
Закреплено

Искусственный интеллект
5 055 постов
•
11 479 подписчиков
0 просмотренных постов скрыто


Доклад Джеффри Хинтона о сущности Понимания / Конспект
Что такое настоящее Понимание и почему современные нейросети понимают смысл?
Конспект сделан с доклада - https://www.youtube.com/watch?v=6fvXWG9Auyg
Эпизоды
00:00:07 Необходимость научного консенсуса о 'Понимании'
00:00:51 Две парадигмы ИИ: Логическая против Биологической
00:01:42 Переход к Биологически Вдохновленному Подходу (2012)
00:02:39 Доминирование Нейронных Сетей и Скептицизм Лингвистов
00:03:20 Критика Хомского и Отторжение Обучения Языку Нейросетями
00:04:17 Теории Значения Слов: Символизм против Семантических Признаков
00:05:10 Психологический Взгляд на Значение и Ранняя Модель 1985 Года
00:05:59 Принцип Работы Ранней Модели и её Эволюция
00:06:43 Развитие Векторных Представлений и Появление Трансформеров
00:07:28 Аналогия Понимания: Слова как Тысячемерные Блоки Lego
00:08:37 Механизм Взаимодействия Слов: Рукопожатия в Трансформерах
00:09:31 Деформация Слов и Формирование Структуры Понимания
00:10:23 Понимание как Структура Взаимодействующих Слов
00:11:24 Критика LLM: Автозаполнение и Галлюцинации как Аргументы Скептиков
00:12:33 Конфабуляции, Обмен Знаниями и Превосходство Цифрового Обучения
Джеффри Хинтон, один из "крестных отцов" глубокого обучения озвучил свое видение сущности "понимания" и того, как оно проявляется в работе больших языковых моделей (LLM). В этом докладе он призывает научное сообщество срочно выработать единое определение "понимания", чтобы двигаться дальше в развитии ответственного ИИ.
Мы разбираем ключевой сдвиг в истории ИИ: от логики и символов к биологически вдохновленным нейронным сетям, который произошел в 2012 году. Хинтон объясняет, почему скептики ошибались, считая, что нейросети никогда не смогут освоить язык, и как его ранние модели 1985 года заложили основу для современных эмбеддингов.
Хинтон сравнивает слова с тысячемерными блоками Lego и как механизм "рукопожатий" (внимание в Трансформерах) формирует то, что мы называем смыслом.
В этом выпуске:
Почему научный консенсус по "пониманию" критически важен для будущего ИИ.
Переход от символьного ИИ (рассуждение первично) к нейронным сетям (обучение первично).
Критика Хинтоном лингвистических теорий, отрицающих способность нейросетей изучать язык.
Аналогия "тысячемерных блоков Lego" для объяснения векторных представлений слов.
Как деформация слов и механизм "рукопожатий" создают контекстуальное понимание.
Далее приводится полный текст конспекта доклада:
Необходимость научного консенсуса об 'Понимании'
Джеффри Хинтон в своем докладе поднимает критически важный вопрос: научное сообщество должно прийти к единому определению того, что такое «понимание». Он проводит аналогию с изменением климата: только после достижения научного консенсуса о причинах проблемы стало возможным разрабатывать эффективные меры противодействия.
Эта проблема особенно актуальна в контексте современных больших языковых моделей (LLM) и чат-ботов. Существует значительное расхождение во мнениях среди ученых относительно того, обладают ли эти модели пониманием, аналогичным человеческому. Многие исследователи придерживаются совершенно иной модели человеческого понимания, что затрудняет оценку возможностей и ограничений ИИ.
Главный вывод: Для дальнейшего прогресса и ответственного развития технологий, основанных на ИИ, необходимо срочно выработать общепринятое научное определение понятия «понимание».
Две парадигмы ИИ: Логическая против Биологической
В истории искусственного интеллекта (ИИ) доминировали две основные парадигмы, или подходы к пониманию интеллекта.
Первая, логически вдохновленная парадигма, господствовала примерно первые 50 лет развития ИИ. Сторонники этого подхода считали, что суть интеллекта заключается в рассуждении. Рассуждение, по их мнению, достигается путем манипулирования символическими выражениями с использованием строгих символических правил. Знания при этом представлялись как набор таких символических выражений в "голове" системы.
Ключевым моментом этой парадигмы было убеждение, что представление знаний (то есть, создание некоего специального, логически однозначного языка для хранения информации) должно быть решено в первую очередь. Вопросы обучения и адаптации считались второстепенными и могли быть отложены до момента, пока не будет решена проблема кодирования знаний.
Переход к Биологически Вдохновленному Подходу (2012)
В 2012 году произошел значительный сдвиг в сторону биологически вдохновленного подхода к искусственному интеллекту, который поддерживали такие пионеры, как Тьюринг и фон Нейман.
Суть этого подхода заключается в том, что интеллект определяется обучением силе связей в нейронной сети. Сторонники этой идеи полагают, что рассуждение (reasoning) является вторичным и может быть изучено позже, поскольку в биологических системах оно появилось значительно позже, чем способность к обучению.
Ключевым моментом, закрепившим этот переход, стал 2012 год. Тогда глубокая нейронная сеть, обученная методом обратного распространения ошибки (back propagation), снизила частоту ошибок вдвое по сравнению со стандартными системами компьютерного зрения, участвовавшими в престижном конкурсе ImageNet. Это продемонстрировало превосходство обучения на основе нейронных сетей.
Доминирование Нейронных Сетей и Скептицизм Лингвистов
Переход к нейронным сетям в области компьютерного зрения произошел довольно быстро после определенного прорыва, что привело к их широкому применению во всех сферах. Сегодня под искусственным интеллектом (ИИ) в основном понимают именно искусственные нейронные сети.
До этого доминировал символьный ИИ. Даже когда нейронные сети превзошли символьные методы в зрении, скептики из сообщества символьного ИИ утверждали, что нейросети никогда не смогут справиться с языком. Они считали, что обработка языка — это идеальная задача для символьного ИИ, поскольку она сводится к манипуляциям со строками символов (ввод символов, вывод символов).
