression_ratio': 2.0371621621621623, 'no_speech_prob': 0.0006262446404434741},
{'id': 1, 'seek': 0, 'start': 4.84, 'end': 8.4, 'text': ' Оно поступает на Землю в виде видимого и инфракрасного света,', 'tokens': [50606, 3688, 1234, 43829, 3310, 1470, 42604, 6578, 740, 12921, 38273, 2350, 1006, 6635, 3619, 481, 1272, 17184, 4699, 4155, 20513, 11, 50784], 'temperature': 0.0, 'avg_logprob': -0.1954750242687407, 'compression_ratio': 2.0371621621621623, 'no_speech_prob': 0.0006262446404434741},
{'id': 2, 'seek': 0, 'start': 8.4, 'end': 10.56, 'text': ' а также в виде космических лучей.', 'tokens': [50784, 2559, 16584, 740, 12921, 31839, 919, 38911, 15525, 2345, 13, 50892], 'temperature': 0.0, 'avg_logprob': -0.1954750242687407, 'compression_ratio': 2.0371621621621623, 'no_speech_prob': 0.0006262446404434741},
{'id': 3, 'seek': 0, 'start': 10.56, 'end': 15.8, 'text': ' Солнечное излучение имеет мощность примерно в квадратный метр поверхности Земли.', 'tokens': [50892, 2933, 20470, 4310, 6126, 3943, 41497, 5627, 33761, 39218, 9930, 37424, 740, 35350, 2601, 11157, 4441, 18791, 481, 44397, 13975, 42604, 1675, 13, 51154], 'temperature': 0.0, 'avg_logprob': -0.1954750242687407, 'compression_ratio': 2.0371621621621623, 'no_speech_prob': 0.0006262446404434741},
{'id': 4, 'seek': 0, 'start': 15.8, 'end': 19.44, 'text': ' Это достаточно для производства электроэнергии и других применений.', 'tokens': [51154, 6684, 28562, 5561, 28685, 12115, 31314, 9938, 7570, 489, 19480, 7347, 1006, 31211, 31806, 1008, 17271, 13, 51336], 'temperature': 0.0, 'avg_logprob': -0.1954750242687407, 'compression_ratio': 2.0371621621621623, 'no_speech_prob': 0.0006262446404434741}
], 'language': 'ru'}
Как можно видеть из содержания вывода, Whisper выводит довольно информативный результат транскрибации, с разбивкой текста на сегменты и указанием временных меток, языка и другой информации. Используя эту информацию, мы можем сформировать удобный и красивый текстовой файл расшифровки аудио.
Изначально планировалось реализовать только текстовую расшифровку аудиофайла(песни), но потом мелькнула мысль: «Почему бы не реализовать перевод текста, отличного от родного языка? Ведь так можно узнать смысл любимой песни всего за пару минут.»
Для реализации этой идеи, я решил пойти простым путём: использовать API сервисов онлайн переводчиков. К сожалению, а может и к счастью, это была моя ошибка, ввиду ограничения запросов на данные API. Ну что ж, подумал я, меньше внешних сервисов — больше свободы, будем использовать локальные алгоритмы перевода на базе нейронных сетей.
Трансформеры нам помогут! Не долго размышляя, решил использовать библиотеку Transformers, которая позволяет применять в своих проектах большое количество моделей, полный список можно посмотреть на сайте проекта.
Для оффлайн перевода будем использовать модели Helsinki-NLP от Группы исследований языковых технологий Хельсинкского университета.
Пример Python скрипта для оффлайн перевода:
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# устанавливаем количество потоков для torch
torch.set_num_threads(4)
#Перевод с любого языка на английский
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-mul-en")
text = "Какой-то текст на любом языке"
translation = translator(text)
print(translation[0]['translation_text'])
В примере указан мультиязычный перевод на английский. К сожалению, у Helsinki-NLP нет мультиязычных моделей с переводом на русский язык, поэтому воспользуемся трюком большинства генеративных ИИ и применим двойной перевод, то есть в нашем случае, с английского языка на русский, используя модель Helsinki-NLP/opus-mt-en-ru.
Учитывая все свои размышления по функциональности бота, получился следующий результат, для удобного восприятия кода, я разделил скрипт на несколько файлов:
Главный скрипт, отвечающий за работу бота tg_bot.py:
import neural_process
import file_process
import config
from telegram import ForceReply, Update
from telegram.ext import Application, CommandHandler, MessageHandler, filters, CallbackContext, ContextTypes
# Функция, которая вызывается при отправке файла
async def handle_file(update: Update, context: CallbackContext):
audio = update.message.audio
print(audio.mime_type)
# Сохраняем аудиофайл локально и получаем путь сохранения
file = await context.bot.get_file(audio.file_id)
f_name = audio.file_name
local_file_path = file_process.save_audio_file(f_name, file.file_path)
# Отправляем сообщение о успешном сохранении аудиофайла
await update.message.reply_text(
f"Подождите немного, я в ускоренном темпе прослушаю аудиофайл {f_name} и отправлю вам текстовую "
f"расшифровку с переводом."
)
# проверяем файл на длительность
status = True
status_dur = True
try:
file_dur = file_process.file_duration_check(local_file_path)
if file_dur > 600:
status_dur = False
except Exception as e:
print(f"Возникла ошибка: {e}")
status_dur = False
# Получаем перевод
trance_text = 'в эту переменную сохраняется текст транскрибации с переводом'
if status_dur:
try:
start_time = time.time()
trance_text = neural_process.final_process(local_file_path, f_name)
except Exception as e:
print(f"Возникла ошибка: {e}")
status = False
else:
status = False
await update.message.reply_text(
f"Сожалею, но возникла ошибка обработки файла. Длительность файла не должна превышать десять минут."
)
if status:
# Сохраняем вывод в текстовый файл
tx_file_path = file_process.save_text_to_file(f_name, trance_text)
end_time = time.time()
process_time = round(end_time - start_time, 2)
await update.message.reply_text(
f"Перевод готов! Ловите файл с переводом. Затраченное время: {process_time} сек. "
)
# Отправляем текстовый файл
with open(tx_file_path, "rb") as document:
await context.bot.send_document(chat_id=update.message.chat_id, document=document)
else:
file_process.delete_file(local_file_path)
if status_dur:
await update.message.reply_text(
