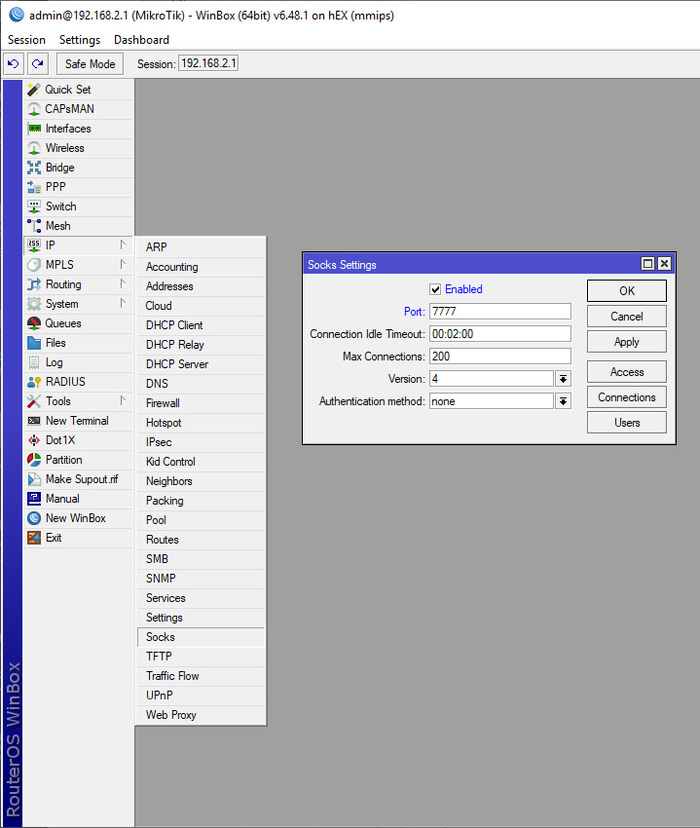
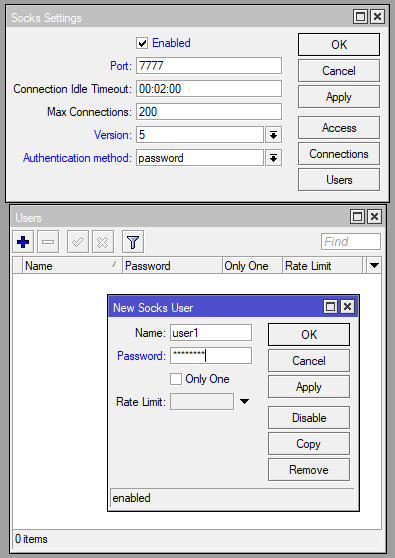
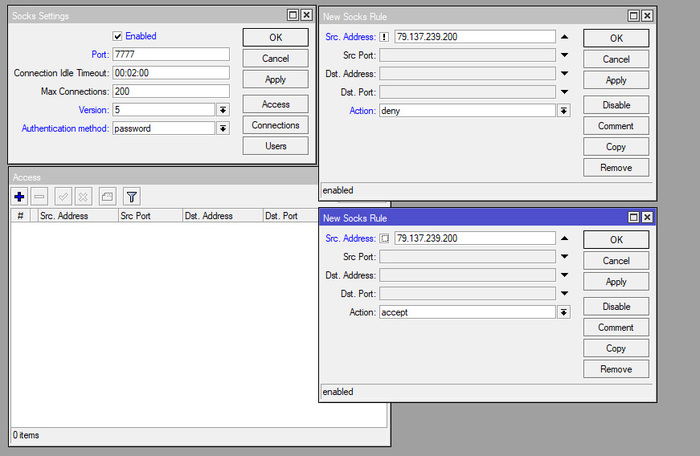
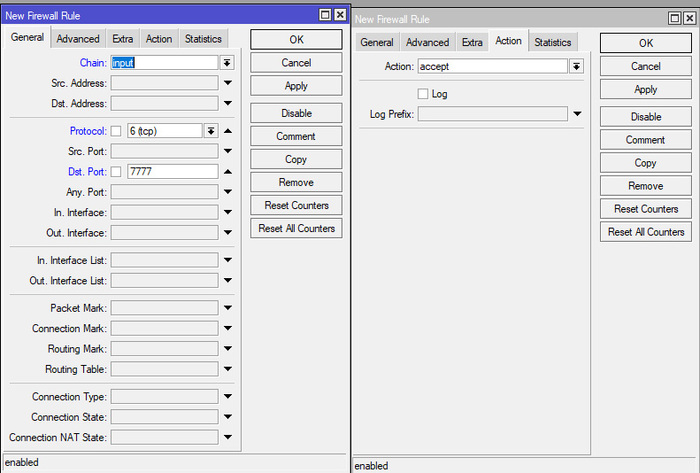
Впечатлившись рекламой и хвалебными отзывами руководство одной из контор, в которых мне довелось сисадминить, приняло решение о внедрении модного Kerio Control. Сказано – сделано: мечта об удаленном рабочем столе претворилась в жизнь, а трудовые будни окрасились в неожиданно привлекательные тона. Теперь начальство могло преспокойно работать из дома, попивая кофе в трусах.