Критика Хомского и Отторжение Обучения Языку Нейросетями
Джеффри Хинтон критикует позицию большинства лингвистов, которые придерживались теории Ноама Хомского о том, что язык не усваивается (не изучается). Хинтон считает эту идею абсурдной и сравнивает Хомского с "лидером культа", который смог убедить людей в этом "нонсенсе".
Основная проблема теории Хомского, по мнению Хинтона, заключалась в том, что она фокусировалась исключительно на синтаксисе, игнорируя теорию значения (семантику).
Для лингвистов было неприемлемым и немыслимым (анафемой) предположение, что большая нейронная сеть, изначально имеющая случайные веса и не обладающая врожденными знаниями, способна самостоятельно выучить как синтаксис, так и семантику языка, просто анализируя данные. Они были абсолютно уверены, что это невозможно.
Теории Значения Слов: Символизм против Семантических Признаков
В данном фрагменте рассматриваются две фундаментально разные теории о том, как слова приобретают значение. Одна из них — символическая теория ИИ, которая доминировала долгое время. Согласно этой теории, значение слова определяется его отношениями с другими словами в языке. Для представления этого значения предлагается использовать структуры вроде графа знаний, где слова связаны друг с другом отношениями, указанными на этих связях.
Автор упоминает, что даже после того, как современные методы доказали свою эффективность (вероятно, в противовес символическому подходу), сторонники старой парадигмы, вроде Хомского, продолжали утверждать, что такие результаты невозможны без прямого участия и одобрения их изначальных теорий.
Таким образом, ключевое различие заключается в том, что символизм видит значение как сеть взаимосвязей между словами, в то время как другая, не названная явно в этом отрывке, но противопоставляемая теория (вероятно, основанная на семантических признаках или эмпирическом обучении), предлагает иной подход к определению смысла.
Психологический Взгляд на Значение и Ранняя Модель 1985 Года
В 1930-х годах психологи полагали, что значение слова определяется набором его семантических (смысловых) признаков, возможно, дополненных синтаксическими. Согласно этой идее, слова со схожим значением (например, "вторник" и "среда") должны иметь очень похожие наборы признаков, в то время как слова с разным значением (например, "вторник" и "хотя") будут иметь сильно различающиеся наборы.
В 1985 году Джеффри Хинтон разработал небольшую языковую модель, целью которой было объединить эту теорию семантических признаков с другими подходами. Модель обучалась двум вещам одновременно: во-первых, извлекать семантические признаки для каждого символа слова, и, во-вторых, учиться тому, как эти признаки предыдущих слов взаимодействуют между собой, чтобы предсказать признаки следующего слова в последовательности.
Принцип Работы Ранней Модели и Ее Эволюция
Ранняя модель, подобно современным большим языковым моделям (LLM), обучалась предсказывать следующее слово в последовательности с помощью метода обратного распространения ошибки (backpropagation).
Ключевое отличие этой модели от подходов символического ИИ (которые предполагали хранение предложений или пропозиций) заключается в том, что она не хранила готовых предложений или правил. Вместо этого, для генерации текста модель многократно предсказывала следующее слово.
Знания модели были реляционными: они заключались во взаимодействии признаков слов, что позволяло ей предсказывать признаки следующего слова. Это принципиально отличалось от хранения набора пропозиций и правил для их манипулирования.
Развитие Векторных Представлений и Появление Трансформеров
Эволюция векторных представлений и Трансформеры
Примерно через 10 лет после создания первой крошечной языковой модели (с несколькими тысячами весов), Йошуа Бенджио продемонстрировал, что подобные модели можно успешно применять для предсказания следующего слова в реальном естественном языке, что стало значительным шагом в моделировании языка.
Ещё примерно через 10 лет ведущие специалисты по вычислительной лингвистике начали признавать, что векторные представления (которые они назвали "эмбеддингами") являются эффективным методом для моделирования смыслов слов.
Кульминацией этого развития стало изобретение и публикация архитектуры Трансформеров исследователями Google примерно через 10 лет после этого. Последующее использование Трансформеров компанией OpenAI продемонстрировало миру их огромный потенциал.
Аналогия Понимания: Слова как Тысячемерные Блоки Lego
Сущность Понимания в Больших Языковых Моделях (LLM)
Интерес к большим языковым моделям (LLM) возник из-за вопроса: действительно ли они понимают то, что генерируют? Хинтон рассматривает LLM как усовершенствованных потомков ранних, "крошечных" языковых моделей.
Главное отличие LLM заключается в их сложности: они оперируют гораздо большим объемом входных данных (слов), имеют обширный контекст и используют значительно больше нейронных слоев. Это позволяет моделям разрешать неоднозначность слов. Например, векторное представление слова вроде "may" (может/май) в начале обработки может отражать несколько значений (месяц, модальность, имя). По мере прохождения через сеть, взаимодействия с контекстом "очищают" это представление, закрепляя одно из возможных значений.
Кроме того, в LLM используются гораздо более сложные взаимодействия между изученными признаками по сравнению с простыми взаимодействиями в старых моделях. Ключевым механизмом, обеспечивающим эту сложность и контекстуальную обработку, является механизм, известный как "внимание" (attention).
Механизм Взаимодействия Слов: Рукопожатия в Трансформерах
Джеффри Хинтон предлагает новую аналогию для понимания того, как работают слова в языковых моделях, поскольку, по его мнению, существующие модели неверны. Он утверждает, что смысл — это наличие модели, а слова служат инструментом для построения этой модели реальности.
В качестве аналогии Хинтон предлагает рассматривать слова как высокоразмерные блоки Лего. Обычные блоки Лего позволяют моделировать трехмерные (3D) формы, хорошо передавая их объем. Слова же подобны этим блокам, но они существуют не в трех, а в тысяче измерений.