f"Сожалею, но возникла ошибка обработки файла. Пожалуйста, убедитесь что файл имеет правильный аудиоформат."
)
# Функция для команды /start
async def start(update: Update, context: CallbackContext) -> None:
await update.message.reply_text(
'Привет! Добро пожаловать! Нравится песня, но ты не знаешь о чем она? Я могу перевести песню с любого языка '
'на русский за считанные секунды, просто скинь аудио файл в чат. ')
# Функция для команды / help
async def help_command(update: Update, context: ContextTypes.DEFAULT_TYPE) -> None:
"""Send a message when the command /help is issued."""
user = update.effective_user
await update.message.reply_html(
rf"{user.mention_html()}, я могу перевести песню с любого языка на русский, просто скинь аудио файл в чат.",
reply_markup=ForceReply(selective=False),
)
# Запускаем бота
def main():
# Токен бота
application = Application.builder().token(config.tg_key).build()
# Регистрируем обработчик для команды /start
application.add_handler(CommandHandler("start", start))
application.add_handler(CommandHandler("help", help_command))
# Регистрируем обработчик для приема файлов
application.add_handler(MessageHandler(filters.AUDIO, handle_file))
# Запускаем бота
application.run_polling()
# Останавливаем бота при нажатии Ctrl+C
application.idle()
if __name__ == '__main__':
main()
Скрипт для работы с файлами file_process.py:
import requests
import os
from pydub.utils import mediainfo
def delete_file(file_path):
try:
os.remove(file_path)
print(f"Файл {file_path} успешно удален.")
except FileNotFoundError:
print(f"Файл {file_path} не найден.")
except Exception as e:
print(f"Произошла ошибка при удалении файла {file_path}: {e}")
def save_audio_file(file_name, file_link):
response = requests.get(file_link)
# Сохраняем аудиофайл локально для последующей обработки
sound_folder = 'sound'
local_file_path = f"{sound_folder}/{file_name}"
if not os.path.exists(sound_folder):
# Если папки нет, создаем её
os.makedirs(sound_folder)
with open(local_file_path, 'wb') as local_file:
local_file.write(response.content)
return local_file_path
def save_text_to_file(file_name, trance_text):
text_folder = 'output'
local_file_path = f"{text_folder}/{file_name.replace('.', '_') + '.txt'}"
if not os.path.exists(text_folder):
# Если папки нет, создаем её
os.makedirs(text_folder)
# Сохраняем вывод в текстовый файл
with open(local_file_path, "w", encoding="utf-8") as output_file:
output_file.write(trance_text)
return local_file_path
def file_duration_check(file_path):
audio_info = mediainfo(file_path)
duration = float(audio_info['duration'])
print(duration)
return duration
Скрипт для работы с нейросетями neural_process.py:
from transformers import pipeline
import torch
import whisper
import file_process
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# устанавливаем количество потоков для torch
torch.set_num_threads(4)
def sound_to_text(audios):
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(audios)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
lang = max(probs, key=probs.get)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
result = model.transcribe(audios, fp16=False, language=lang)
print(result)
return result['segments'], lang
def final_process(file, file_name):
print(f"Сохранен в директории: {file}")
raw, detected_lang = sound_to_text(file)
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-mul-en")
translator2 = pipeline("translation", model="Helsinki-NLP/opus-mt-en-ru")
text = f"Перевод аудиофайла: {file_name} \n"
text += f"В файле используется {get_language_name(detected_lang)} язык. \n"
for segment in raw:
text += "-------------------- \n"
text += f"ID элемента: {segment['id']} Начало: {int(segment['start'])} --- Конец: {int(segment['end'])} \n"
text += f"Исходный текст:{segment['text']} \n"
if detected_lang == 'en':
text_en = segment['text']
translation2 = translator2(text_en)
text += f"Перевод: {translation2[0]['translation_text']} \n"
elif detected_lang == 'ru':
text += ""
else:
translation = translator(segment['text'])
text_en = translation[0]['translation_text']
translation2 = translator2(text_en)
text += f"Перевод: {translation2[0]['translation_text']} \n"
file_process.delete_file(file)
print(text)
return text
def get_language_name(code):
languages = {
'ru': 'русский',
'en': 'английский',
'zh': 'китайский',
'es': 'испанский',
'ar': 'арабский',
'he': 'иврит',
'hi': 'хинди',
'bn': 'бенгальский',
'pt': 'португальский',
'fr': 'французский',
'de': 'немецкий',
'ja': 'японский',
'pa': 'панджаби',
'jv': 'яванский',
'te': 'телугу',
'ms': 'малайский',
'ko': 'корейский',
'vi': 'вьетнамский',
'ta': 'тамильский',
'it': 'итальянский',
'tr': 'турецкий',
'uk': 'украинский',
'pl': 'польский',
}
return languages.get(code, 'неизвестный язык')
Для запуска скрипта, нам необходимо установить следующие пакеты, используя команду:
pip install transformers, torch, accelerate, sentencepiece, sacremoses, python-telegram-bot, openai-whisper, pydub
Чтобы всё заработало, не деплойте по пятницам.
Наш телеграмм бот, который работает с использованием алгоритмов ML, достаточно требователен к аппаратным ресурсам. Да, вы можете его использовать на своем ПК, но целесообразнее использовать облачные сервисы для подобных целей. Для размещения своего телеграмм бота, я решил воспользоваться облачной инфраструктурой от компании Timeweb Cloud. Итак, приступим к созданию нашего облачного сервиса.
Для создания нашего облачного сервиса, нам необходимо войти в панель управления под вашей учетной записью. Если учетная запись не создана, то регистрация учетной записи займет всего пару кликов. Я, например, для регистрации и авторизации воспользовался аккаунтом Google.
Создаем новый сервис, выбираем пункт «Облачный сервер»:
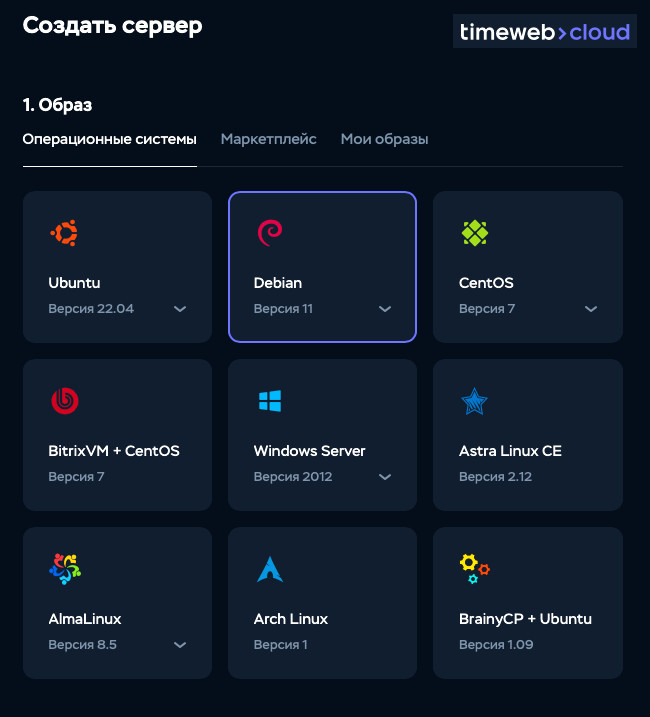
Далее нам предстоит выбрать операционную систему для нашего сервера, я выбрал Debian 11:
Выбираем расположение нашего сервера:

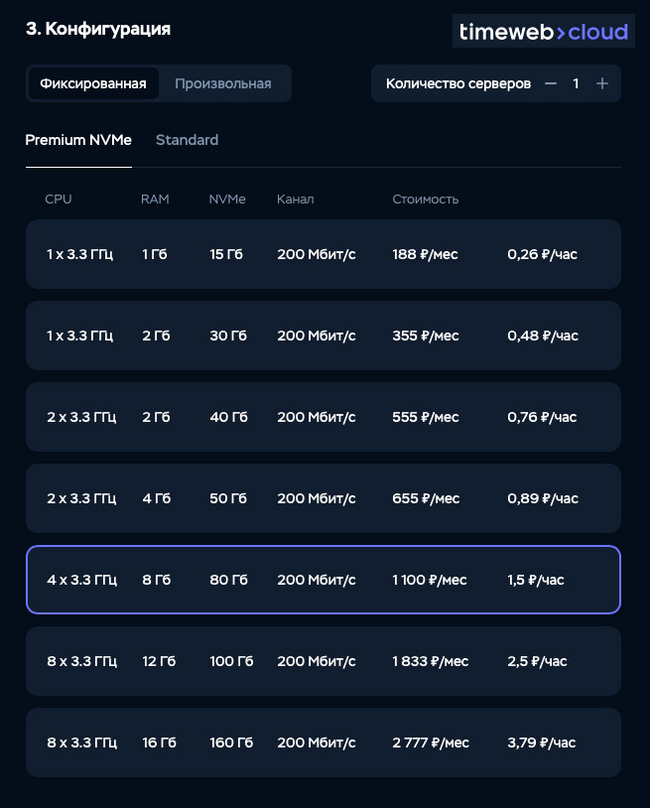
Выбираем конфигурацию сервера, как видно на изображении, для начальных тестов я выбрал конфигурацию с четырьмя ядрами CPU и 8 ГБ оперативной памяти:
Вот и все основные опции, которые нам нужны для создания сервера, остальные опции выбираете/указываете по желанию. Чтобы создать сервер, необходимо нажать кнопку «Заказать», которая располагается справа.
Процесс создания сервера:
Сервер создан:
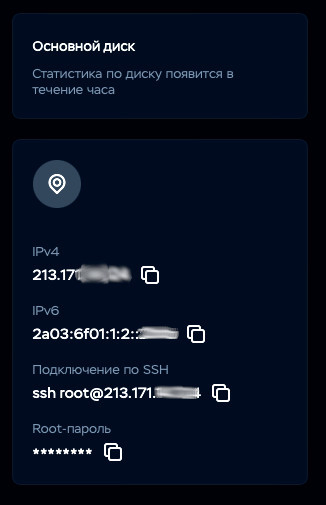
После успешного создания сервера, перейдя в дашборд, с правой стороны вы увидите параметры для удаленного подключения к созданному серверу:
Всё выполняется очень быстро, на создание сервера ушло пару минут.
Далее мы будем использовать терминал для подключения к нашему облачному сервису.
Запускаем терминал и подключаемся к нашему серверу, после подключения нам необходимо проверить и установить доступные обновления:
apt-get update & upgrade
Запускать скрипты с root правами — как минимум, это дурной тон, поэтому создаем нового пользователя с именем tg_bot:
adduser tg_bot
и пропишем его в группу sudo:
usermod -aG sudo tg_bot
Затем нам нужно выйти из учетной записи root и подключиться под новым пользователем tg_bot, и далее все операции мы будем выполнять под этой учетной записью.
Проверим обновления Python3 и установим, если имеются:
sudo apt update
sudo apt install python3
Установим менеджер пакетов:
sudo apt install python3-pip
Так как мы работаем с медиафайлами, нам необходимо установить набор библиотек FFmpeg:
sudo apt install ffmpeg
Для оценки производительности, на всякий случай установим системный монитор htop:
sudo apt install htop
Устанавливаем необходимые зависимости, для работы нашего бота:
pip install transformers, torch, accelerate, sentencepiece, sacremoses, python-telegram-bot, openai-whisper, pydub
Создаем рабочую директорию для нашего бота:
mkdir tg_bot_scripts
Затем переходим в созданную директорию, с помощью команды:
cd tg_bot_scripts
Далее нам нужно создать файлы Python нашего бота, с помощью команд:
nano tg_bot.py
В открывшемся текстовом редакторе вставляем код из статьи и сохраняем, аналогично поступаем и с другими файлами.
nano neural_process.py
nano file_process.py
nano config.py
файл config.py содержит только одну переменную, которая содержит секретный ключ телеграм-бота.
tg_key = 'Ваш секретный ключ'
Или можно воспользоваться альтернативным способом, клонировав код моего репозитория GitHub.
Чтобы это реализовать, нам нужно установить Git:
sudo apt install git
После установки Git, выполнить следующую команду:
Далее нам необходимо переименовать созданную при клонировании Git репозитория папку music_translate_AI_bot с помощью команды:
mv music_translate_AI_bot tg_bot_scripts
После этого важно не забыть добавить токен телеграмм бота:
cd tg_bot_scripts
nano config.py
Настало время тестового запуска, запустим нашего бота с помощью команды:
pyton3 tg_bot.py
Если бот запустился и работает нормально, то нам необходимо создать системный сервис для автоматического запуска нашего бота. Создадим файл нашего сервиса с помощью команды:
sudo nano /etc/systemd/system/AI_tg_bot.service
Копируем в открывшийся текстовый редактор следующее содержимое и сохраняем файл:
[Unit]
Description=My AI Bot service
After=network.target
[Service]
WorkingDirectory=/home/tg_bot/tg_bot_scripts/
User=tg_bot
Type=simple
Restart=always
ExecStart=/usr/bin/python3 /home/tg_bot/tg_bot_scripts/tg_bot.py > /dev/null
[Install]
WantedBy=multi-user.target
Чтобы добавить созданный сервис в автозагрузку, используйте следующую команду:
sudo systemctl enable AI_tg_bot.service
Чтобы запустить сервис используйте команду:
sudo systemctl start AI_tg_bot.service
Чтобы остановить:
sudo systemctl stop AI_tg_bot.service
В процессе отладки бота, я решил изменить конфигурацию своего облачного сервера с четырехъядерного CPU на восьмиядерный. Захожу в панель управления Timeweb Cloud, выбрав свой сервер, перехожу на вкладку «конфигурация»:
И выбираю необходимую конфигурацию:
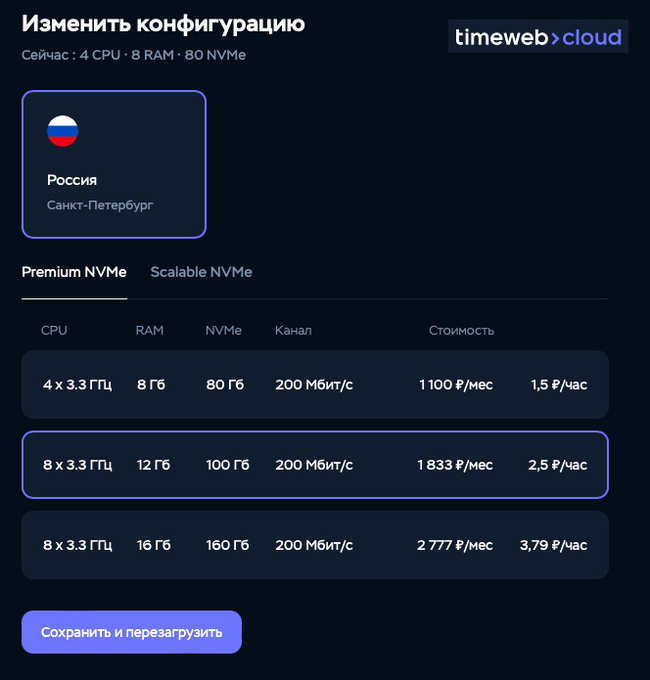
Менее минуты и сервер с новой конфигурацией в работе. Еще мне понравилось то, что оплата облачного сервера выполняется только за фактические часы работы и вы в любой момент можете изменить конфигурацию, без необходимости вноса оплаты за месяц вперед. В панели управления вы можете видеть ваш текущий баланс и дату окончания средств при текущей конфигурации сервера (или серверов).
При изменении количества ядер CPU на облачном сервере, так же необходимо в скрипте обработки neural_process.py изменить количество потоков для torch, в моем случае на восемь.
torch.set_num_threads(8)
После изменения конфигурации сервера, можно понаблюдать нагрузку при обработке аудиофайла нашим телеграмм ботом с помощью команды:
htop
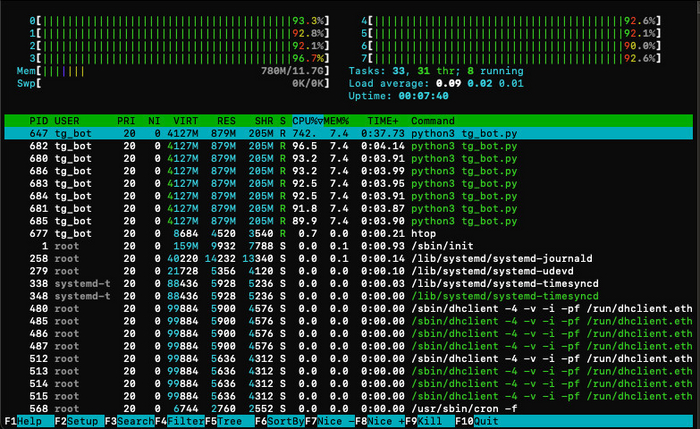
В итоге у нас получился интересный эксперимент реализации телеграм-бота с применением алгоритмов машинного обучения для распознавания речи и перевода текста.
Спасибо вам за уделенное время и внимание. Есть вопросы, критика, осуждение? Добро пожаловать в комментарии. :)
Небольшой бонус к статье. Переводы песен с помощью созданного бота:
Перевод аудиофайла: Lana Del Rey West Coast.mp3
В файле используется английский язык.
—
ID элемента: 16 Начало: 99 — Конец: 103
Исходный текст: Who baby, who baby, I'm in love
Перевод: Кто, детка, я влюблен.
—
ID элемента: 17 Начало: 103 — Конец: 113
Исходный текст: I'm in love
Перевод: Я влюблен.
—
ID элемента: 18 Начало: 113 — Конец: 123
Исходный текст: Don't know the west coast, they got their icons
Перевод: Не знаю западного побережья, у них есть иконы.
—
ID элемента: 19 Начало: 123 — Конец: 127
Исходный текст: They serve as others, their queens are psychons
Перевод: Они служат как другие, их королевы — психи.
—
ID элемента: 20 Начало: 127 — Конец: 132
Исходный текст: You, good to music, you, good to music and you
Перевод: Ты, хорош в музыке, ты, хорош в музыке и ты
—
ID элемента: 21 Начало: 132 — Конец: 134
Исходный текст: Don't you
Перевод: А ты нет?
—
ID элемента: 22 Начало: 134 — Конец: 139
Исходный текст: Don't know the west coast, they love their movies
Перевод: Не знаю западного побережья, они обожают свои фильмы.
—
ID элемента: 23 Начало: 139 — Конец: 142
Исходный текст: They're golden-guzzing, rocking all copies
Перевод: Они хвастаются золотом, раскачивают все копии.
—
ID элемента: 24 Начало: 142 — Конец: 147
Исходный текст: And you, good to music, you, good to music and you
Перевод: А ты, хорош в музыке, ты, хорош в музыке и ты
—
ID элемента: 25 Начало: 147 — Конец: 149
Исходный текст: Don't you
Перевод: А ты нет?
—Перевод аудиофайла: Edis-Banane.mp3
В файле используется турецкий язык.
—
ID элемента: 0 Начало: 0 — Конец: 1
Исходный текст: Alo.
Перевод: Привет.
—
ID элемента: 1 Начало: 2 — Конец: 3
Исходный текст: Bir şey söyle.
Перевод: Скажи что-нибудь.
—
ID элемента: 2 Начало: 6 — Конец: 7
Исходный текст: Bir şey söylemek istemiyorum.
Перевод: Я не хочу ничего говорить.
—
ID элемента: 3 Начало: 8 — Конец: 9
Исходный текст: Peki o zaman.
Перевод: Ну что ж.
—
ID элемента: 4 Начало: 30 — Конец: 32
Исходный текст: Bala ne dediğimi soracak olamazsın.
Перевод: Ты не можешь спросить моего отца, что я сказал.
—
ID элемента: 5 Начало: 32 — Конец: 33
Исходный текст: Hayır.
Перевод: Нет, нет, нет.
—
ID элемента: 6 Начало: 33 — Конец: 36
Исходный текст: Bir sebebim yok artık kalamam mı?
Перевод: У меня больше нет причин?
—
ID элемента: 7 Начало: 36 — Конец: 37
Исходный текст: Hayır.
Перевод: Нет, нет, нет.
—
ID элемента: 8 Начало: 40 — Конец: 42
Исходный текст: Ki göz dilimi.
Перевод: Вот об этом я и говорю.
—
ID элемента: 9 Начало: 42 — Конец: 43
Исходный текст: Bu ne?
Перевод: Что это?
—
Продемонстрирована только часть перевода, более информативная, чтобы не раздувать и так большую статью.
Полезные ссылки:
Облачные сервисы Timeweb Cloud — это реферальная ссылка, которая может помочь поддержать меня и мои проекты.
Автор: CyberexTech
Больше интересных фото, видео и комментариев в оригинале материала

