Какие насущные рутинные (и не только) вопросы я хотел решить с максимально возможной автоматизацией:
1. Создание обучающего материала для вновь прибывшего сотрудника
2. Анализ текстовых данных (тут вопросы были разные и останавливаться подробно не буду. Возможно, это будет отдельная статья)
3. Генерация презентаций
4. Генерация визуального материала для сайта, каталога и прочего
5. И самое насущное СОЗДАНИЕ КАРТОЧЕК ДЛЯ МАРКЕТПЛЕЙСОВ
Под эти задачи было разработано несколько мини инструментов:
Генерация Текста и Документов (он же анализ)
Создание простого текста (или кода)
Создание презентации (PPTX)
Генерация Изображений (с помощью разных моделей nano banana, nano banana pro, imagen4)
Генерация карточек (nano banana pro)
Далее постараюсь подробнее описать, что и как.
Текстовая фабрика ("Создание простого текста")
Оговорюсь, "простой текст" в данном случае - это все, что можно выразить буквами, цифрами и символами. Это может быть и продающая статья, и техническая документация, и даже программный код.
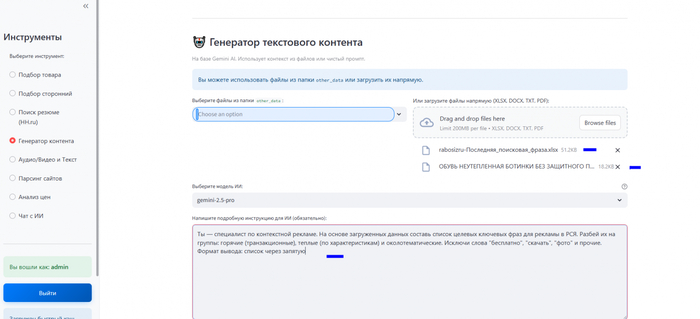
Все началось с простого. У нас тонны PDF-файлов с ГОСТами, DOCX-инструкции от поставщиков и гигантские Excel-таблицы. Это контент, который невозможно читать, но который нужно превратить в продающие описания, статьи для блога, посты для соцсетей, а также в унифицированные обучающие материалы. Собственно, обучающие материалы и дали толчок для внедрения отдельных типов функций (генерация контента) в мой инструмент.
В один прекрасный момент руководитель компании попросил исследовать возможность создания обучающего материала на основе собственного накопившегося материала и по нашей специфике.
Что может быть интереснее структурирования материала и создания полезного из груды «мусора»?! Да, буквально всё (шучу, перерабатывать и структурировать мне очень нравится).
Назрел небольшой план. Сам себе задал вопросы: «Какой материал нужен был бы мне?», «Как его лучше запоминать?», «Как сделать точки среза?» и прочих подводящих вопросов для выработки стратегии этого материала и соответственно стратегии его создания. Углубляться в саму генерацию не буду, вкратце:
1. Есть материал по специфике (в разных форматах)
2. Есть правильный промпт
3. Есть результат (результат получил в html файлах с тестированием и сохранением результатов)
Первая разработка текстовой генерации:
Первым делом я окинул взглядом "сырье" для будущей базы знаний. Это был структурированный материал из 1С и хаос накопившихся файлов (ГОСТы в PDF, DOCX-файлы от поставщиков с безумным форматированием и вставленными объектами; гигантские Excel-таблицы с характеристиками товаров и прочее).
Я пошел за помощью все также к гемини. ИИ, будучи послушным исполнителем, предложил мне целый "зоопарк" библиотек: PyPDF2 для PDF, python-docx для Word, openpyxl для Excel. И тут я впервые по-настоящему столкнулся с суровой реальностью:
PDF - это был персональный ад. Первые же попытки прочитать наши ГОСТы выдавали либо пустую строку, либо абракадабру. Кириллица превращалась в "кракозябры", текст из таблиц слипался в одну нечитаемую строку, а колонтитулы и номера страниц нагло лезли в основной контент, ломая всю логику. DOCX и XLSX были дружелюбнее, но тоже со своими причудами: скрытые символы, объединенные ячейки, которые ломали парсинг...