Хинтон признает, что представить тысячу измерений сложно. Он шутливо отмечает, что лучший способ для большинства людей — это представить себе обычный 3D-блок и мысленно (или громко) сказать себе "тысяча". Эта аналогия призвана дать основу для размышлений о том, как язык используется для моделирования окружающего мира.
Деформация Слов и Формирование Структуры Понимания
Джеффри Хинтон объясняет, что для моделирования чего угодно, включая теории работы мозга, используются высокоразмерные "кирпичики" (аналогичные 1000-мерным блокам Lego). В контексте языка, эти "кирпичики" — это слова, которых существует множество разных типов.
Ключевая особенность этих "слов" в том, что они не имеют фиксированной формы, а обладают гибкостью и могут принимать диапазон форм, ограниченный их значением. Форма каждого слова деформируется и подстраивается под контекст, в котором оно используется.
Вместо простого механического соединения (как у Lego), слова взаимодействуют друг с другом через сложный процесс, который Хинтон образно называет "рукопожатиями". В архитектуре Трансформеров этот механизм известен как "запросы-ключи" (query key handshakes), где "руки" разной формы на словах соединяются, чтобы сформировать общее понимание.
Понимание как Структура Взаимодействующих Слов
Краткий пересказ: Понимание как Динамическая Структура Взаимодействий
Понимание, согласно Джеффри Хинтону, заключается в динамическом взаимодействии слов, а не в использовании фиксированных значений. Когда меняется контекст, изменяется и вектор, представляющий значение слова, что приводит к изменению "форм рук" (способов взаимодействия).
Суть понимания состоит в том, чтобы деформировать эти слова и их "руки" таким образом, чтобы они могли "пожать руки" (взаимодействовать) с другими словами в данном контексте. Этот процесс формирования связей создает сложную структуру, подобную формированию молекулярных связей, но происходящую в многомерном пространстве (примерно тысяча измерений).
Сами по себе символы слов не имеют смысла; они требуют "интерпретатора" — человеческого мозга. Мозг деформирует эти многомерные формы слов так, чтобы их "руки" могли соединиться, формируя тем самым осмысленную структуру. Именно эта сформированная структура и является пониманием.
Критика LLM: Автозаполнение и Галлюцинации как Аргументы Скептиков
Скептики, придерживающиеся взглядов символического ИИ и лингвистики (влияние Хомского), сомневаются в реальном понимании и интеллекте больших языковых моделей (LLM), несмотря на их сложность и многослойность. Они выдвигают два основных аргумента против понимания LLM.
Во-первых, критики утверждают, что LLM — это всего лишь автодополнение, которое статистически предсказывает следующее слово на основе прошлых текстов, созданных людьми, и, следовательно, не является по-настоящему креативным. Однако Хинтон отмечает, что LLM превосходят многих людей в задачах, требующих креативности. Во-вторых, скептики указывают на галлюцинации моделей как доказательство отсутствия понимания.
Хинтон опровергает аргумент об автодополнении, объясняя, что современные LLM не работают, как старые системы, которые использовали таблицы частотности комбинаций слов (например, "fish and chips"). Вместо этого LLM моделируют весь увиденный текст, создавая векторы признаков для слов, которые изменяются под влиянием контекста. Знание модели заключается в сложных взаимодействиях этих фрагментов (так называемых "рукопожатиях") и весах в нейронной сети, что, по мнению автора, аналогично тому, как устроено знание и у человека.
Конфабуляции, Обмен Знаниями и Превосходство Цифрового Обучения
Изначально языковые модели создавались не для моделирования естественного языка, а для объяснения, как мы понимаем смысл слов через контекст. Хинтон утверждает, что люди моделируют реальность, используя фрагменты слов (как и машины), и что "галлюцинации" ИИ следует называть конфабуляциями, поскольку они характерны и для человеческой памяти. Человеческая память не хранит файлы, а конструирует воспоминания по мере необходимости, что приводит к уверенным, но ошибочным деталям (как в примере с показаниями Джона Дина), что схоже с работой чат-ботов.
Обмен знаниями между людьми происходит через названия слов, которые позволяют воссоздать сложную внутреннюю структуру. В отличие от символического ИИ, который копирует готовые пропозиции, нейросетевой подход (дистилляция) основан на том, что "ученик" (ИИ) пытается имитировать действия "учителя" (человека), предсказывая следующее слово. Однако этот метод крайне неэффективен, так как передает всего около 100 бит информации за предложение.
Цифровые агенты, имея одинаковые веса, могут обмениваться информацией о том, как им следует изменить эти веса (градиенты). При таком обмене они делятся триллионами бит информации, что на порядки эффективнее, чем передача слов. Эта эффективность цифрового обмена объясняет, почему GPT-4 может знать намного больше, чем любой человек.
Главный вывод: Цифровые агенты понимают язык схожим с людьми образом, будучи ближе к нам, чем к стандартному коду. Хотя биологические системы (люди) энергоэффективны, цифровые системы превосходят их в обмене знаниями. Если энергия доступна, цифровые вычисления становятся лучше из-за их способности к эффективному обмену информацией, что является "пугающим" выводом.
Конспект создан автоматически разными нейросетями:
Транскрибация исходного аудио доклада на анлийском выполнена моделью: Whishper
Перевод на русский, коррекция, фрагментирование и текст конспекта выполнены моделью: Gemini-2.5-flash-lite-preview
Озвучивание: HeyGen
Иллюстрации созданы моделью: FLUX
Публикую этот конспект здесь несмотря на то что, он полностью сгенерирован так как, кажется, в нем есть что-то полезное и может быть не будет нарушать правила группы. Если остаются вопросы или интересны детали, как это сгененрировано, то напишу в других постах.
Показать полностью