В свете широкого внедрения систем домашней автоматизации возникает потребность в более естественном взаимодействии с «умным домом». Как средство натурального взаимодействия между человеком и машиной, голосовой интерфейс заслуженно занимает высокую популярность. В данной статье я поделюсь своим опытом создания бюджетного автономного голосового ассистента для систем умного дома.
Больше года назад я нашел в своих закромах одноплатный компьютер Raspberry Pi 4 Model B 8 ГБ. Устройство было куплено за небольшую цену в то время, когда человечество ещё не сошло с ума. Без долгих размышлений, я принял решение создать голосового ассистента на базе этого одноплатного компьютера, чтобы управлять своей системой домашней автоматизации. Бонусом к этой идее шли приватность и автономность. В итоге у меня «родилось» устройство под кодовым именем «Мария».
Но в этой статье не пойдет речь об использовании Raspberry Pi 4 Model B, так как в современных реалиях использование данного одноплатного компьютера стоимостью более $190, трудно назвать бюджетным решением.
Недавно компания Xunlong Software, которая занимается выпуском одноплатных компьютеров под маркой Orange Pi, представила интересное решение — плату Orange Pi Zero 2W с 4 ГБ оперативной памяти, стоимостью $27.

Данное решение вполне подходит для нашего проекта, как в техническом, так и в экономическом плане.
Итак, определимся с конструкцией устройства. Изучив спецификацию Orange Pi Zero 2W, у нас формируется следующий список дополнительных компонентов:
Динамик 52мм (просто он у меня уже был $1,3)
Усилитель низкой частоты (буду использовать PAM8403 $0,9 за 10 шт)
USB микрофон (xingzhaotong $1,5)
Шлейф FFC FPC 24pin тип B ($1)
RGB светодиод
Согласно документации, аудиовыходы реализованы на боковом разъеме FPC, а интерфейс I2S отсутствует. По крайней мере, мне не удалось его реализовать на этой плате. Таким образом, в качестве аудиовхода мы будем использовать USB-микрофон. В версии «Мария» я использовал I2S-микрофон, который продемонстрировал отличные результаты. Ниже предоставлена распиновка бокового разъёма.
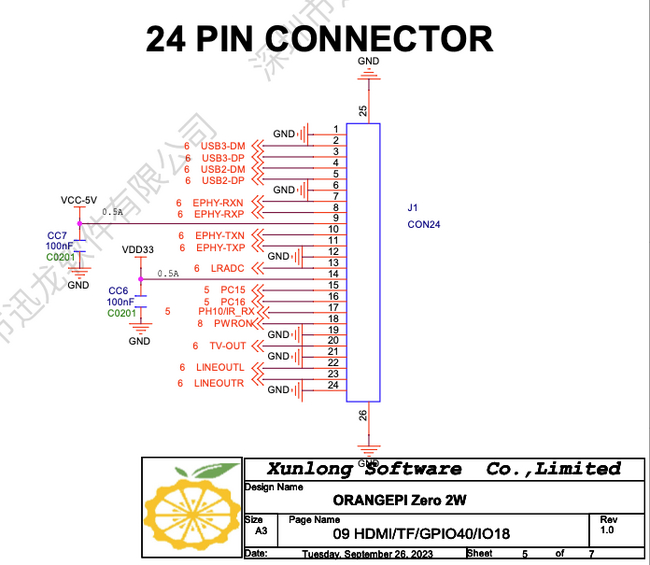
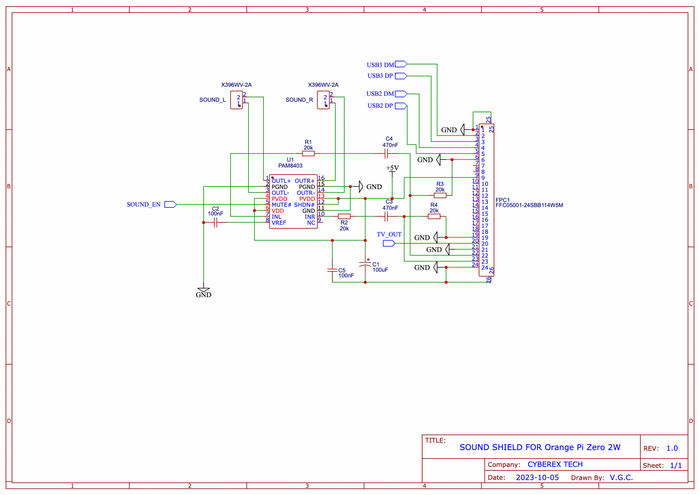
Исходя из вышесказанного, в процессе разработки у нас получается следующая схема «звуковой платы»:
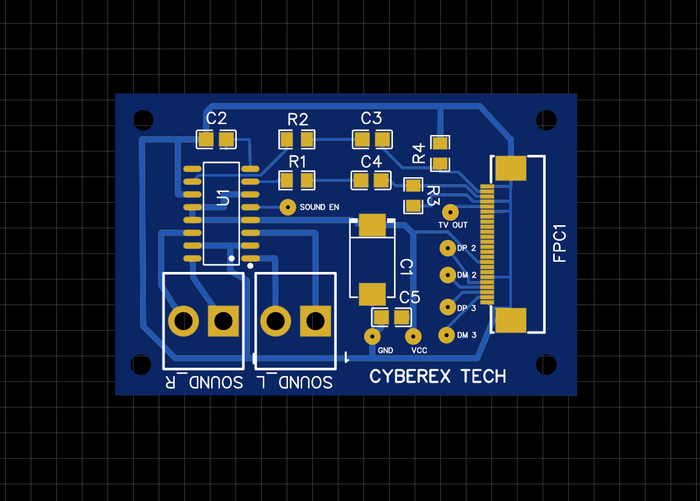
Так могла бы выглядеть плата при производстве на китайской фабрике:
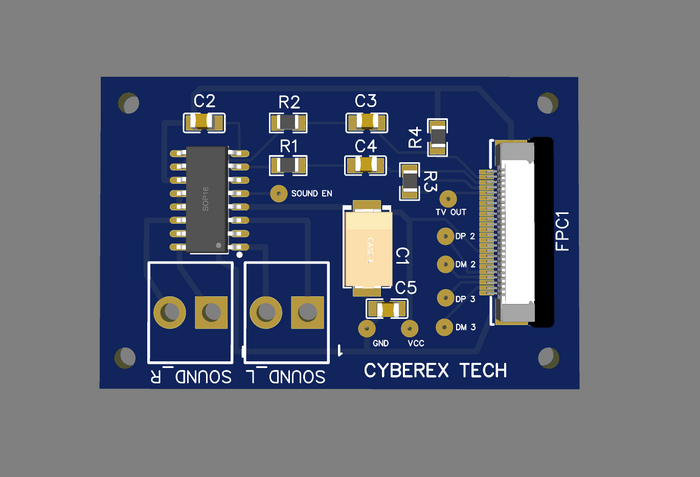
На тот момент, я разрабатывал прототип, и не было известно, как поведет себя схема звуковой платы. Поэтому пришлось выполнять изготовление прототипа платы в домашних условиях, для меня это дело привычное. Плата изготавливалась с помощью фоторезиста и вытравливалась в растворе перекиси водорода, лимонной кислоты и соли.

Немного были переживания относительно качества вытравливания мелких дорожек, но фоторезист не подвёл, всё получилось хорошо.
Ниже показано тестовое подключение звуковой платы к одноплатному компьютеру с помощью шлейфа FFC FPC:

Обычно в своих разработках я использую естественный интеллект. Поэтому пришлось придумывать дизайн корпуса самостоятельно, учитывая особенности печати 3D принтера. Разработку модели корпуса выполнял с помощью FreeCAD, результат моделирования вы можете видеть ниже.

Корпус в собранном виде

Вид снизу

Элементы корпуса были спроектированы с учетом оптимизации процесса печати, при этом качество не пострадало. В процессе печати не используются структуры поддержки. Ножки корпуса выполнены из TPU-пластика, использование флекс пластика предотвращает скольжение умной колонки по поверхности стола.
Подключение элементов устройства выполняется по следующей схеме:
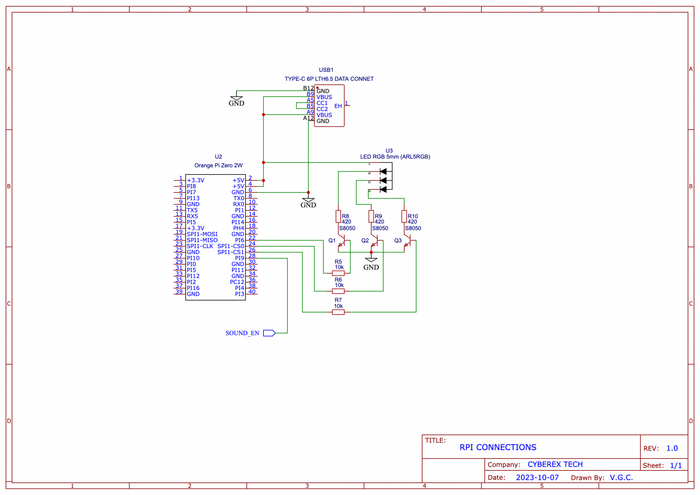
Как видно из схемы, для управления усилителем используется выход 28 (wPi 18) RPI разъёма, данный выход подключается к контакту звуковой платы с обозначением «SOUND EN». К выходам 26, 24, 22 подключается управление RGB светодиода, который выполняет функцию индикатора при выполнения запросов.
Как я упоминал ранее, в качестве микрофона используется USB микрофон марки xingzhaotong, который выглядит так:

Для установки в корпус колонки, нам необходимо его полностью разобрать и оставить только плату. Данная плата подключается согласно распиновки к соответствующим контактам на звуковой плате GND, DP, DM, VCC.
Давайте приступим к сборке устройства. Предварительная примерка платы Orange Pi Zero 2W:

Примерка динамика

Установка динамика и резонатора. Резонатор одновременно выполняет функцию фиксатора

Вид снизу

Вид сверху без верхней крышки, на верхней поверхности резонатора виден прикрепленный USB микрофон в центре будет размещен RGB светодиод.