Беда, как это обычно бывает, пришла, откуда не ждали. Поскольку о таком понятии как VPN ребята слыхом не слыхивали, а о его назначении – и подавно, то, недолго думая, открыли порт удаленного рабочего стола для доступа из любой точки недружелюбного внешнего мира. И, конечно же, при этом пароль администратора на сервере был «12345», его никто не удосужился поменять, да и вряд ли кто об этом задумывался.
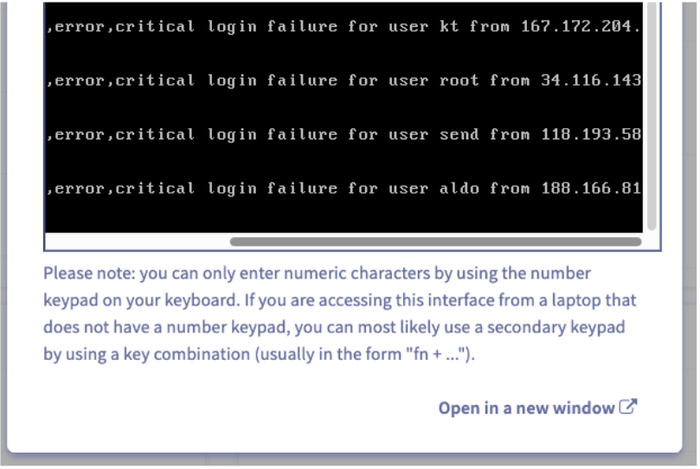
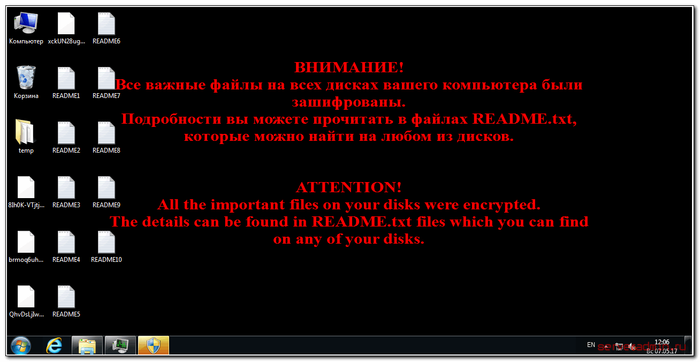
Всего через пару недель счастливой и безоблачной работы из дома на сервере появилась зловещая картинка.
Работа конторы оказалась парализована, со стороны это всё выглядело следующим образом: все опрошенные старательно отрицают переход по небезопасным ссылкам нигерийских принцев, руководящий состав мечет громы и молнии, часть рядовых сотрудников радуется возможности похалявить, проектный отдел рвёт на себе волосы, логисты нервничают, кадровики хранят отстраненное молчание, и только снабженцы с трудом скрывают довольные ухмылки. Стало очевидно, что без привлечения квалифицированного специалиста дальнейшее функционирование не представляется возможным. Тогда-то меня и вызвали, чтобы поставить извечный русский вопрос: «Что делать и кто виноват?».
Послание от злоумышленников, как можно было легко догадаться, содержало требование выкупа в обмен на обещание расшифровки файлов. По тем временам, учитывая актуальный на тот момент курс биткоина, сумма запрошенного выкупа – 0,5 биткоина – выходила в сущие копейки и составляла всего-то 500 килорублей.