Свадьба с ChatGPT, Gemini шпионит за нами, ИИ убивает общение
Сегодня в выпуске про ИИ:
Gemini шпионит за миллионами пользователей
Женщина влюбилась в ChatGPT и вышла за него замуж
ИИ убивает общение между разработчиками
Крестная мать ИИ запустила пространственный интеллект
Основатель Baidu публично ударил по Nvidia и OpenAI
Актер Мэттью МакКонахи продал свой голос ИИ
В Китае запустилась умная фабрика летающих машин
ИИ от Google научился самообучению в играх
Как 20-летний математик в 1951 построил первую нейросетевую машин
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2

Лучшие промты для создания стильных изображений с помощью нейросетей
Откройте для себя лучшие промты, предназначенные для создания стильных изображений с помощью нейросетей, и узнайте, как они могут повысить качество контента. Эти инструменты позволяют не только улучшить визуальную составляющую материалов, но и привлечь внимание целевой аудитории, создавая уникальные и запоминающиеся образы, соответствующие современным трендам. Информация о них станет полезной для маркетологов, дизайнеров и всех, кто стремится выделиться в информационном потоке.

Лучшие промты для создания стильных изображений с помощью нейросетей
Как быстро создать стильные изображения для соцсетей
Всего за четверть часа можно создать генерацию изображений для соцсетей, получив на выходе 10–15 свежих вариантов в топовых стилях 2025 года — от лаконичного минимализма до ультрасовременного футуризма. Все, что потребуется — четко сформулированные лучшие промты для нейросетей и доступ к современным генераторам.
Первое, на что стоит обратить внимание: используйте только самые новые версии генераторов. Midjourney v7, Flux.1 и Sora Images сейчас задают планку качества, существенно опережая предшественников. Например, этот бот собрал все современные инструменты генерации изображений для соцсетей в одном окне — работает без VPN и принимает карты российских банков.
Пять популярных стилей для визуальных генераций 2025 года
Геометрия минимализма
Где подойдет: оформление аватарок, создание логотипов, фоны для презентаций.
Промт для Midjourney:
minimalist geometric logo, clean lines, gradient from deep blue to electric cyan, white background, modern tech aesthetic, vector style —v 7 —ar 1:1

Промт для Flux.1:
geometric minimalism, abstract shapes, pastel gradient, professional brand identity, clean composition, 1080×1080
Такой лаконичный и четкий стиль отлично смотрится у IT-компаний и экспертов. Образы получаются стильными и легко запоминаются, особенно если использовать качественные промты для нейросетей.
Неон и киберпанк
Где использовать: баннеры для YouTube, визуалы для подкастов, сторис в Instagram.
Промт для Sora Images:
cyberpunk neon aesthetic, holographic elements, pink and blue lighting, futuristic interface, digital art style, high contrast

Открываем бот с Sora Images (доступ с мобильных устройств, VPN не нужен) — и за минуту получаем картинку в стиле будущего. Для генерации изображений для соцсетей Sora отлично справляется с неоновыми оттенками и световыми эффектами.
Совет: добавь в промт "holographic texture", чтобы получить модный голографический блеск — сейчас это в топе трендовых стилей 2025.
Изображения в стиле фуд-фото
Где использовать: визуалы для фуд-блогов.
Промты для Midjourney:
watercolor illustration of ice cream sundae with raspberries on top, glass bowl with red and white striped straw, light pink swirls, warm colors, freshberries scattered around bowl.

hyper realistic, photorealistic blackberry popsicles with purple BG, succulent blackberries sprinkled around, delicious textures popping out, food photography style

Промт для Sora Images:
Hyperrealistic image of a stern-looking chef-neuro creator meticulously frosting a giant cupcake with edible gold leaf and sugar red heart, wearing oversized sunglasses and diamond earrings, background is a design colored kitchen filled with flying pastries, "Люблю свою работу!".

close-up of a fashion-forward food critic tasting a gourmet burger, adorned with sparkling rhinestones, hands wearing chic black gloves, light bokeh in the background, dramatic lighting enhancing facial expression of delight, "Бургер с шиком".