Распечатанная на 3D принтере часть корпуса

Вид снизу собранной умной колонки. Также снизу располагаются вентиляционные отверстия для охлаждения платы

Для питания устройства используется модуль с разъёмом USB Type C, который фиксируется в специальном адаптере
В этой статье я не планировал описывать программную часть устройства, так как это занимает большой объем информации, лучше это сделать в отдельной статье. Но ниже будут предоставлены некоторые моменты по программной настройки устройства.
Операционная система:
В качестве операционной системы я использовал Debian Bullseye c версией ядра 6.1.31, скачать можно на официальном сайте Orange Pi.
Управление GPIO:
Для управления GPIO используется официальная библиотека Orange Pi wiringPi.
Установка wiringPi:
apt-get update
apt-get install -y git
git clone https://github.com/orangepi-xunlong/wiringOP.git
cd wiringOP
sudo ./build clean
sudo ./build
После успешной установки Orange Pi wiringPi, мы можем вывести таблицу GPIO:
gpio readall
В итоге мы увидим следующее:
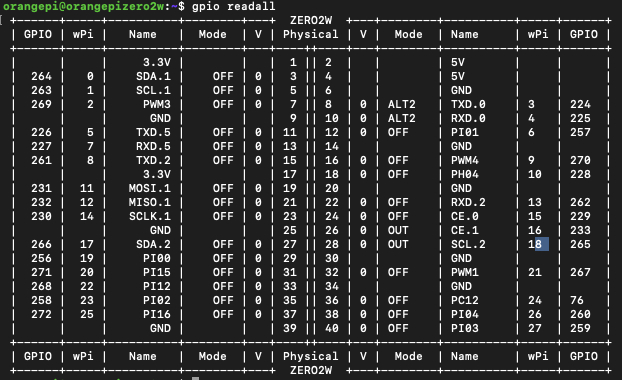
Обратите внимание, что в колонке «V» указано текущее состояние пина RPI.
Чтобы изменить состояние, мы можем воспользоваться следующими командами:
gpio mode 18 out # Изменение типа пина вход/выход (in/out)
gpio write 18 0 # Изменение уровня пина низкий/высокий (0/1)
gpio read 18 # Чтение состояние пина
Пример одного из вариантов управления GPIO из Python скрипта:
import os
os.system("gpio mode 18 out") # Изменение типа пина вход/выход (in/out)
os.system("gpio write 18 0") # Изменение уровня пина низкий уровень
os.system("gpio write 18 1") # Изменение уровня пина высокий уровень
os.system("gpio read 18") # Чтение состояние пина
Проверка наличия микрофона в системе:
Чтобы убедиться в правильности подключения микрофона, в консоли необходимо выполнить следующую команду:
arecord -l
Вывод команды должен быть следующим:
**** List of CAPTURE Hardware Devices ****
card 2: ahubhdmi [ahubhdmi], device 0: ahub_plat-i2s-hifi i2s-hifi-0 [ahub_plat-i2s-hifi i2s-hifi-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 3: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio]
Subdevices: 0/1
Subdevice #0: subdevice #0
Как видим из вывода, устройство USB PnP Sound Device успешно определилось в системе, если устройство отсутствует, то необходимо убедиться в его корректном подключении.
Настройка аудиовыхода:
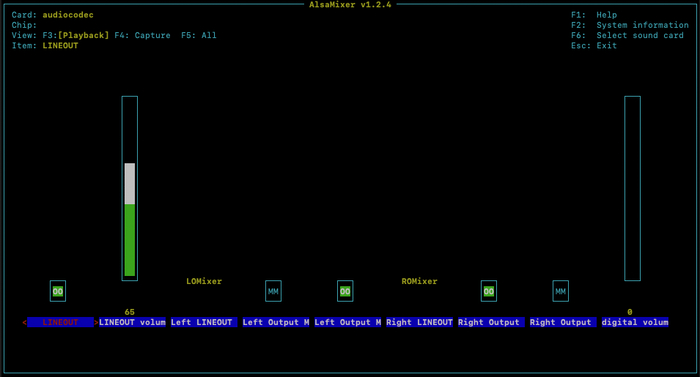
Чтобы сконфигурировать аудиовыход под наши задачи, в терминале необходимо выполнить следующую команду:
alsamixer
В консоли появится окно с аудио устройствами, нажав F6 необходимо выбрать наше устройство с именем audiocodec и выполнить настройку как отображено ниже на картинке:
После этого можно выполнить алгоритм теста аудиосистемы.
Вывод списка доступных устройств воспроизведения звука:
aplay -l
Вывод команды:
**** List of PLAYBACK Hardware Devices ****
card 0: audiocodec [audiocodec], device 0: CDC PCM Codec-0 [CDC PCM Codec-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 2: ahubhdmi [ahubhdmi], device 0: ahub_plat-i2s-hifi i2s-hifi-0 [ahub_plat-i2s-hifi i2s-hifi-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
Мы используем линейный выход, поэтому наше устройство имеет имя CDC PCM Codec-0 [CDC PCM Codec-0]. Давайте протестируем вывод звука через наше устройство.
Первое что нужно сделать — это включить наш усилитель с помощью команд:
gpio mode 18 out
gpio write 18 1
Далее нам необходимо запустить тест с помощью генератора шума, командой в терминале:
speaker-test -c2 -Dplughw:0,0 # plughw:0,0 - это адрес нашего звукового устройства
Вывод команды:
speaker-test 1.2.4
Playback device is plughw:0,0
Stream parameters are 48000Hz, S16_LE, 2 channels
Using 16 octaves of pink noise
Rate set to 48000Hz (requested 48000Hz)
Buffer size range from 32 to 131072
Period size range from 16 to 16384
Using max buffer size 131072
Periods = 4
was set period_size = 16384
was set buffer_size = 131072
0 - Front Left
1 - Front Right
Time per period = 2.742858
0 - Front Left
1 - Front Right
Time per period = 5.461073
0 - Front Left
1 - Front Right
Time per period = 0.580064
Во время теста должен наблюдаться «белый» шум из динамика, если это произошло, то подключение и настройка аудиосистемы была выполнена корректно.
В этой статье я попытался описать реализацию аппаратной части своего DIY проекта голосового ассистента для умного дома. Написание статьи отнимает большое количество времени, поэтому программную часть проекта постараюсь описать в следующем материале, если вам будет интересно.
Предугадывая ваш вопрос — «Почему бы не использовать Yandex Алису и подобные коммерческие решения?», сразу же изложу свою мысль:
Я сторонник автономных решений в плане их использования в критической инфраструктуре. А системы умного дома я отношу к этим категориям, поэтому, с моей точки зрения, использование устройств, зависящих от внешних систем, недопустимо. Описанное в статье решение не использует внешних сервисов для распознавания речи, векторизации запросов, синтеза речи и управления устройствами. И, конечно, я имею полный контроль над алгоритмами моего устройства, включая приватность.
Спасибо за ваше внимание! Ниже под спойлером несколько видео работы собранного устройства.

Многим пользователям смартфонов знакомо такие понятия как «привязка к аккаунту». У различных вендоров смартфонах есть свои механизмы защиты смартфонов от кражи: у Apple — FMI, у Xiaomi — Mi Cloud, а у Google — FRP. Однако у Android есть давняя уязвимость, которая позволяет обходить практически любые смартфоны на «чистой» системе, даже с привязкой к Google-аккаунту. Недавно мне написал известный YouTube-блогер MaddyMurk и предложил задарить смартфон-броневичок AGM H3 на гугл-аккаунте, который он не смог сбросить. Я решил подготовить подробный материал о дырах в защите Android и на практике обойти FRP на смартфоне, который «повис» на активации. Сегодня мы с вами узнаем: почему смартфоны на Android так легко обходить, какие существуют методики и почему подобная практика невозможна на устройствах Apple. Интересно? Жду вас под катом!
Ещё в нулевых, никакой привязки к аккаунтам у телефонов не существовало. Девайсы крали направо и налево: не уверен насчёт других стран, но в СНГ, к сожалению, эта практика была развита очень хорошо. Девайсы защищались максимум пин-кодом, который телефон мог запросить при смене SIM-карты, но даже его можно было обойти с помощью т.н «мастер-кодов», которые рассчитывались на специальных сайтах в различных СЦ. На некоторых телефонах помогала обычная перепрошивка — и вот, девайс снова отправлялся на БУ рынок для продажи своему новому владельцу, абсолютно чистенький и вероятно, пересобранный в новый китайский корпус. И пофиг, что IMEI-устройства уже давно числится как краденый!