Моя реакция была типичной для "вайбкодера": я не стал читать документацию. Я скопировал кусок "мусорного" текста, который выдавала программа, в чат с Gemini и написал что-то типа: "Смотри, что оно мне выдает! Я не понимаю в этих ваших 'регулярных выражениях', но ты, я уверен, спец. Напиши функцию «санитара» для Python, которая будет вычищать из подобного текста весь мусор: переносы строк посреди слова, номера страниц, колонтитулы и прочую ересь".
Так в моем коде появилась функция clean_text, о существовании которой я и не подозревал. Она стала первым и важнейшим этапом обработки любого файла.
Дальше были работы с промптами и с моделями, тестирование, «допиливание» и так в небольшом цикле. Выбор "мозгов": Для этой задачи я однозначно выделил модель gemini-2.5-pro. Почему? Потому что для работы с большими, сложными документами и многоступенчатыми инструкциями нужен "тяжеловес". У этой модели огромное контекстное окно (она "помнит" очень много текста) и она достаточно хорошо следует строгим указаниям, не "додумывая" факты и минимально галлюцинирует. Flash-модели быстрее, но здесь была важна именно въедливость и точность.
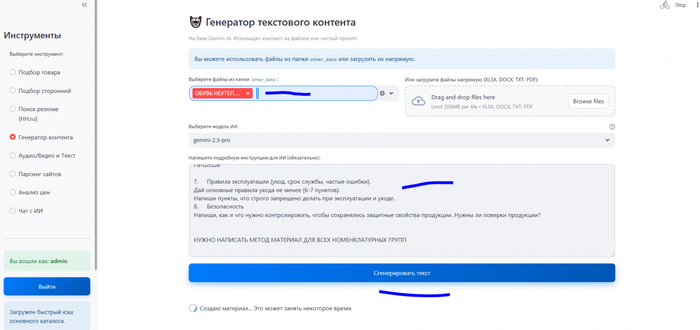
На скрине я выделил файл с данными, промпт. Далее я получил выходной материал в html, который осталось скопировать в блокнот и сохранить
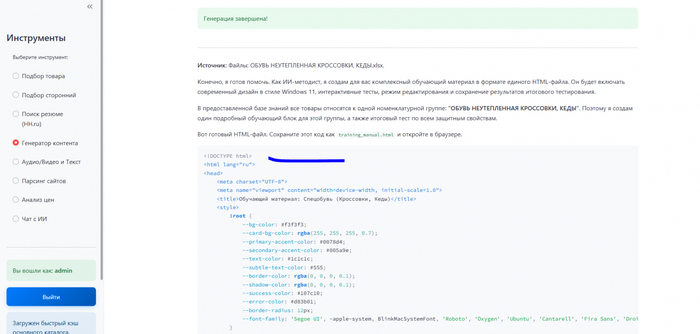
И вот он, финальный штрих, о котором я упомянул - "результат в html файлах". Это была победа. Я заставил ИИ писать мне интерактивные веб-страницы с нужным мне результатом. Я подготовил обучающие уроки по всем нужным категориям товаров, которые подходили для новичков и которые фиксировали прохождение уроков (тестирование) путем тестирования после каждой категории. Вот пример (часть обучающего материала и тестирования):
Теперь процесс создания одного учебного модуля выглядит так: я беру папку с документами по теме, скармливаю их инструменту, пишу один главный промпт, и на выходе получаю HTML код, сохраняю его, отдаю на проверку эксперту и заливаю на внутренний портал . Мечта, а не работа.
Сценарии работы с данным инструментом может быть огромное количество, тут все зависит от фантазии и необходимости.
Генератор презентаций: от идеи до готового PPTX-файла
После того как я наладил процесс генерации текстов, я обратил внимание на следующую рутинную задачу, отнимающую много времени - создание презентаций. Этот процесс требует не только сбора и написания контента, но и его структурирования, форматирования и подбора визуальных материалов. Моей целью было создать инструмент, который бы брал на себя основную часть этой работы, позволяя на выходе получить готовый .pptx файл, требующий лишь минимальных правок в павер поинте.