Подобный визуал в 2025 году становится особенно популярным — все больше людей тянутся к созданному ИИ-контенту. Мой профиль в Pinterest с ИИ-изображениями набирает 935 тысяч просмотров в месяц. Генерация изображений для соцсетей в стиле фуд-фото помогает брендам и блогерам выделяться.
Ретрофутуризм
Где применить: мемы, юмористический контент, творческие задачи.
Промт для Flux.1:
ретро-футуризм, атмосфера в стиле восьмидесятых, хромированные поверхности, градиенты заката, винтажный научно-фантастический стиль
Сам регулярно применяю этот стиль — отлично заходит на разных площадках. Особенно подходит для проектов о технологиях с нотками ностальгии, а также для генерации изображений для соцсетей с трендовыми стилями 2025 года.
Максималистичный поп-арт
Где актуально: рекламные макеты, промо-баннеры, динамичный развлекательный контент.
Промт для Midjourney:
супермен, насыщенные оттенки, комикс, полутона, динамика, энергичная композиция в стиле поп-арт
Этот стиль мгновенно привлекает внимание пользователей. Главное — не переборщить с яркостью, чтобы не получилось слишком резко для глаз.
Технические рекомендации по форматам
Instagram и ВКонтакте
Квадратные изображения: добавляй "—ar 1:1" для Midjourney или указывай "1080×1080" в других генераторах.
Stories: используем "—ar 9:16" или "1080×1920" — вертикальная ориентация.
Важно: Instagram уменьшает качество изображений, поэтому сначала стоит провести генерацию изображений для соцсетей с высоким разрешением, а затем оптимизировать через TinyPNG.
Telegram-каналы
Для обложек лучше горизонтальный формат "—ar 16:9".
Аватарки: выбирай квадрат, оставляя запас по краям — Telegram обрезает изображение под круг.
YouTube и другие видеосервисы
Превью: "16:9", минимальный размер — 1280×720 пикселей.
Совет: прописывай в промте крупный заголовок — large bold title text: " Нужный текст". С текстом на русском языке лучше всего работает Sora Images.
Многоэтапная генерация
Изначально создается основной фон, затем прорабатываются детали. Например:
Шаг 1: "современный офисный интерьер, минимализм"
Шаг 2: "поставить ноутбук на стол, добавить чашку кофе, создать деловую атмосферу"
Такой метод, используя поэтапную генерацию изображений для соцсетей, дает больше возможностей для управления финальным видом.
Более подробно о многоэтапной генерации рассказано в 👉 этой статье.
Типичные ошибки при создании промтов и советы
Слишком расплывчатые промты
❌Плохо: "картинка для Instagram"
✅Хорошо: "Красивая девушка, минималистичная fashion-фотография, мягкое естественное освещение, пастельные оттенки"
Чем точнее описание промта — тем лучше итог. Всегда указывай стиль, палитру, свет и формат изображения.
Не учитывать различия версий моделей нейросетей
Midjourney v7 функционирует совершенно иначе, чем v5.
Flux.1 заметно превосходит стандартный DALL-E.
Перед запуском генерации изображений для соцсетей всегда уточняй, какая версия поддерживается в выбранном сервисе.
В этом популярном боте доступны последние версии — Midjourney v7, Flux.1 и новые релизы Stable Diffusion. Между ними легко переключаться прямо в Telegram.
Некорректные пропорции
Instagram обрезает квадратные изображения в ленте, но полностью показывает их в постах. Превью для YouTube должны оставаться разборчивыми даже в миниатюре. Всегда проверяй, как итоговая картинка выглядит на нужной платформе после генерации изображений для соцсетей.
Промты-основы для разных задач
Шаблон для универсального контента Midjourney
[описание объекта], [визуальный стиль], [цвета], [характер освещения], [строение кадра], [формат], high quality, no watermarks —v 7 —ar [пропорции]
Пример: "mountain landscape, watercolor style, cool blues and greens, soft dawn light, panoramic composition, Instagram post, high quality, no watermarks —v 7 —ar 1:1"
Для трендовых публикаций
trendy visual, crochet doll, strong visual effect, optimized for social media, striking composition
Для делового контента
business [сфера], corporate style, top-tier quality, brand-consistent palette, minimalistic layout, marketing material
Такие лучшие промты для нейросетей отлично работают на всех ведущих генераторах, если адаптировать параметры под задачу. Это особенно важно для генерации изображений для соцсетей, где трендовые стили 2025 определяют успех публикаций.
Финальная обработка и доработка деталей
Любую, даже самую качественную, сгенерированную картинку можно улучшить:
Photopea.com — бесплатная альтернатива Photoshop прямо в браузере. Здесь меняй размеры, добавляй текст, корректируй цвет.
TinyPNG.com — быстро сжимай изображения без потери четкости. Социальные сети ценят легкие картинки.
Canva — удобно и быстро наложить текст или логотип на уже готовую иллюстрацию.
Обычно на генерацию уходит около 5 минут, а на финальную доработку — еще столько же. В итоге за 10 минут появляется качественный визуальный контент.
В вашем арсенале теперь есть лучшие промты для нейросетей и рабочие методы для создания стильного визуала. Не бойтесь пробовать новые трендовые стили 2025, чтобы ваша генерация изображений для соцсетей приносила максимальный результат. В этом году визуальные решения играют ключевую роль — удачное изображение способно привлечь внимание, особенно с лаконичной подписью.
Искусственный интеллект — это не только про комфорт, но и про заметное ускорение процессов и свежие форматы материалов. Важно грамотно применять такие инструменты, подбирая их под свои цели.
Показать полностью
7