Иногда, своеобразную защиту обеспечивала редкость аппаратной платформы телефона. Например, французские Sagem, которые были довольно популярны в РФ в середине нулевых, практически никто не обслуживал, несмотря на наличие программаторов на рынке. Смена IMEI же зачастую была невозможна — на телефонах Nokia, например, в внутренней памяти хранятся т.н сертификаты для активации радиомодуля и загрузки телефона. Если в процессе кривой прошивки они были повреждены или кто-то пытался их подделать, то телефон больше не включался без генерации нового сертификата за деньги на специальном сайте. Совсем.
Единственное известное мне исключение — китайские телефоны на платформе MediaTek (кнопочники Fly, Explay и.т.п) — там IMEI вполне можно поменять на какой-нибудь левый. Хоть из семерок себе сделать :)

Одну из первых и эталонных реализаций привязки смартфона к аккаунту представила Apple с выходом iPhone 4. Помимо входа в обычный аккаунт iCloud, пользователь мог включить функцию Find My iPhone, которая позволяла найти смартфон в случае кражи. Помимо поиска утерянного девайса, включенный FMI запрашивает логин и пароль пользователя при сбросе смартфона до заводских настроек (или перепрошивке). И вот здесь кроется главная фишка реализации «яблочников»: все устройства Apple, вышедшие с конвейера и прошедшие контроль качества, заносятся в некую базу данных, где хранится связка из нескольких аппаратных идентификаторов: уникальный ID процессора, который «прожигается» на заводе и остаётся
неизменяемым навсегда, уникальный ID модема (вот здесь я точно не скажу, что является идентификатором — скорее всего IMEI) и вероятно что-то ещё. Если идентификатор хотя-бы одного модуля не соответствует тому, что хранится в базе данных Apple — устройство повиснет на ошибке активации!
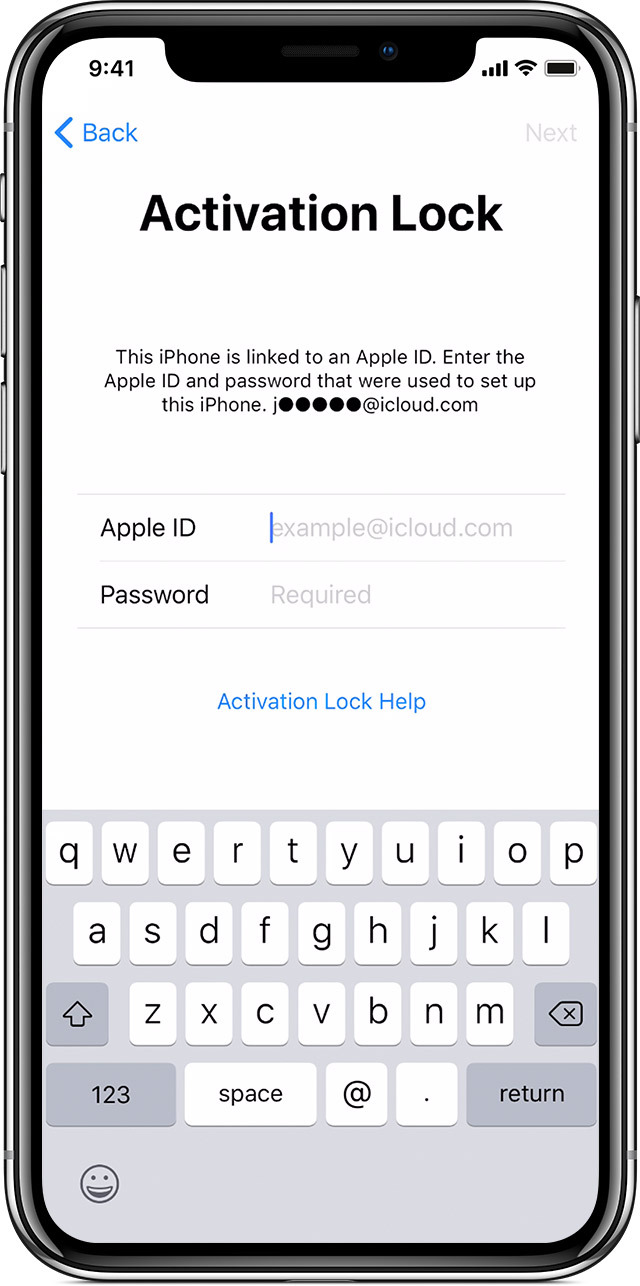
С этим даже связана одна занимательная история: iPhone 4/4s страдали отвалами модема, от чего в мастерских приловчились менять их с донорских аппаратов, при этом не перекатывая всю сборку вместе с процессором и памятью. С прилётом какого-то апдейта iOS, Apple ужесточили правила активации и многие полностью исправные айфоны повисли на ошибке активации.
Несмотря на эталонную реализацию, FMI обойти можно, если для устройства есть джейлбрейк, который можно сделать до доступа на главный экран (например checkra1n). Однако мобильная сеть и звонки работать не будут — для активации модема нужен уникальный токен, который генерирует сервер активации Apple Albert. Однако, кто-то всё-де смог отреверсить механизм работы сервера активации и завести модем на «байпаснутых» устройствах…
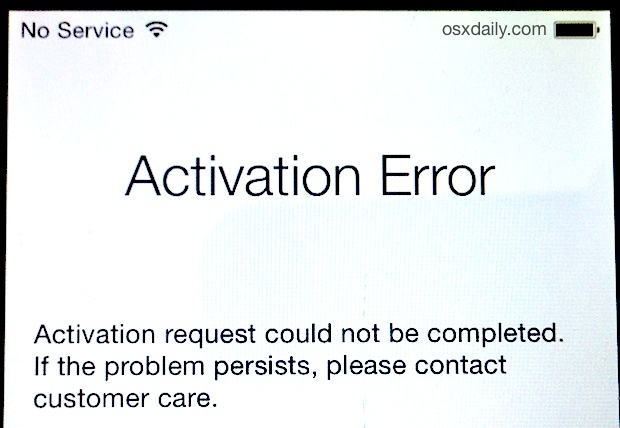
На Android-устройствах ситуация совсем иная: здесь долгое время балом правила открытость смартфонов, которая позволяла модифицировать устройства как угодно — портировать свежие версии Android, делать кастомные прошивки с различными плюшечками и оптимизациями. Долгое время люди знать не знали, что такое секьюрбут (заблокированный загрузчик) и с чем его едят…
По причинам тотальной открытости Android-смартфонов, никто особо не замарачивался с серьёзной привязкой к облачным сервисам: устройства с пин-кодом или графическим ключом без проблем обходились сбросом до заводских настроек через рекавери… до выхода Android Lolipop!

В «пятерке», Google предприняли попытку защитить устройства от сброса через рекавери с помощью механизма FRP — Factory Reset Protection, который запрашивает Google-аккаунт, если устройство не было сброшено с помощьюсоответствующего пункта в настройках. Реализована функция была крайне просто, без каких-либо аппаратных привязок: на устройствах MediaTek и Spreadtrum достаточно было забить нулями определенный раздел памяти фирменным прошивальщиком, а иногда вход в аккаунт можно было обойти различными багами операционной системы. На более старых версиях Android, можно было с помощью adb или терминала просто установить свойство, которое отвечает за показ окна активации:
content insert --uri content://settings/secure --bind name:s:user_setup_complete --bind value:s:1
Суть была в том, что Android на этапе активации просто делает шторку неактивной и прячет виртуальные кнопки домой/меню. По факту, приложения могут отсылать любые Intent («действия» в терминологии Android) системе и открывать любые приложения поверх окна активации, без каких либо ограничений. Если перезапустить приложение активации, то появлялась и полноценная кнопка «домой» и «многозадачность». Таким образом, нехитрыми манипуляциями, на смартфонах Samsung (вся A и J серия, до 2017 года) можно было зайти в браузер и затем в настройки с помощью голосового помощника, на смартфонах Asus с помощью умной клавиатуры TouchPal можно было открыть настройки и сбросить устройство до заводских в пару кликов, а в смартфонах Xiaomi была возможность написать в каком-нибудь текстовом поле youtube.com, зажать на нем палец и открыть соответствующее приложение, откуда можно снова попасть в настройки… Вариантов действительно много!

