PG_HAZEL : Влияние увеличения commit_delay на производительность СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Практика - критерий истины.
Задача
Экспериментальная проверка материалов доклада "Особенности записи WAL" PGConf.СПб 2025
Евгений Александров Т-Банк Старший инженер
Исследование механизма записи WAL в PostgreSQL с акцентом влияния на дисковую систему при высокой OLTP нагрузке. В докладе рассматриваются инструменты диагностики и даются рекомендации по настройке параметров, влияющих на поведение записи WAL.
Конфигурация тестовой ВМ
CPU = 8
RAM = 8GB
OS: RED OS MUROM (7.3.4)
PostgreSQL :
Postgres Pro (enterprise certified) 17.5.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20230605 (Red Soft 11.4.0-1), 64-bit
Эксперимент-1
commit_delay = 0
Эксперимент-2
commit_delay = 1000
Сценарий тестирования и нагрузка на СУБД
Mix
Select only : 50% нагрузки
Select + Update : 30% нагрузки
Insert only : 15% нагрузки
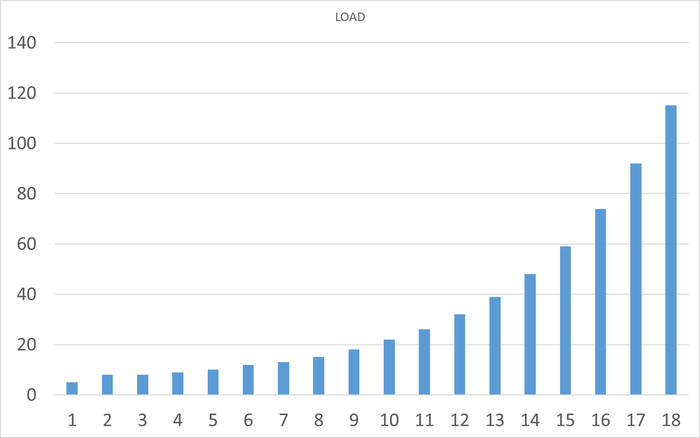
Нагрузка
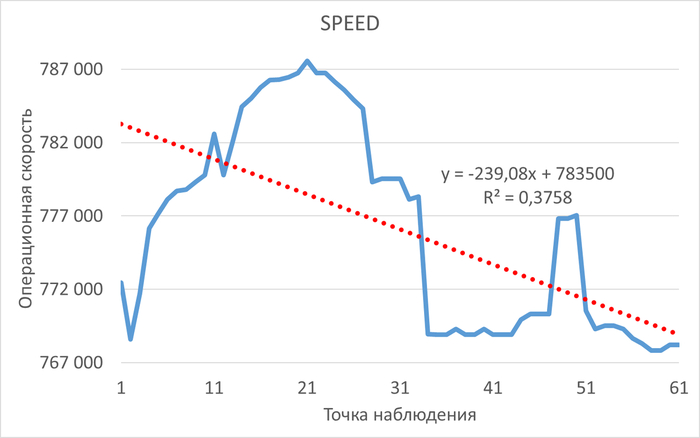
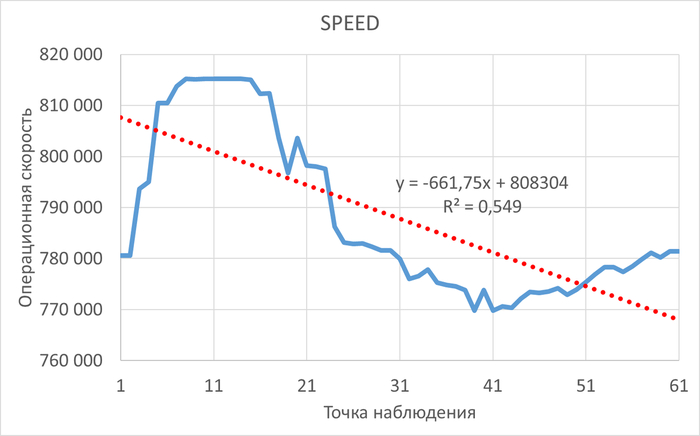
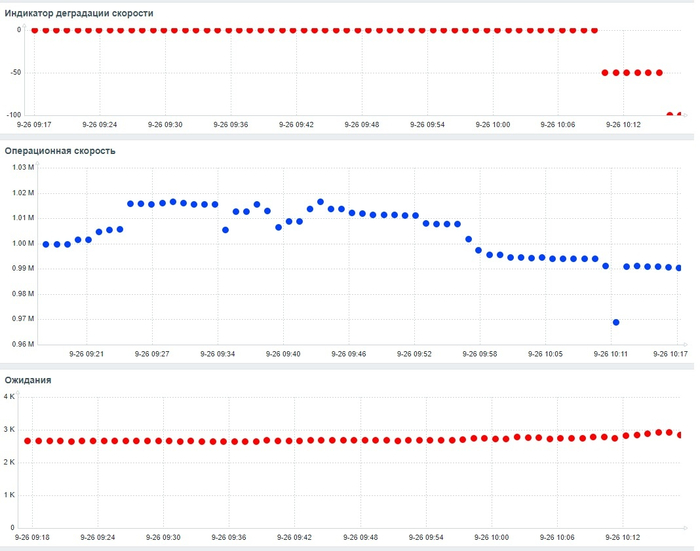
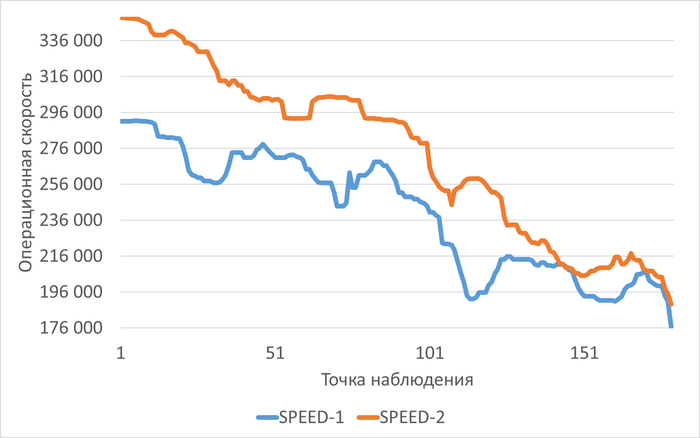