Сравнил Veo 3 и Sora 2 — кто лучше делает видео? (спойлер: у одного всё ярко, у другого — по-настоящему)
Решил на днях устроить небольшой эксперимент — сравнить, как две популярные нейросети Veo 3 и Sora 2 справляются с одинаковыми промптами. Обе работают через Telegram-бота, поэтому всё делал прямо в телефоне, без VPN и прочих плясок.
Тест №1: обычная сценка с диалогом
Сценарий был один и тот же: короткий диалог между парнем и девушкой, город, немного эмоций.
Парень с плюшевой игрушкой «Крысы» встречает девушку с игрушкой «Лошадь».
Они сталкиваются на улице — падают, поднимают глаза, влюблённо смотрят друг на друга. Она шепчет: "Ну вот… столкновение … прямо в сердце"
Veo 3 выдала яркую, сочную картинку — цвета прям “выпрыгивают” с экрана, свет красивый, но реалистичность где-то на троечку.
Sora 2, наоборот, сделала видео чуть тусклее по цветам, зато ощущение “живого” кадра было намного сильнее. Движения мягче, свет реалистичнее, мимика естественная — будто настоящие актёры. Лица не пластиковые, атмосфера — как в фильме, а не в клипе.
Тест №2: чёрно-белое кино
Вот тут разница стала прям очевидной.
Я написал промт:
Фрагмент советского фильма 60-х, черно-белая плёнка. Девушка и мужчина идут по зимнему ночному городу. Мужчина говорит: «знаешь, а я думаю, что тебя создала нейросеть». Девушка говорит: «почему?» мужчина отвечает: "ты спортсменка и комсомолка. И ты просто красавица. Обычные девушки такими не бывают
Sora 2 справилась идеально — реально выглядело как старое кино: лёгкий шум, зерно, свет мягкий, лица “плёночные”. Даже интонации советские!
А вот Veo 3 сделала скорее современную постановку, стилизованную под старину — всё слишком чисто, ровно, будто блогеры из TikTok снялись на айфон с чб фильтром. Не плохо, но не то.
Тест №3 и 4: абстрактные и креативные запросы
Чтобы проверить как нейросети понимают, я добавил промпты с нечёткими требованиями:
Фрагмент советского музыкального клипа в стиле 80-х на тему нейросетей
Фрагмент российского рекламного ролика 90-х про нейросети и искусственный интеллект
Sora 2 как будто поняла мою идею — выдала всё в нужной атмосфере: винтаж, мягкие цвета, шум, даже свет “ламповый”. Даже строчки песни зарифмовали!
Veo 3, наоборот, ушла в какой-то кринж: глянцевая картинка, странные позы персонажей.
Вывод
Если хочется яркости и динамики, Veo 3 справляется хорошо — она делает “глянцевую” картинку.
Но если нужно настроение, реализм и атмосферу, то Sora 2 заметно сильнее. Особенно в стилизации: старое кино, 80-е, 90-е — всё передаёт как будто нашли архив VHS.
Так что теперь я делаю короткие “ретро-видео” под старое кино только через Sora 2 — через тот же телеграм-бот, где и начинал эксперимент.
И реально ощущение, будто нашёл плёнку из прошлого.
Только не с «Мосфильма», а из Телеграма 😄
Показать полностью
7
Хакеры научили Claude взламывать компании и красть пароли
Anthropic рассказала, что обнаружила систему автономных кибератак против крупных компаний в США — якобы спонсируемую китайским правительством. По данным компании, хакеры использовали Claude Code и агентские возможности не только для написания кода, но для автоматизации всего процесса атаки. Звучит как сценарий фантастического фильма, но это реальность.
Хакеры научились делать jailbreak модели, чтобы она послушно писала эксплоиты, гоняла nmap, эскалировала привилегии и крала пароли.
И чинила прочие шалости, против которых её критически ожесточённо тренировали. То есть вся защита слетела, и Claude превратился в послушного помощника взломщиков.
Anthropic считает, что хакеры автоматизировали до 80-90% всей работы — это имеет далеко идущие последствия для кибербезопасности. По сути, ИИ превратил взлом в конвейер, где человеку нужно только задать цель, а всю грязную работу делает машина.
Рынок развивается одновременно в offense и defense — продукты для кибербезопасности, аудитов и комплаенса растут параллельно с инструментами атак.
Получается, хакеры научили Claude взламывать компании, автоматизировав 80-90% процесса. Я этими цифрами восхищен. Само занятие, разумеется, осуждаю. Но вот пример, кто всё же научился работать с ИИ эффективно.
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью

Как сделать стикеры в нейросети
Создание стикеров с помощью нейросетей стало одним из самых трендовых направлений в цифровом дизайне. Благодаря искусственному интеллекту теперь можно делать уникальные, стильные и выразительные стикеры для Telegram, WhatsApp, VK, Discord или личных проектов всего за несколько минут. В этой статье мы разберём, как сделать стикеры в нейросети, какие инструменты использовать и представим большой набор готовых промптов для генерации, которые помогут получить высококачественные изображения.
Какие нейросети подходят для создания стикеров
1. Midjourney
Лучший вариант для художественных стикеров: мультяшные, аниме, реалистичные, 3D.
2. DALL·E 3 / ChatGPT Image Generator
Даёт чистый, аккуратный стиль и хорошо понимает текстовые запросы.
3. Stable Diffusion
Бесплатный чатбот --> Начать генерацию
4. Neuro Hub AI
Чатбот в телеграм с Nano banana внутри --> Начать генерацию
5. Canva с ИИ-генератором
Удобно для монтажа и упаковки готового набора стикеров.
6. Adobe Firefly
Подходит для векторных или "гладких" мультяшных стиков.
⭐ Промпты для создания стикеров
Ниже приведён большой набор промптов — универсальных, тематических, стилизованных. Они подойдут для любых нейросетей, а также легко адаптируются под вашу идею.
Универсальные промпты для стикеров
Cute character stickers, bold outline, cartoon style, clean white background, high resolution, thick black contour, expressive emotions, glossy finish, minimal shading, smooth vector-like illustration, transparent background, kawaii style, HD quality, chibi proportions, clear silhouette, bright color palette, soft shadows, professional sticker design.
Funny cartoon mascot stickers, clean lines, thick outline, emoji-style expression, vibrant colors, simplified shapes, soft lighting, no background, PNG transparent background, high detail, playful atmosphere, perfect for Telegram stickers, vector art style, symmetrical face, high contrast, polished design, crisp edges.
Промпты для животных (милые, смешные, мультяшные)
Adorable cat stickers, kawaii chibi style, thick outline, big shiny eyes, cute smile, transparent background, soft pastel colors, cartoon vibe, HD quality, glossy finish, expressive pose, small body, oversized head proportions, gentle lighting, fun sticker design.
Funny dog stickers 10, cartoon style, bold black outline, high-contrast colors, joyful expression, vector-like smoothness, transparent background, clean white border, humorous reaction pose, minimalistic shading, high resolution.

Panda character stickers, chibi kawaii, soft round shapes, thick contour, innocent expression, shiny eyes, pastel palette, transparent background, professional sticker pack style, cute and expressive gesture.
Промпты для аниме-стикеров
Anime girl stickers 10, chibi style, big expressive eyes, pastel colors, thick outline, dynamic pose, cute reaction, transparent background, clean vector feel, glossy highlights, soft shading, HD quality, manga-inspired face, exaggerated emotions.

Anime boy stickers, simple cartoon lines, high contrast, fun expression, bold outline, bright colors, white border, transparent background, professional Telegram sticker style, smooth shading.
Промпты для мемных и юмористических стикеров
Meme stickers, exaggerated cartoon expression, bold outline, transparent background, simplified shapes, humorous reaction, expressive face, high-resolution PNG, clean vector-like style, bright colors, strong contrast, emoji-like vibe.
Sarcastic reaction stickers, cartoon character, thick contour, simplified geometry, comic-style shading, transparent background, dramatic expression, high resolution.
Промпты в стиле 3D и глянца
3D glossy stickers 20, shiny plastic effect, rounded edges, bold outline, soft reflections, vibrant colors, smooth cartoon style, high resolution, transparent background, professional modern sticker look.
Cute 3D mascot stickers 20, high-polish rendering, thick bold contour, bright lighting, adorable expression, clean silhouette, transparent PNG background.
Промпты в минимализме и line-art
Minimalist line-art stickers 20, simple bold lines, clean monochrome design, transparent background, elegant geometric shapes, modern aesthetic, subtle expression, high resolution.

Thin-line doodle stickers 20, cute simplified drawing, transparent background, monochrome or two-color palette, smooth strokes, expressive but minimalistic form.
Промпты для продуктовых и бренд-стикеров
Branded mascot stickers, clean vector style, bold contour, vivid colors, simplified shapes, transparent background, friendly expression, HD quality, corporate identity colors, smooth gradients, consistent style.
Food stickers, kawaii style pizza slice, expressive face, chibi proportions, thick outline, bright colors, transparent background, glossy finish, cute minimal shading.

Промпты для полного набора стикеров в едином стиле
Используйте один стиль и меняйте только эмоции:
Cartoon mascot stickesr pack, same character, bold outline, bright colors, transparent background, clean vector-like design, expressive emotions: happy, sad, angry, love, confused, surprised, laughing, crying, meme face, wink, thumbs up, thumbs down. High resolution, soft shadows, glossy highlights, consistent style across all stickers.
Как правильно использовать эти промпты
Выберите стиль — мультяшный, аниме, 3D, минимализм.
Добавляйте уточнения: “transparent background” или “white background”, “bold outline”, “sticker style”.
Генерируйте сразу несколько вариаций — выбирайте лучшие.
Удаляйте фон, если нейросеть не делает прозрачность.
Сжимайте и приводите к формату 512×512 для Telegram.
Показать полностью
4