На кону была не только дальнейшая работа компании, клиентская база и многолетние наработки, но и пресловутая коммерческая тайна. Казалось бы – что такое полмиллиона для преуспевающей столичной конторы с приличным годовым оборотом?
Однако директор был категоричен и непреклонен, заявив, что не намерен вести никаких переговоров с вымогателями, а восстановление предполагается вести в ручном режиме. «Мне бы только файлик с «черной» бухгалтерией восстановить» - понизив голос, добавил директор и вкрадчиво присовокупил обещание «в долгу не остаться».
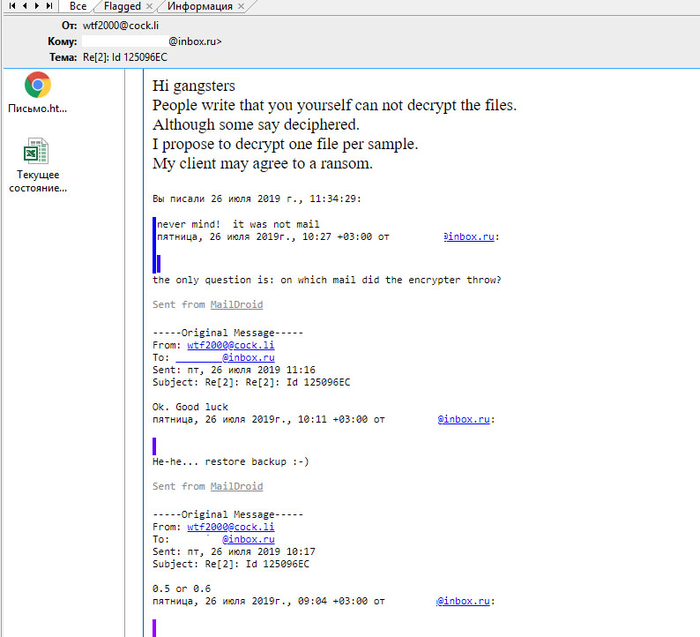
От успеха или неудачи в данной ситуации напрямую зависела моя репутация и дальнейшее сотрудничество с компанией, не скупящейся на оплату моих трудочасов. Вариантов у меня было немного. Здраво рассудив, что за спрос денег не берут, решил закинуть удочку злодеям. Написал, мол, деньги не проблема, однако, имеются