Первоначальная мысль просто поручить ИИ писать текст для каждого слайда по отдельности была отброшена. Такой подход не решал главной проблемы - автоматизации верстки. Нужно было найти способ передать ИИ не только задачу написать текст, но и задачу спроектировать саму структуру презентации. Решение нашлось в двухступенчатом подходе, который я разработал совместно с Gemini.
Ступень 1: ИИ-планировщик
Ключевым стало изменение роли для ИИ. Вместо того чтобы быть просто копирайтером, модель стала выполнять функцию проектировщика. По моему запросу она генерирует не сплошной текст, а структурированный план. Этот план служит детальным техническим заданием для каждого будущего слайда и включает в себя:
title: Заголовок слайда.
content: Ключевые тезисы в виде списка.
image_prompt: Детальный промпт на английском языке для нейросети, которая сгенерирует подходящее изображение.
Ступень 2: Python-сборщик
Когда план готов, в дело вступает скрипт на Python, использующий библиотеку python-pptx. Он выполняет чисто механическую работу:
Читает созданный на первом этапе план.
Создает пустую презентацию в формате 16:9.
Для каждого элемента в плане последовательно создает новый слайд, добавляя на него текстовые поля с заголовком и тезисами.
Отправляет промпт для картинки в API для генерации изображений, получает результат и размещает его на слайде.
В процессе разработки я столкнулся с ожидаемой проблемой: на первых сгенерированных слайдах текст налезал на изображения, а заголовки выходили за границы. Библиотека python-pptx использует свои единицы измерения, и вместо изучения документации я применил практический подход. Я потратил достаточно много времени на подбор нужных координат и размеров для всех элементов, многократно перезапуская скрипт с разными значениями, пока не добился приемлемого вида.
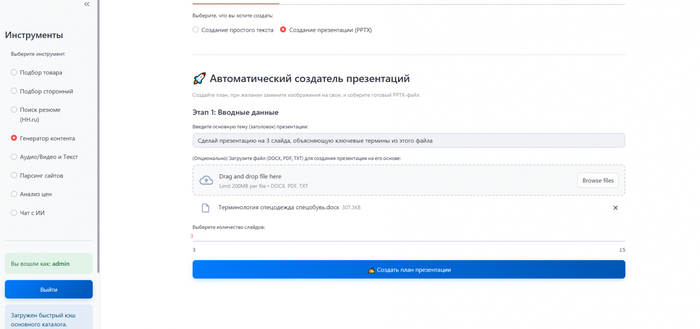
В примере я взял реальную задачу: создать обучающую презентацию по теме «терминология спецодежды». У меня был файл с определениями и описаниями. Я загрузил этот документ в инструмент и дал простую команду: «Сделай презентацию на 3 слайда, объясняющую ключевые термины из этого файла».
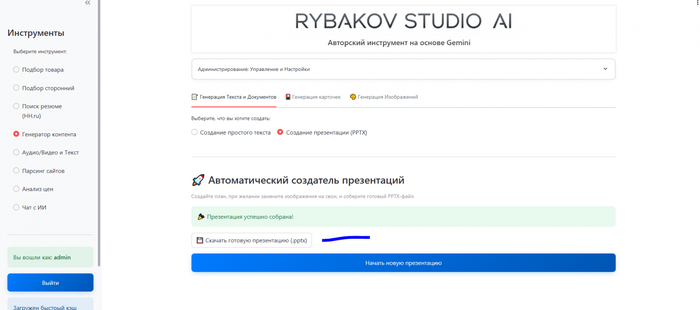
Через минуту система выдала готовый .pptx файл. В нем был титульный слайд, 2 контентных слайда, каждый из которых был посвящен отдельной группе терминов, и заключительный слайд. Тезисы были взяты из моего документа, а изображения - сгенерированы ИИ на основе контекста.
Самое главное - сразу можно открыть этот файл в PowerPoint и начать его редактировать при желании. Основная часть механической работы была сделана за меня.