Операционная скорость
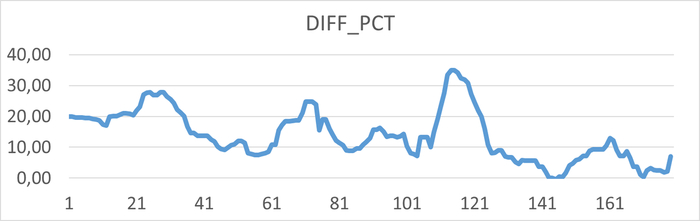
Относительная разница операционной скорости в эксперименте-2 по сравнению с экспериментом-1
Результаты
Среднее увеличение операционной скорости в эксперименте-2 составило 13.82%
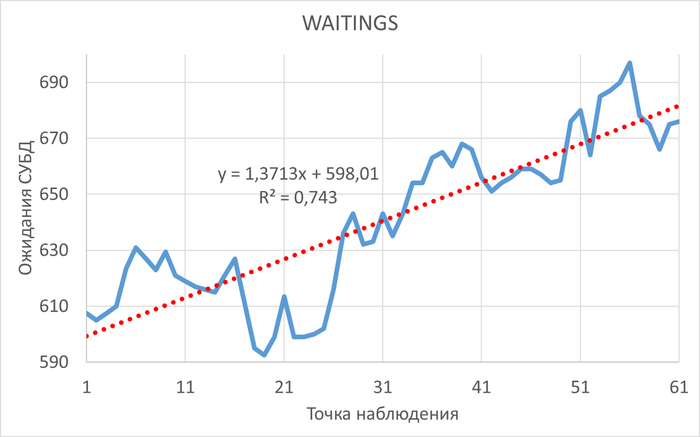
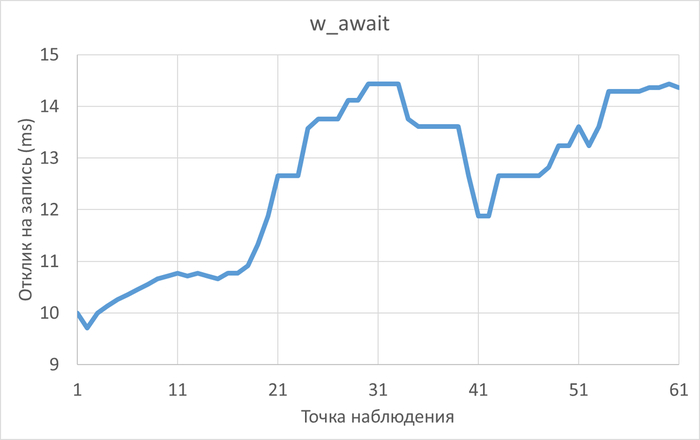
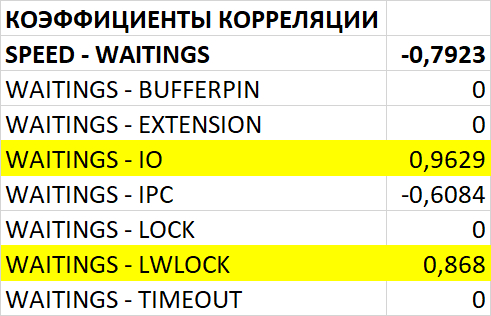
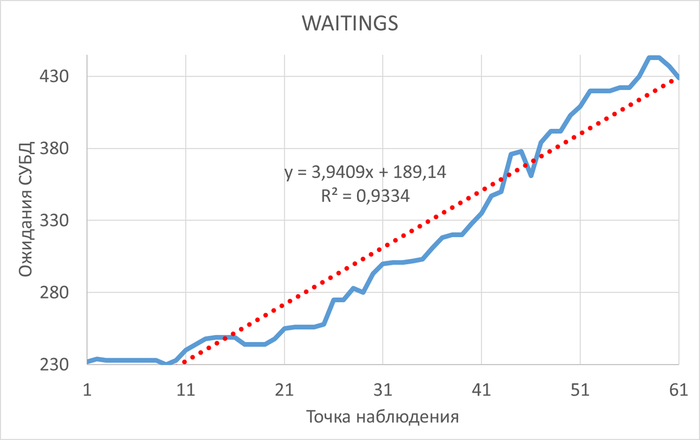
Ожидания СУБД
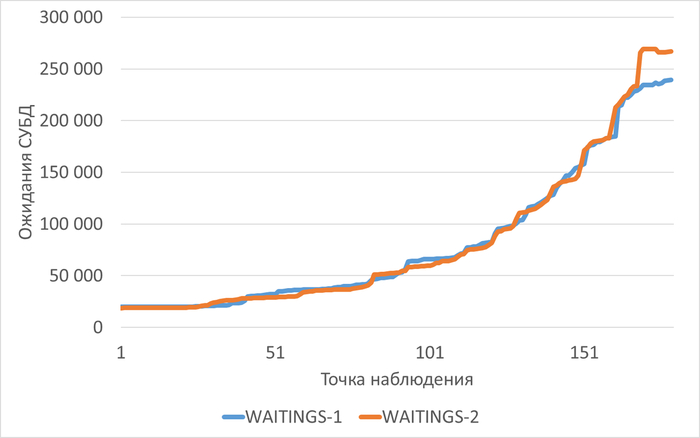
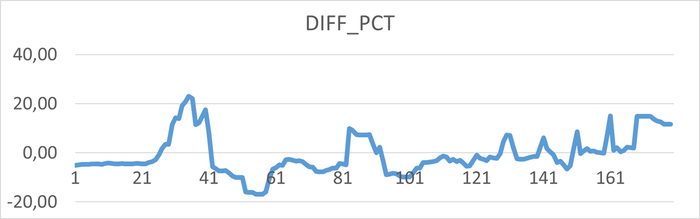
Относительная разница ожиданий в эксперименте-2 по сравнению с экспериментом-1.