Недавно мне написал известный блогер с YouTube — MaddyMurk и рассказал занимательную историю: он нашёл «броневичок» AGM H3, который валялся в снегу и грязи несколько месяцев, абсолютно никому не нужный. Несмотря на тяжёлые условия, девайс полностью оправдал свой статус бронированного и остался полностью живым и целым! Однако, аппарат висел на графическом ключе и Миша по старой памяти решил скинуть его до заводских настроек, в надежде что владелец не входил в Google-аккаунт. После сброса, девайс повиснул на активации и Миша спросил у меня, что с ним можно сделать. По итогу, он предложил заслать девайс мне: «авось ты сможешь его оживить». Помимо AGM, Михаил прислал мне ещё кучу ништяков: несколько «сименсов» и «сонериков», кучу запчастей на iPhone 4-5, камеру и свою фирменную кассету с музыкой — за что ему спасибо :))

Однако материал был бы неполным, если бы я не показал на практике, как можно обойти абсолютно неизвестный девайс, для которого нет гайдов по обходу активации — и тем самым не показал бы вам, насколько «дырявая» защита от кражи у Android с Google-сервисами… Переходим к практике!
После включения, система встречает нас с предложением пройти первичную настройку. После подключения к Wi-Fi, нас встречает окно с предложением войти в аккаунт или ввести графических ключ прошлого владельца.
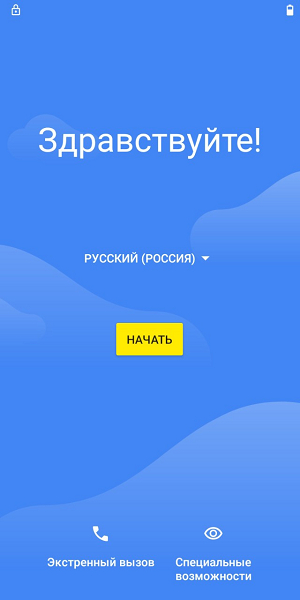
Наша задача: выйти из экрана авторизации в какое-нибудь приложение, откуда можно открыть встроенный в систему браузер. Вариантов масса: на некоторых устройствах, как уже было сказано, можно открывать ссылки, просто выделив их (таким образом, нужно открывать youtube или иной сайт с ассоциированным приложением в системе). Из тех, что я подметил: приложение «Google Фото» и YouTube подходят лучше всего. У моего смартфона нашлась аппаратная кнопка камеры слева, которая сразу же открывала соответствующее приложение. Хоба: фотографируем что-нибудь, нажимаем на превьюшку фотографии и попадаем в Google Фото!

Аппарат активно эксплуатировали до меня и хорошо затерли защитное стекло для камер — поэтому фото такое мутное.
Теперь нам нужно нажать «поделится объектом» и нажать «искать фотографию в Google». Лучше фотографировать что-то конкретное: например, другой смартфон или телевизор. Я снимал коробку от видеокарты и с помощью объектива нашёл обзор на неё на YouTube. Само собой, Google Поиск предложил мне открыть приложение YouTube для его просмотра!

После этого, нам нужно открыть боковое меню, тапнуть на «Настройки» и попытаться открыть какую-нибудь ссылку: например, лицензия на открытый софт. Делать это нужно быстро — иначе YouTube начнёт жаловаться на то, что версия устарела и смартфон придётся обходить по новой! После этого, смартфон предлагает нам открыть полноценный браузер.
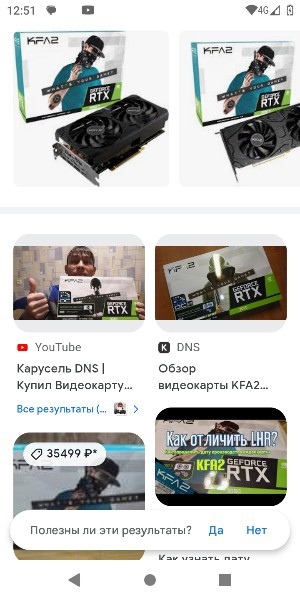

Уже бежите качать какой-нибудь лаунчер и открывать настройки? Не тут то было — Google предусмотрели этот нюанс. Вы не сможете ничего установить из скачанного — менеджер пакетов без активации не работает. Совсем. Поэтому, мы заходим в настройки Chrome -> Уведомления и тапаем по значку логотипа приложения. Мы уже в настройках!
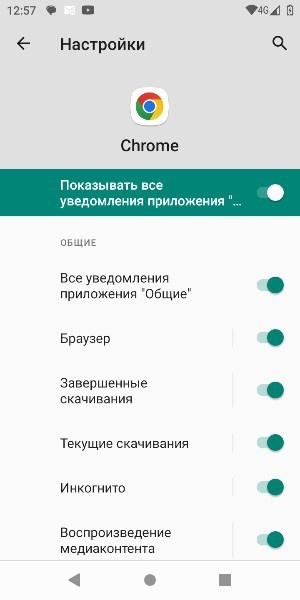
Сейчас сбрасывать устройство смысла нет: смартфон снова повиснет на активации (сброс сработает на устройствах с Android до 7 включительно). Однако есть забавный нюанс: если вовремя отключить Google-сервисы, то приложение активации просто начнёт считать, что мы активируем НОВОЕ устройство без СИМ-карты и предложит… пропустить шаг! Как забавно :)
Находим приложения с названиями а-ля «настройка системы» (кроме самого приложения Настройки) и всех их отключаем и снова включаем: у нас появятся все три кнопки навигации снизу и будет доступен диспетчер задач для более удобного процесса активации. Если у вашего устройства есть некое подобие Assistive Touch — оно тоже подойдет.
Теперь отключаем Google-сервисы и переключаемся на настройку системы. Жмём «Далее» и ждём пару секунд, но не дожидаемся ошибки Google-сервисов. Сразу же идём в настройки и включаем гуглосервисы обратно: по итогу, в один момент сервисы будут считать, что мы «оффлайн» и появится заветная кнопка «пропустить вход». Может получится не с первого раза. После этого, аппарат полностью «забудет» данные прошлого владельца и мы сможем без проблем войти в свой аккаунт :)
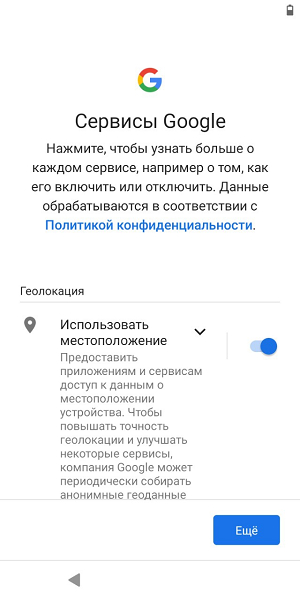

Если после этого у вас не устанавливаются приложения из обычных APK-пакетов, то тут два варианта решений: еще раз сбросить аппарат до заводских, либо устанавливать приложения с помощью adb — такой вариант тоже вполне работает:


Можно спокойно войти в свой гуглоакк.
Теперь аппарат полностью рабочий! Ретроспективу о нём не сделаешь: девайс относительно свеженький, работает на актуальной версии Android и имеет под капотом весьма неплохое железо:
Чипсет: Helio P22 с GPU PowerVR GE8320, с 8-ядрами Cortex-A53, 4 из которых работают на частоте до 2ГГц, а остальные 4 до 1.5ГГц.
ОЗУ: 4Гб
Память: 64Гб
Дисплей: 5.7 IPS-матрица. Не самая шустрая, конечно, но вполне ничего.
Аккумулятор: 5400мАч. Весьма бодро.
ОС: Android 11
В целом, весьма неплохие характеристики для современного бюджетника с приятным бонусом в виде бронированности. Уж что-что, а «бронежилет» аппарата выдержал явно многое :)
Авось кто-то из моих читателей когда-то его потерял?
Сегодня мы с вами рассмотрели некоторые базовые принципы защиты различных смартфонов от кражи и угона, а также на практике обошли плохонькую «гуглозащиту». Однако это отнюдь не призыв к действию: обходите таким образом только свои собственные смартфоны, аккаунты от которых вы когда-либо потеряли :)
Это не универсальный гайд и конкретный порядок действий может отличаться от версии Android и даже от версий оболочки. Но я рассказал, почему багами ОС можно обойти активацию и в общих принципах расписал то, почему гугловская защита такая плохая. А вы что думаете на этот счёт?
Материал подготовлен при поддержке TimeWeb Cloud. Подписывайтесь на меня и @Timeweb.Cloud, чтобы не пропускать новые статьи каждую неделю!
А ещё я завёл собственный Tg-канал, куда публикую различный бэкстейдж статей, анонсы новых материалов, опросы и ссылки на статьи в минуту выхода.
Имеется Samsung A30s.
Возможно ли сопряжение с монитором Toshiba по HDMI?
Есть ли переходник?
Да,я тупой.
Да,в Гугле смотрел, ничего не понял.
Начинаем неделю с нового экспоната в виртуальном музее советской бытовой техники. Сегодня это творение Свердловского завода радиоаппаратуры (ныне покойного) трехпрограммная радиоточка с часами и будильником. Изготовлена в 1989 году.

Размер таков, что помещается под кухонным гарнитуром. Коллега утверждает, что дизайн делался в уральском филиале ВНИИТЭ.

Из интересного - корпус из окрашенного ДВП, что для радиозавода довольно экзотичный материал. Верхняя крышка сдвигается и дает доступ к настойкам чувствительности каналов. Радиоточка трехпрограммная - дополнительные каналы модулировались ВЧ сигналом. Из детства помню, что у нас дополнительный был только один канал, на остальных была тишина.

Без электропитания можно включить радиоточку, будет работать только первый канал, для этого есть клавиши на нижней части:

Большая проблема - одинаковые разъемы для включения в сеть 220В и в радиосеть. Сколько радиоточек было сожжено из-за невнимательности? Из защиты только предохранители.

