
Закреплено

Stable Diffusion & Flux
4 700 постов
•
2 289 подписчиков
0 просмотренных постов скрыто


Энтузиасты сделали машину по стилизации изображений нейросетью из старого телефонного коммутатора. Люблю такие штуки
Используется нейросеть Stable Diffusion.
__
Нейроновости - новости обо всем что касается нейронок. Midjourney, Stable Diffusion, ChatGPT и о тех о которых вы могли не слышать.
Мой канал с гайдами по SD. Где бесплатно обучаю с нуля и до самостоятельного обучения моделей.
Показать полностью

Как сделать эффект пикселей CRT-screen (ЭЛТ-монитора) в Photoshop

Перед прочтением предупрежу, что в гайде будет очень много повторений слова "пиксель", учтите это перед ознакомлением, пожалуйста.
В последнее время очень увлекся стилем synthwave VHS, даже для прошлого поста про художников замутил обложку, придерживаясь всех канонов. Досконально разобрал стиль и заболел им — так появилась эта инструкция.
Что нам понадобится?
Героем программы сегодня станет Adobe Photoshop. А в напарники к нему пойдет черно-белый исходник моего логотипа. Цветные варианты тоже подойдут, скажу пару слов об этом в конце.
Перейдем к практике
Для начала создадим черную заливку и загрузим логотип в Photoshop — кадрируем под нужное нам соотношение сторон и располагаем там, где нужно. Пока выглядит совсем не олдово, но мы это исправим :]

Затем дублируем слой с логотипом и преобразуем его в смарт-объект (Convert to smart object) — так мы можем в любой момент корректировать изменения и параметры наложенных фильтров. Для преобразования клацкаем ПКМ по слою и ищем нужный пункт меню.
Далее кликаем два раза ЛКМ по копии слоя и выбираем наложение цвета (Сolor overlay) — заливаем синим. Нужно это для того, чтобы затем добавить хроматические аберрации ЭЛТ-монитора.
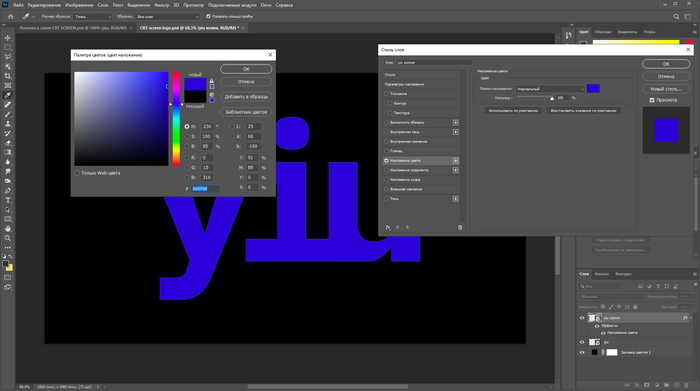
Скопированный слой переносим ниже и нажимаем на стрелки на клавиатуре три раза влево и два вверх. После данной операции в окне эффектов выбираем размытие по Гауссу (Gaussian blur).
Интенсивность эффекта выставляем на 20%, а непрозрачность слоя выбираем 65%.
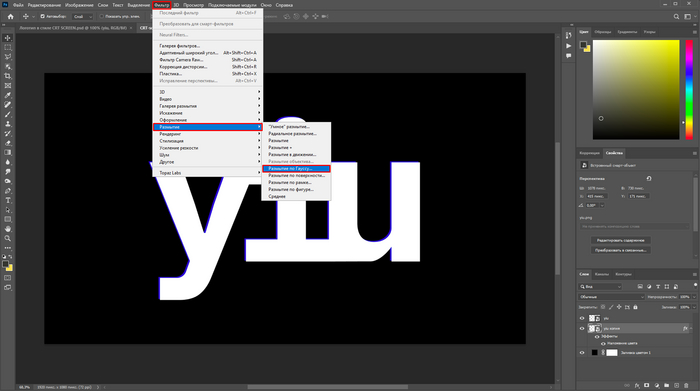
Снова дублируем слой и в наложении цвета выбираем бирюзовый, непрозрачность которого должна стоять на 30%, а радиус размытия на 110%. Получиться должно примерно следующее:

Далее самое интересное — создание пикселей и их наложение по всему кадру. Делать их мы будет вручную, ибо в интернете ни один исходник не подойдет. Что для этого нужно? Ну, во-первых, создать новый файл (11 на 8 пикселей) с прозрачным фоном, а во-вторых, нарисовать эти самые пиксели с помощью фигуры прямоугольник. Файл, думаю, создать без подсказок сможете, а вот про пиксели подробнее расскажу.
На самом деле все просто — пугаться не стоит.
В новом файле мы рисуем прямоугольник (3 на 6 пикселей) с помощью инструмента, собственно, прямоугольник (Rectangle), после чего скругляем углы на 1.5 пункта —это даст нам имитацию тех самых старых пикселей и добавит реализма: будто снято на реальную камеру.
Так вот, созданный прямоугольник со скругленными гранями мы красим в красный, затем дублируем — заливаем зеленым, а потом и синим. Все, мы получили пиксель из трех цветов.
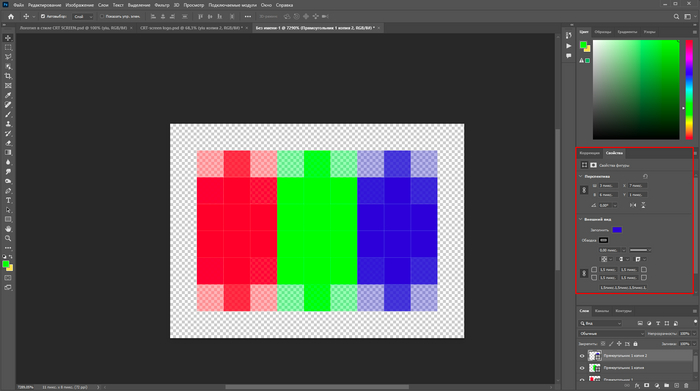
Из прекрасного трехцветного рисунка делам узор, который потом сможем наложить на логотип. Что нужно? Заходим в пункт редактирование (Edit) — определить узор (Define pattern). Называем его, как душе угодно, и возвращаемся к логотипу.
Закрываем страницу с прямоугольниками без сохранения.
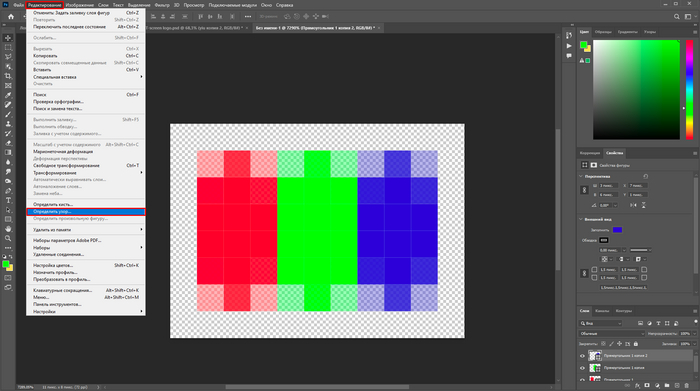
Вернувшись, создаем новый слой, выделяем его, клацаем по разделу редактирование (Edit) — выполнить заливку (Fill). В открывшемся окне ставим параметры, как у меня.
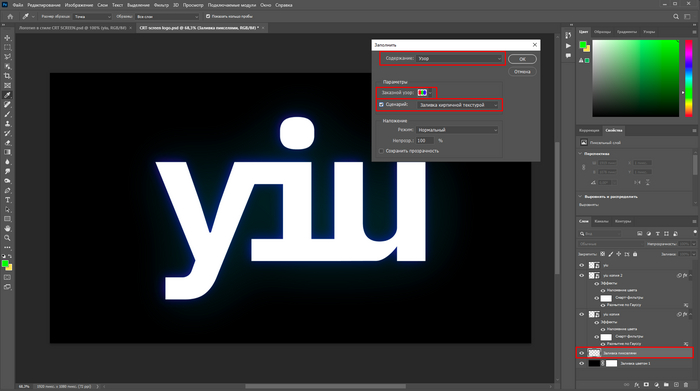