Результаты
Среднее уменьшение ожиданий в эксперименте-2 составило ~1%
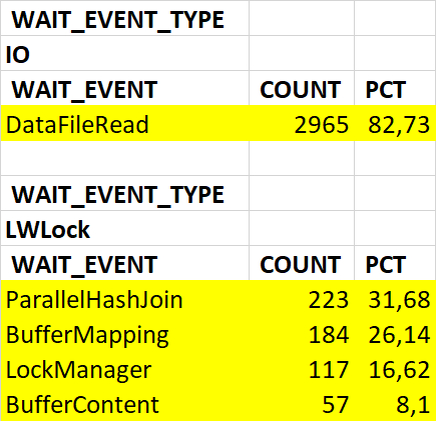
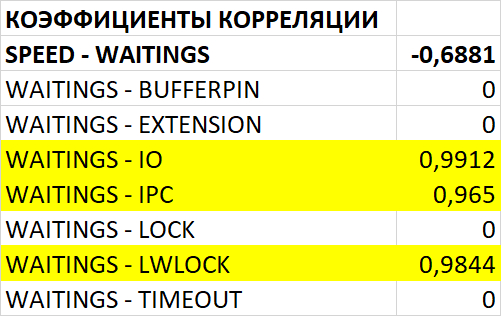
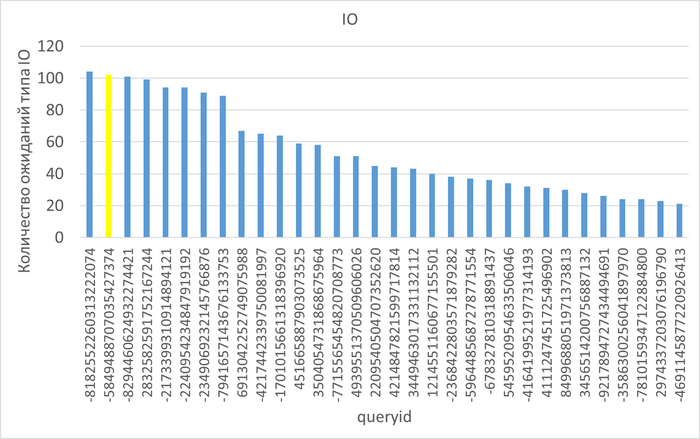
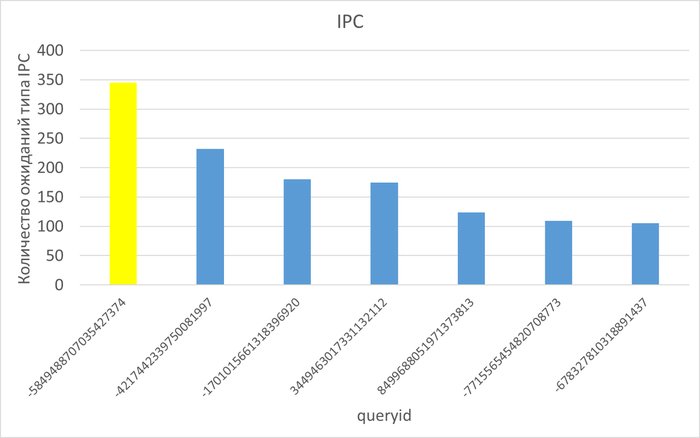