Заглянем внутрь

Часы-таймер построены на КР145ИК1901. Интерфейс управления весьма странный, инструкция это отдельный жанр как написать запутано на канцелярите.

К сожалению за много лет эксплуатации ВЛИ выгорел и подсветка едва заметна.

Инструкцию выложу на сайт музея.
Автор: kesn
Больше интересных фото и комментариев в оригинале материала

Когда на меня накатывает хандра, я бросаю всё и пилю свой игровой движок. Это неблагодарное занятие, но меня прёт.
В самом начале у меня были такие планы: вжух-вжух, щас возьму ведро, накидаю туда всяких библиотек для графики, физики и звуков, добавлю сетевую библиотеку по вкусу, перемешаю всё с какой-нибудь системой сообщений, и готово. Приключение на 15 минут.
И вот я тут спустя 5 лет.
Ладно, если быть честным, то я почти не уделял времени разработке, потому что постоянно спотыкался на всяких бесящих меня ошибках: то сериализация не работает с наследованием, то потоки не хотят нормально разделять память, то обновление языка ломало совместимость… Я могу, блин, целую Камасутру написать про соитие с игровым движком. Все эти ошибки сильно демотивируют, потому что хочется уже наконец-то заняться делом, а не ковыряться с байтиками.
Это не моё видео, но оно очень точно передаёт, как у меня происходит разработка:
С другой стороны, конечно, когда эти проблемы решаешь, чувствуешь себя богом и королём жизни, и после этого ты вроде как опять хочешь программировать. И даже кажется, что это была последняя трудность. Ха-ха, наивный!.. Но мне это нравится. Типа как альпинисты идут в гору и страдают, когда можно пойти в бар с друзьями и попить пивко. Каждому своё.
Ну и вот про одну такую ошибку я хотел поговорить. Есть такой движок — ODE (Open Dynamics Engine). Он появился где-то в палеолите, динозавры его накодили, от документации остались только царапины на скалах. Но он работает, он простой в использовании, и у него есть сишные заголовки, поэтому я мог просто написать враппер на Nim и использовать его в своём движке. В Nim вообще ни хрена нету, поэтому канонический способ — это взять какую-нибудь библиотеку из Си, научиться её вызывать, а потом говорить всем, что ты написал крутую программу на Nim.
Итак, сначала я просто добавил кубики на сцену и отрисовал их. Физический движок был в полной гармонии с графическим, и когда мне графика отрисовывала, что я приближаюсь к кубу и толкаю его, кубик действительно отлетал и вращался. Короче говоря, всё шло так, как я и планировал.
Разумеется, если вы не планируете делать Minecraft, то вам может понадобиться что-то поинтересней, чем кубик. В ODE есть специальный класс Trimesh, который как раз позволяет вам сделать сложную геометрию. Фактически, вы можете создать любое тело из набора треугольников. Типа такого:

Машина глупая, поэтому мы не можем ей сказать "нарисуй зайца", мы можем ей сказать "вот такие есть вершины, соедини их вот так-то, и это будет называться зайцем". Я, естественно, не стал рубить с плеча и решил вместо зайца сделать простой треугольник и проверить, что всё корректно с ним работает.

Я создал треугольник, он успешно отрисовался на сцене, я начал ходить по миру… и обнаружил, что треугольник не в том месте, где нарисован, а где-то непонятно где.
Так и появилась эта дурацкая невидимая стена.
Фактически, я мог ходить по сцене, и где-то я упирался в тот самый треугольник, который вообще-то должен был быть там, где нарисован. Я в принципе даже что-то такое и ожидал, потому что, как я уже где-то писал, только три раза в своей жизни я написал код, который заработал с первого раза. Наверняка я где-то перепутал координату — вместо X передал Y, или наоборот, ну что-нибудь такое. Эти программисты, вы знаете!
Отрисовать этот треугольник я не мог, потому что координаты были правильные, графический движок всё отрисовывал правильно, но вот физический движок как-то неправильно интерпретировал мои правильные данные. Поэтому я стал ходить по миру и пытаться определить очертания этой невидимой стены. В конце концов я её нашёл (она была достаточно странной), и я решил немного подвигать треугольник, чтобы посмотреть, как он влияет на эту стену. Казалось бы, если я просто где-то перепутал координаты, то подвинув треугольник, я немножко подвину эту стену. Но хрен мне там! Стена исчезала и появлялась совершенно случайно, прыгала далеко даже от малейшего изменения координат, и я не мог понять, почему.
И тут я вспомнил эту недалёкую женщину из заЩИТников! Если кто не знает, она сделалась невидимой и решила спрятаться в дожде. Отличный план, надёжный, как швейцарские часы:

Я подумал, что это прям мой случай, и решил полить свою стену дождём, чтобы увидеть её. Дождя у меня не было, зато были кубики, поэтому я создал штук 50 и стал кидать их вниз. При касании стены они к ней прилипали, и я мог видеть её очертания. А когда что-то видишь — отлаживать в разы легче!
Что ж… Это была хорошая попытка понять, по какому закону стена появляется в том месте, где она появляется, но это мне ничего не дало. Даже видя эту стену, я не находил никакой закономерности.
Если нужно где-то найти таких же неудачников, как я, то самое лучшее место для этого — интернет. И я нашёл его — единственного человека, который отстрадал своё и рассказал об этом. Представляете, в 2006 году у какого-то чувака из Германии пятая точка горела точно так же, как у меня сейчас! Не знаю, что он выкурил (похоже, что исходники), но, ОКАЗЫВЕТСЯ, физический движок ожидает от вас трёхмерные точки, но передавать их надо как четырёхмерный вектор, просто в четвертой координате надо поставить мусор, типа так: [x1, y1, z1, 0, x2, y2, z2, 0, ...]. Скажите, как по const dReal* Vertices я должен понять, что там ждут в гости четырёхмерные вершины?
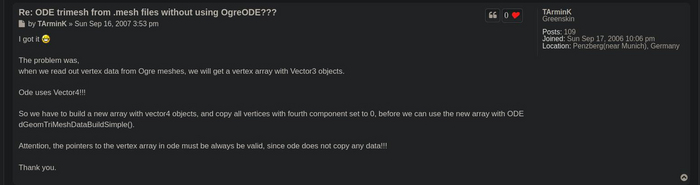
За что я люблю опенсорс — можно всегда докопаться до истоков всего. Я полез в исходники, и вот что обнаружил.
В 2003 году пришёл Russel Smith и добавил всю эту функциональность с trimesh collisions, в том числе интересующую меня строчку:
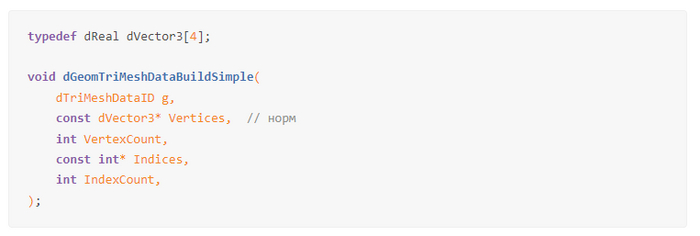
Тут всё понятно, потому что в определении чётко говорится, что dVector3 — это четырёхмерный вектор (есть некий шарм в этой логике).
А потом через пару месяцев врывается Erwin Coumans и переписывает так, чтобы тип был непонятен:
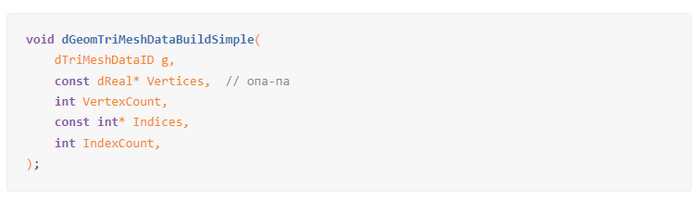

И только представьте себе, через 20 лет это изменение находит какого-то чувака (меня), который пишет вообще на другом языке программирования, и заставляет этого чувака гореть в тщетных попытках понять, какого хрена не работает.
Я переписываю код с добавлением четвертой координаты, и все начинает работать.
Такие дела.
Вообще этот пост был задуман как развлекательный, типа "смотрите, погромист опять страдает, хахаха". Но мне кажется, что он поднимает достаточно глубокую проблему: как только вы выкладываете код, он начинает свой долгий путь сквозь время. Никто не знает, когда и кто его будет читать — может, вы или ваш коллега через пару месяцев, может, тысячи независимых разработчиков через пару лет, может, какой-то парень с горящим продом.
Получается такой вот эффект бабочки, как с этой невидимой стеной. Поэтому когда вы в следующий раз сядете писать код, представьте, что какой-то разраб через 20 лет будет в нём разбираться, и, пожалуйста, постарайтесь сделать жизнь этого чувака хоть чутоку легче. Ведь однажды этим кем-то можете оказаться вы сами.
Не только лишь все могут смотреть в будущее, но вы сможете, если подпишетесь на мой уютненький канал Блог Погромиста.
А ещё я держу все свои яйца в одной корзине (в смысле, все проекты у одного облачного провайдера) — Timeweb. Поэтому нагло рекламирую то, чем сам пользуюсь — вэлкам.