Ниже тоже повторяем за мной. Можете пробовать экспериментировать с масштабом узора до единицы — так структура пикселей будет более проработанная, а картинка перестанет рябить.
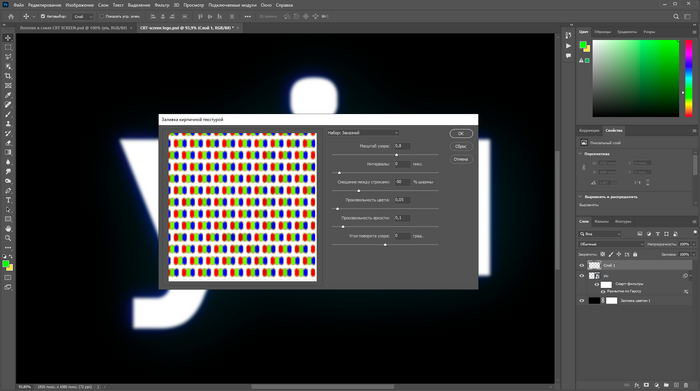
Вот у нас создастся сетка из пикселей под логотипом, но нам ведь не нужна такая каша, правильно? Правильно!
Чтобы кашу расхлебать, мы выделяем три слоя логотипа и преобразуем в смарт объект (smart object). Далее с зажатым CTRL кликаем по слою с пикселями — они должны выделиться — нажимаем на слой с лого и создаем для него маску.
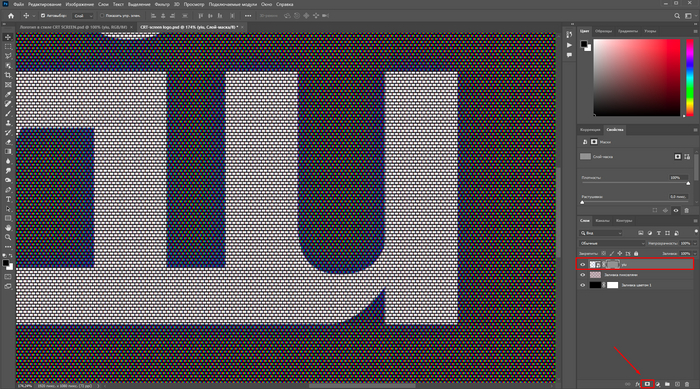
Мы на финишной прямой, не засыпать!
Перемещаем слой с пикселями наверх и наводим курсор между слоями логотипа и RGB, с зажатым ALT смело клацаем ЛКМ — так сетка старинных лампочек будет отображаться только там, где есть логотип.
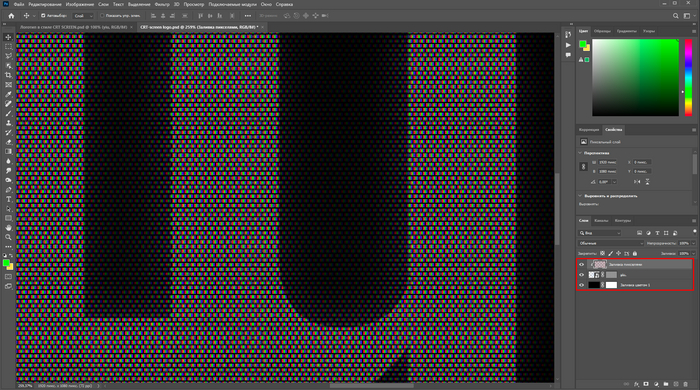
Для лучшего эффекта дублируем слой с сеткой пикселей и перемещаем вниз — ставим непрозрачность на 10%. У старых телевизоров всегда видны пиксели, поэтому важно их отобразить. Не менее важно размыть логотип на 9% по Гауссу — так мы добьемся неравномерности подсветки, прям как у старых телевизоров!
Также непрозрачность верхнего слоя (который прикреплен к логотипу) переводим на 65% — это уберет чрезмерную рябь и добавит читаемости.
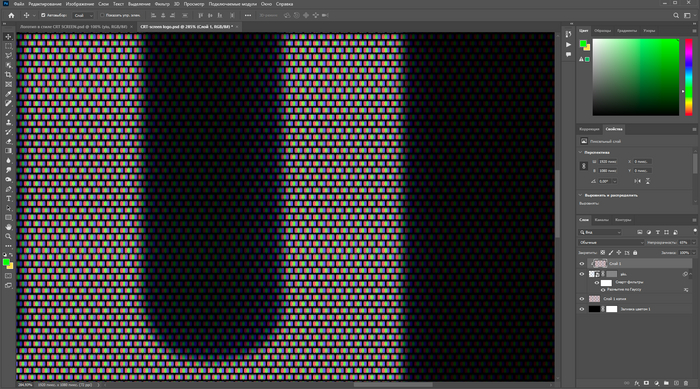
Дополнительно я исказил картинку с помощью (Lens distortion), ибо ЭЛТ-экраны все немного выгнутые. Сочетанием клавиш (CTRL + ALT + SHIFT + E) объединяем слои и заходим в фильтры (Filters) — фильтр Camera raw (Camera RAW filter) — повторяем за мной.