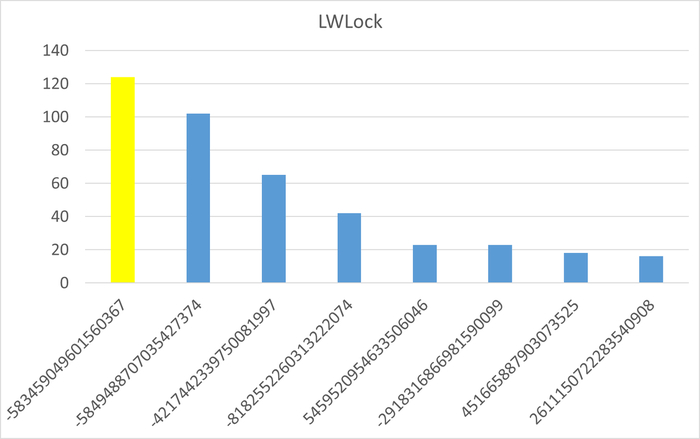
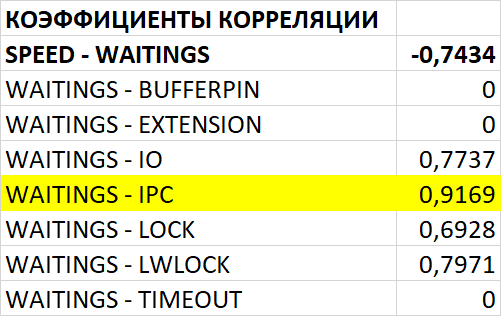
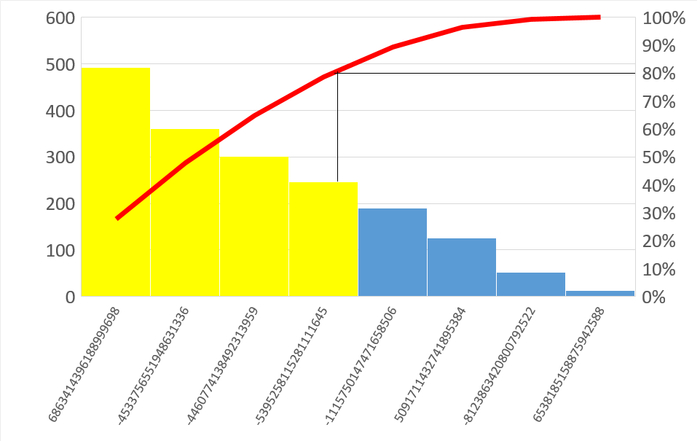
События ожидания (диаграмма Парето:80%)
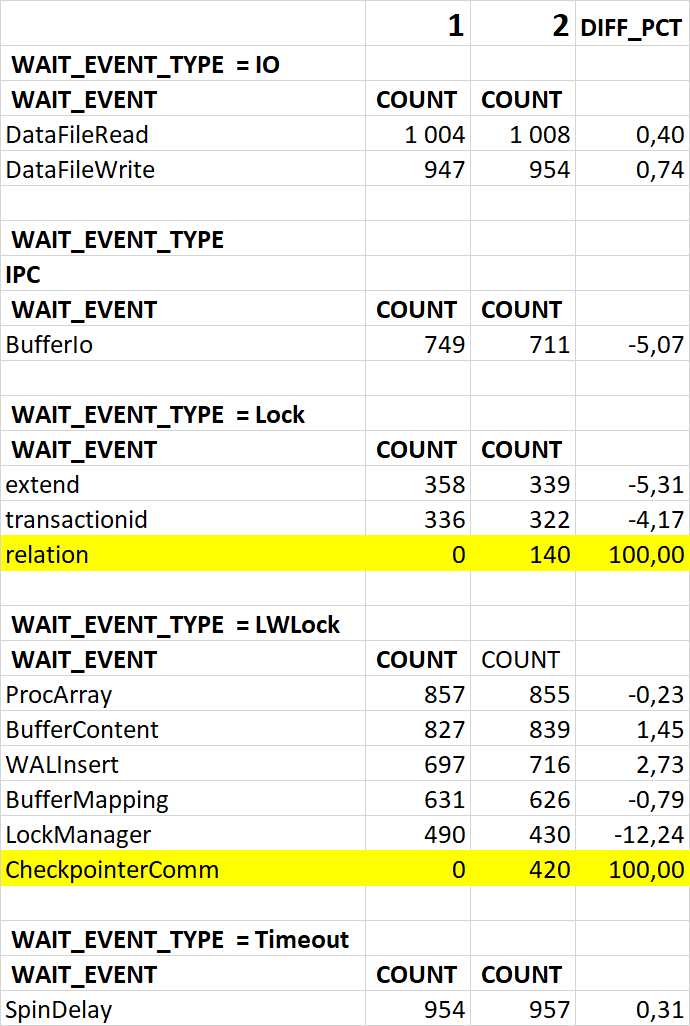
Результат