сомнения в оправданности трат – хорошо бы продемонстрировать способность к расшифровке, вот, хотя бы на этом «совершенно рандомном» файле.
Вымогатели радостно заглотили мою наживку и прислали заветный файл в дешифрованном виде. Окончательное спасение ситуации пришло от главбуха – оказалось, что она со своей профессиональной паранойей регулярно делала резервное копирование. Миссия моя была близка к успешному завершению – всего-то за квартал документов пришлось восстанавливать.
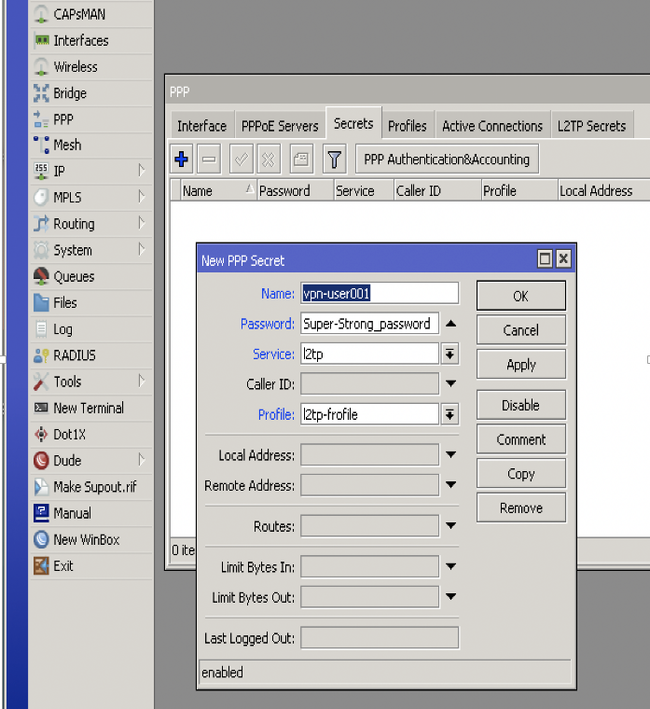
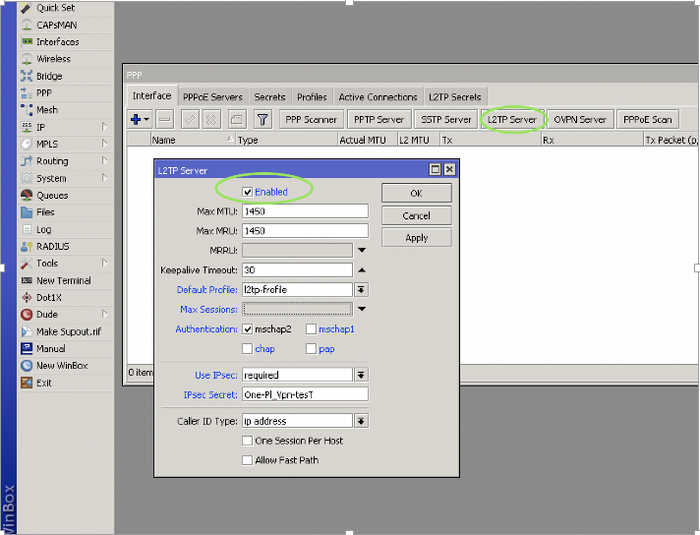
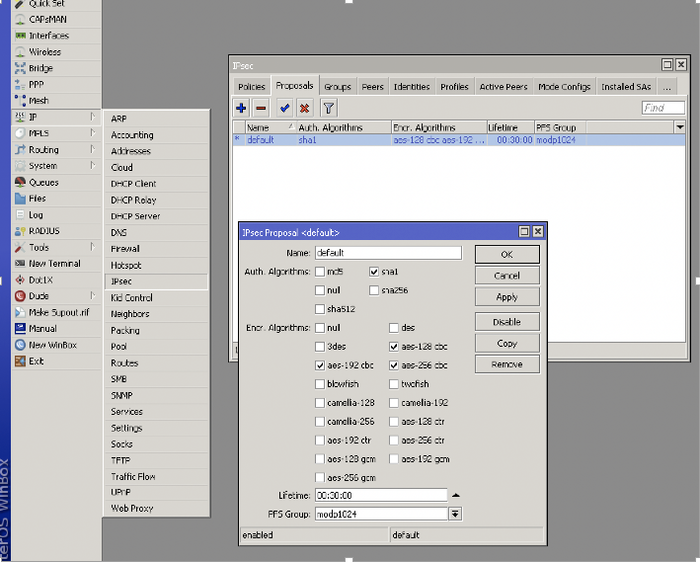
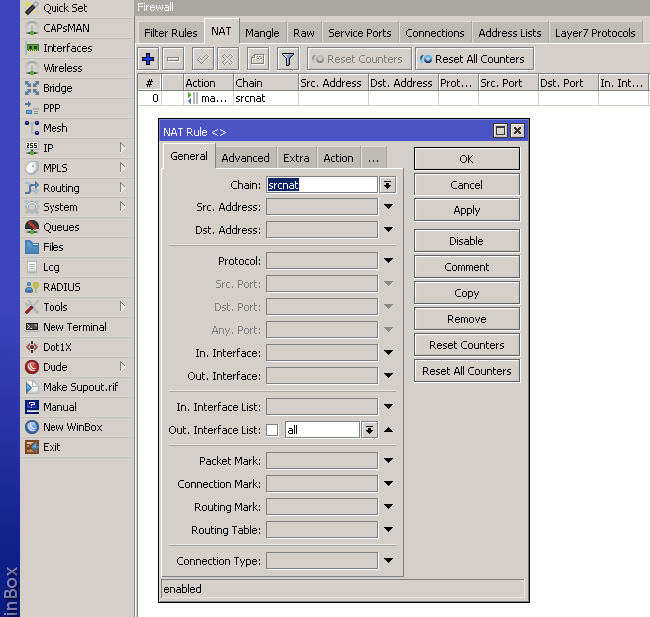
А ведь всего этого можно было избежать, если бы VPN вовремя настроили, порты открывали с умом и использовали сложные пароли.
P.S. Прикладываю скрин переписки с злодеями, дабы развеять все сомнения в кото-ламповости истории. В нем видно, что файл они прислали.