Нет ничего идеального, подумал я, но все же решил кривыми (Curves) прибавить изображению яркости. Выделяем верхний слой и жмем (CTRL + M).
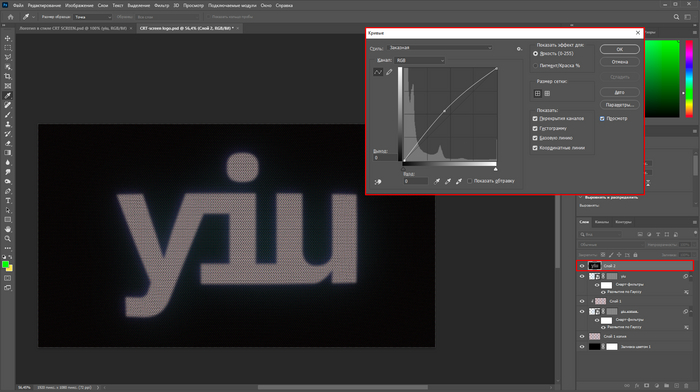
Цель достигнута :3
Кстати, с цветным изображение работает также прекрасно. Единственное, нужно будет выставить режим наложения у сетки пикселей на линейный затемнитель (Darker color).

Congratulations, вы справились!
Теперь кто-то умеет воспроизводить эффект CRT-screen с помощью Photoshop :3
Буду рад обратной связи и вашим комментариям, а также приглашаю в свой телеграм чат, где отвечу на все вопросы касаемо дизайна и генерации изображений с помощью нейросетей.
Буду рад видеть вас в телеграм-канале, где я собираю лучшие гайды по Stable Diffusion. А если не найду, то пишу сам.
Показать полностью
14

Ночные кошмары












Promt:
A matte painting of a scary creature made of smoke and shadow. Chiaroscuro. Highly detailed. Menacing. In the style of Bastien Lecouffe-Deharme, Brooke Shaden, Luis Royo, and Karol Bak.
Negative prompt:
illuminutty_nartfixer illuminutty_nfixer illuminutty_nrealfixer out of frame, clipped, cropped image, bad proportion, double, duplicated, deformed, disfigured, plastic, blurred, bad anatomy, ugly, grainy, low resolution, badly drawn face arms hands legs fingers, mutation, extra limb, missing limb, floating limbs, detached limbs, long neck body, out of focus, text, writing, letters, watermark
Steps: 22, Sampler: Euler a, CFG scale: 3.5, Model hash: Illuminati
Модель можно скачать здесь - https://disk.yandex.ru/d/QhLfH3gCX0uFdQ
Больше артов в группе в контакте - https://vk.com/neurodigitalart
в телеграмме - https://t.me/NeuroDidgitalArt
Всем спасибо за просмотр!!!
Показать полностью
12
Как на самом деле должны выглядеть морские котики


Создано с помощью Stable Diffusion и смешивания запросов [lion:lionfish:15] и т.д. Как это работает подробно писал у себя в ТГ, где обучаю всем этим штукам.
Модель для генерации: Realistic Vision.
Показать полностью
2