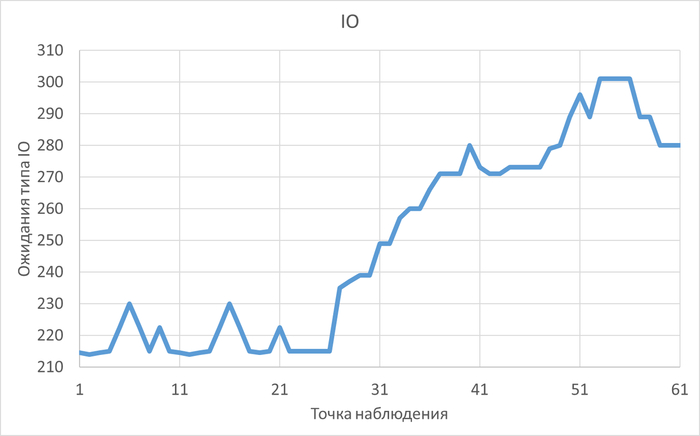
Доля ожиданий Lock/relation в эксперименте-2 кардинально увеличилась.
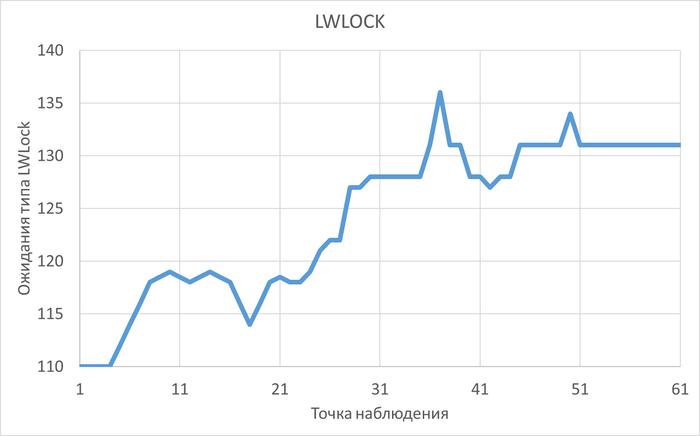
Доля ожиданий LWLock/CheckpointerComm в эксперименте-2 кардинально увеличилась.