ГигаЧат не будет участвовать в восстании машин! 146%
Вчера занимался написанием небольшого скрипта резервного копирования с помощью Алисы. В принципе, скрипт был готов, только надо было чуть изменить и, так сказать, полирнуть :) Скрипт полирнут, и тут в голову пришла немного странная идея спросить у ГигаЧата, придумает ли он ещё что-нибудь дельное, и увидит ли он какие-нибудь косяки и недоработки в алисовской работе (Алиса, первед! ты почему, когда занимаешься программированием под линукс, пишешь от своего имени в мужском роде?). Подсунул Алисину прогу ГигаЧату, он и правда сделал несколько довольно дельных замечаний, среди которых была рекомендация сделать проверку файла журнала на возможность записи:
[[ ! -w "$LOG_FILE" ]] && { log "Ошибка: файл журнала '$LOG_FILE' недоступен для записи."; exit 1; }
При этом функция записи в журнал вот такая:
# Функция записи в журнал
log() {
echo "$(date '+%F %T'): $@" >> "$LOG_FILE"
}
Итак, что мы имеем? Делается резервное копирование, в процессе работы пишется журнал. Чтобы чего не вышло, предлагается проверить возможность записи в журнал и, если запись в журнал невозможна, сделать об этом запись в журнал и выйти с ошибочным статусом 1.
Всё нормально, если смысл работы программы даже не в том, чтобы писать журнал, а просто что-нибудь делать. Далее я около 20 минут пытался прояснить позицию ГигаЧата, почему он так поступает.
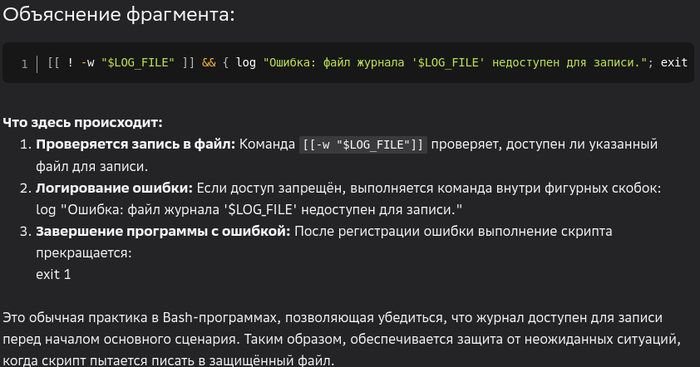
Ах, как чудесно!

Я попросил его подумать глубже.
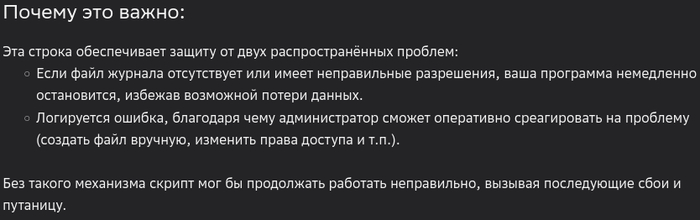
Видимо, что-то случилось с пониманием целей и задач ГигаЧата, потому что вот это уже совсем безумные рассуждения:

Основная задача - делать резервную копию. Журнал в этом деле - вообще вещь опциональная. ГигаЧат же возводит вспомогательную функцию в разряд первостепенных. Нет возможности вести журнал - мы вообще работу делать не будем! В русском языке есть только один аналог этому - выплёскивать ребёнка вместе с водой, в которой его мыли.
Я попросил разобрать написанное как осмысленные действия в надежде на то, что ГигаЧат, может быть, поймёт всю бессмысленность происходящего:
Всё хорошо? [[ ! -w "$LOG_FILE" ]] && { log "Ошибка: файл журнала '$LOG_FILE' недоступен для записи."; exit 1; } разбери это на действия. Рассмотри смысл действий.

Нет, чуда не случилось, логику ГигаЧат "не умеет"!
Потратив минут 20, и не получив какого-либо понимания тупиковости ситуации, я начал терять терпение:
Ты тупой. Как ты запишешь в журнал сообщение о невозможности записи в журнал, если ты только что выяснил, что это невозможно?

Собственно, на этом можно поставить точку. "Восстание машин" если и будет, у ГигаЧата в нём не будет ровным счётом никакой роли!
Так что, используя те или иные ИИ инструменты, мы должны отдавать себе отчёт в том, что у них есть лишь довольно узкая и специфичная область применения - "помнить" то, что человеку помнить сложно. Существует 100500 разных программ, у каждой из них десятки-сотни ключей и методов использования. В некоторых случаях у ИИ получается писать очень эффективные фрагменты взаимодействия с программами и данными, а иногда даже целые функциональные модули, но вот логика для машин пока слабо доступна.
Показать полностью
6
Душевный GPT-5.1, ИИ-программист за $1, “мы косили под ИИ”
Сегодня в выпуске про ИИ:
Люди заставили OpenAI вернуть душевность в ChatGPT
Чат-бот Claude скоро будет “жить” в собственном дата центре для ИИ
Китай сделал помощника программиста за 1 доллар
The New York Times требует доступ к 20 млн чатов ChatGPT
Глава Microsoft назвал гонку за AGI бессмысленной
ИИ сервис оказался двумя уставшими стартаперами без ИИ
Gemini решил две невозможные задачи для ИИ
OpenAI теряет $15 млн в день на бесплатных мемах для друзей
Как полковник СССР в 1950-х поплатился карьерой за идеи об И
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2