Textual inversion — это не то, что ты думаешь

На ютубе задали вопрос в комментариях, решил ответить подробно.
Что ты думаешь про текстовые инверсии? Как их лучше использовать? Вместо моделей или только с ними?
Начнем с конца
У нас есть модель (checkpoint) — это основа без нее ничего работать не будет.
Есть всякие так называемые экстрасети:
гиперсети (hypernetwork)
лоры (всякие LoRA, LoHA, LoCon, LyCORIS)
эмбеддинги (это не сети просто удачно пристроились к остальным)
Нет модели — нет генерации, так что используем только с моделью.
Если вы пользуетесь автоматиком, то эмбеддинги должны лежать в папке папка_с_автоматиком/embeddings.
Что такое текстовая инверсия? Немного теоретической части (без матана и программирования)
Процесс, когда мы учим модель называется тренировка, обучение (train).
В результате этого процесса мы получаем файл с моделью — чекпоинт (checkpoint)
Аналогично, когда мы создаем эмбеддинг этот процесс/метод называется текстовая инверсия (textual inversion), а в результате мы получаем наш файл с эмбеддингом (embedding)
Иногда, когда говорят "текстовая инверсия" подразумевают эмбеддинг, поэтому чтобы нам не путаться дальше я буду писать именно "эмбеддинг" (если вы знаете, что London is the capital of Great Britan, то можете посмотреть этот англоязычный видос в котором подробнее рассказывается что такое эмбеддинги и зачем они нужны; в целом очень крутой канал, если интересно, также можете посмотреть у них плейлист по computer vision и по нейросетям вроде тоже в плейлист собрано)
Эта штука называется текстовой инверсией не просто так. Если обычно (txt2img) мы пишем промпт и получаем картинку, то тут мы даем картинки которые хотим получить и просим модель сказать нам, что это за промпт должен быть, а она нам отвечает нужными цифрами.
Лучше воспринимать эмбеддинги как очень точный промпт и не более.
При этом, "точный" совсем не значит "правильный/красивый", это именно в математическом смысле точный.
Например, вы собрали кучу картинок на которых плохие руки, акцентировали на этом внимание при тренировке эмбеддинга и получили файлик. Если упростить, то этот файлик по сути является точно таким же словом как и другие слова в промпте. Именно поэтому они так мало весят - потому что это набор нужных слов, только напрямую в цифрах. И вместо того чтобы писать в негативном промпте bad hands, extra fingers и т.д. мы пишем наш эмбеддинг, который для нейросети становиться еще одним словом, типа "очень плохие руки, не надо так рисовать" — только заключенное в одном.

При этом эмбеддинг очень сильно привязан к модели (точно также как и обычный промпт), поэтому рекомендую брать и использовать эмбеддинги с теми моделями, на которых они были сделаны. Хотя экспериментировать никто не запрещает, может получиться что-то интересное. Если еще учитывать тот факт, что основой для многих моделей служит всего парочка, так скажем "первоначальных" моделей (типо sd 1.4, 1.5 или слитая от novelai), то использовать одинаковые эмбеддинги между ними может быть вполне ок.
В итоге у нас есть возможность натренировать эмбеддинг на конкретное понятие и с высокой долей вероятности получать хороший результат, в рамках конкретных моделей.
Что я думаю про текстовые инверсии?
Я думаю, что это крутая штука для воспроизведения желаемого результата из раза в раз, вместо плясок с промптом и кучи генераций.
Самое важное
Если вы и должны что-то запомнить из этой статьи, то вот что: Текстовая инверсия не учит модель новому визуалу
Когда мы используем метод текстовой инверсии мы не изменяем модель, мы работает только с текстом. Если то, что вы хотите уже есть в модели, тогда у вас получиться сделать хороший эмбеддинг, иначе — нет.
То есть если модель умеет рисовать только гаечный ключ, цветочный горшок и черепашку (не ниндзя, обычную), то сделав эмбеддинг со своим лицом для такой модели у вас ничего не получиться, потому что модель не умеет рисовать лица людей. Она может знает слово "лицо", типа "лицо черепашки", но лицо человека она не видела и нарисовать не сможет.
Тут можно возразить, что допустим есть модель которая видела кучу людей, разве она не сможет собрав все свои знания о тысячах лиц нарисовать мое?
Во-первых, не встречав до этого такой красоты как ваша, ее не сможет повторить никакая нейросеть *подмигнул*
Во-вторых, тут противоборство двух сторон: нашей нейросети в башке, которая десятки тысяч лет училась считывать лица и та, которая существует пару лет. Мы с вами очень хорошо чувствуем в людях отклонение от чего-то нормального (хотя и нас можно обмануть), поэтому существует такое явление как зловещая долина (uncanny valley) и так как текстовая инверсия не учит модель новому визуалу, модель будет пытаться нарисовать не вас (потому что не знает как выглядите именно вы), а что-то похожее на вас. Тут сильно от модели и вашей внешности зависит, может получиться удачно, может нет. Я рекомендую не тратить на это время и сразу учить ту же LoRA — с нормальными настройками результат будет сильно лучше, а времени потратите +- столько же.
Эмбеддинги это отличная штука, чтобы получить желаемую картинку. Какой-нибудь стиль, предмет или даже персонажа (эмоции, позы, одежду и тд), которого модель уже умеет рисовать.
Честно, хз почему была такая мода учить все подряд через textual inversion.
У koiboi есть хороший видос про разные методы тренировки, на который многие ссылаются и в нем он говорит, что текстовая инверсия учит новому концепту, но скорее всего его не совсем правильно поняли + до этого у него выходило видео только про текстовую инверсию в котором он в том числе упомянул, что она работает только с тем, что уже есть в модели.
Да и вообще, берете бумагу, открываете и в ней во вступлении, английским по белому написано:

Используя всего 3-5 изображений предоставленного пользователем понятия, например, предмета или стиля, мы учимся представлять его с помощью новых "слов" в пространстве эмбеддингов замороженной (неизменяемой) модели text-to-image. Эти "слова" могут быть составлены в предложения на естественном языке, интуитивно понятным образом направляя процесс создания персонализированных творений. (сорян, как получилось, так и перевел)
Поэтому если вы используете текстовую инверсию чтобы научить модель чему-то новому — остановитесь

На этом у меня все, надеюсь помог лучше понять что такое textual inversion. У меня есть телеграм, так что если хотите можете подписаться: https://t.me/mrreplicart и на ютуб периодически видосы заливаю https://www.youtube.com/@mrreplicart
Тем еще очень много, так что если есть предложения/вопросы - пишите, постараюсь разобрать. Как пример, иногда встречаю, как люди пишут/говорят, что "выключил VAE", "сгенерировал без VAE" или что "VAE — постобработка" и она "улучшает изображение".

Показать полностью
4
Весна...








Prompt:
mountains, (fairy tale forest:1.2), magic, druidic portal with wrapping vines, (flowers:1.2) lake, Photorealistic, Hyperrealistic, Hyperdetailed, analog style, soft lighting, subsurface scattering, realistic, heavy shadow, masterpiece, best quality, ultra realistic, 8k, golden ratio, Intricate, High Detail, film photography, soft focus,
Negative prompt:
Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers
Steps: 30, Sampler: Euler a, CFG scale: 9, Seed: 3620151515, Size: 1024x1024, Model: Colorful v27
Скачать модель можно тут:
Больше артов в группе в контакте - https://vk.com/neurodigitalart
в телеграмме - https://t.me/NeuroDidgitalArt
Всем спасибо за просмотр!!!
Показать полностью
8
Сеть










Prompt:
(a portrait_1.5) of a beautiful cybernetic woman meditating, wires and cables, cyberpunk concept art by josan gonzales and enki
Negative prompt:
illuminutty_nartfixer illuminutty_nfixer illuminutty_nrealfixer out of frame, clipped, cropped image, bad proportion, double, duplicated, deformed, disfigured, plastic, blurred, bad anatomy, ugly, grainy, low resolution, badly drawn face arms hands legs fingers, mutation, extra limb, missing limb, floating limbs, detached limbs, long neck body, out of focus, text, writing, letters, watermark
Steps: 22, Sampler: Euler a, CFG scale: 3.5, Size: 1024x1024, Model illuminutty, Clipskip: 2
Модель можно скачать здесь - https://disk.yandex.ru/d/QhLfH3gCX0uFdQ
Больше артов в группе в контакте - https://vk.com/neurodigitalart
в телеграмме - https://t.me/NeuroDidgitalArt
Показать полностью
10

Невеста-зомби

Показать полностью
1