Показатели производительности инфраструктуры
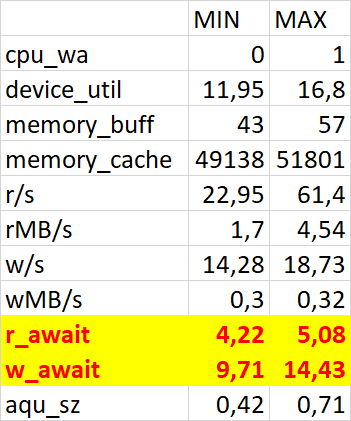
iostat - для файловой системы /data
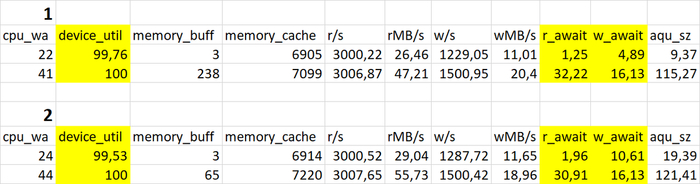
iostat - для файловой системы /wal
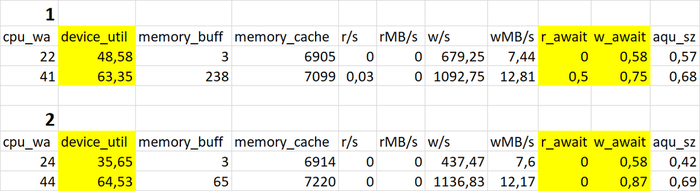
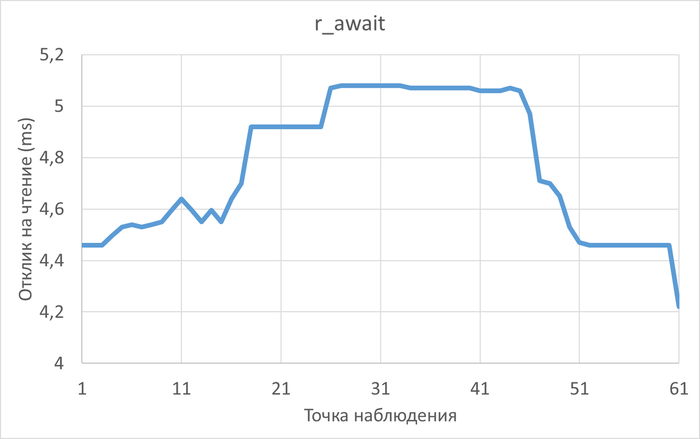
Утилизация диска файловой системы /wal
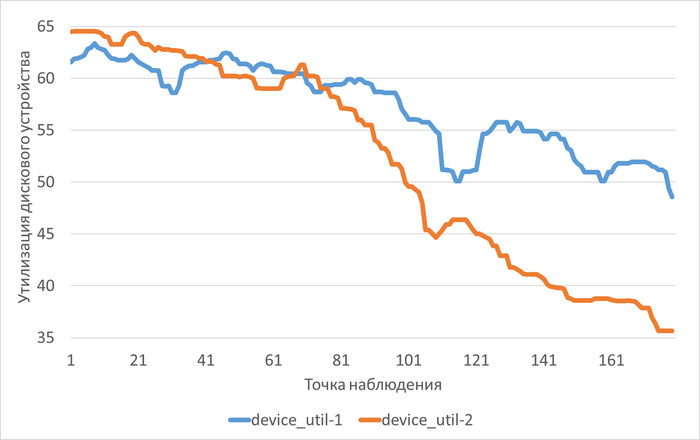
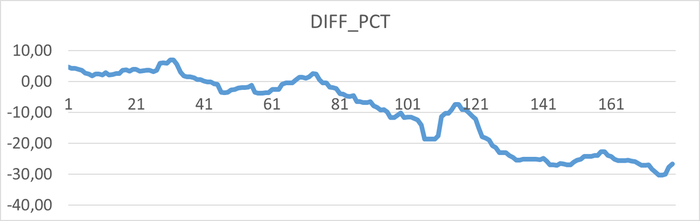
Относительная разница утилизации в эксперименте-2 по сравнению с экспериментом-1.
Результаты
Среднее уменьшение утилизации дискового устройства для файловой системы /wal в эксперименте-2 составило ~10%
Чек-лист CPU

Самый главный результат эксперимента
⚠️Рекомендация DeepSeek экспериментально не подтвердилась⚠️
-------------------------------------------------------------------------------------
commit_delay
Для конфигурации PostgreSQL 8 CPU, 8 GB RAM с shared_buffers=2GB под нагрузкой pgbench (5→100 соединений) оптимальное значение commit_delay = 0 (по умолчанию) является наиболее эффективным. Обоснование:
⚠️ Почему НЕ рекомендуется изменять commit_delay?
Природа pgbench нагрузки:
TPC-B-like транзакции выполняются за 1-5 мс. Любая задержка коммита (commit_delay > 0) увеличивает latency на 20-100% .
При 100 соединениях группировка коммитов не даёт выигрыша: короткие транзакции редко совпадают во времени .