P.S.: даже здесь гугл не смог отойти от инклюзивности ))) для примера оставлю, как есть
Использовать данный инструмент можно где угодно, например: Создание презентаций о новых продуктах на основе технической документации, подготовка внутренних отчетов по итогам месяца на базе аналитических записок, генерация обучающих материалов для новых сотрудников, быстрое создание визуальных саммари по статьям или длинным документам. Но здесь вы ограничены только вашей фантазией и производственной необходимостью.
Генерация изображений с помощью Nano Banana и не только
Изначально генерацию изображений я сделал исключительно «для себя». Не совсем понимал, что вообще можно с этим делать, но это была модель Imagen. Как только в сети хайпанула первая реинкарнация нано банана, пришли мысли о возможной практической пользе. У нас в компании есть магазин неликвида, который получает своих клиентов в основном с Авито. И тут сразу пришло на ум, что нейрофотошоп в виде нано бананы как раз то, что нужно для работы с карточкой товара. Я приведу пример того, что я делал с его помощью.
Проблема нашего "Авито-магазина" была до боли знакомой. На складе лежат абсолютно новые, качественные товары, но в старых, помятых коробках, покрытых слоем складской пыли. Сфотографировать это "как есть" - значит сразу отпугнуть покупателя. Нанимать фотографа для каждой позиции - экономически нецелесообразно.
И вот тут концепция "нейрофотошопа" заиграла новыми красками. Я взял фото старого, но абсолютно нового респиратора в помятой коробке, загрузил его в свой инструмент и дал модели простую задачу: "Вырежи респиратор из этой картинки и помести его на фон чистого, светлого склада. Добавь реалистичные тени".
Результат был огонь. Модель не просто вырезала объект, она "поняла" его форму и органично вписала в новое окружение. То, на что у дизайнера ушло бы 15-20 минут в Photoshop, ИИ сделал за 30 секунд. Я понял, что нащупал золотую жилу, и начал формализовывать этот процесс, встраивая его в свой основной инструмент.
Как это работает под капотом:
Я реализовал трехрежимный интерфейс. Пользователь может выбрать, какая модель ему нужна прямо сейчас, в зависимости от задачи:
Imagen – дешево и сердито
Первой моделью, которую я подключил, была Imagen. Это инструмент, который хорошо справляется с созданием изображений по четкому текстовому описанию. Его главная особенность - необходимость «говорить с ним на его языке». Чтобы получить качественный результат, нужно было разделять запрос на две части (а также к промптам пришлось прикрутить автоматический перевод на буржуйский)
Промпт: Основное описание того, что должно быть на картинке (например, «защитный костюм на манекене»). Этот текст я настроил на автоматический перевод на английский.
Стиль: Дополнительные параметры, определяющие стиль изображения (например, «professional photo, studio lighting, 8k»).
Imagen стал моим инструментом для быстрых и понятных задач, когда нужно было просто создать объект на нейтральном фоне (но если честно, после появления нано банан gemini flash image я практически перестал им пользоваться).
Вот пример изображения по промпту
Gemini Flash: "Топ за свои деньги" (модель gemini-2.5-flash-image, он же Nano Banana).
ТУТ не хочу даже описывать ничего, это просто нереальный экспириенс. Я добавил возможность редактирования своих изображений и получил этот чертов нейрофотошоп (ну по крайней мере я так думал, пока не попробовал nanobananapro). Теперь я мог загрузить одно или несколько изображений-референсов и попросить ИИ создать что-то новое, но в похожем стиле. Например, я мог загрузить фотографию с определенной цветовой гаммой или композицией и попросить сгенерировать изображение своего товара в том же стиле. Это позволило уйти от подбора слов для описания стиля и просто показывать, что я хочу получить.
Тут я покажу для примера, как я улучшил рандомное изображение с авито.
Вот пример скачанных изображений:
Небольшой промпт и мы получаем чудесное преображение:
И получаем готовое изображение для карточки авито
Решив проблему с Авито, я быстро понял, что этот инструмент можно использовать и для других задач (просто как пример):
«Апскейл (улучшение) изображений»
«Затирание водяных знаков»
Конечно, все эти ваши бизнес сценарии хороши, но куда без баловства. Превращал себя с женой в рокеров, панков, монголов, древних русичей)))
Как вы поняли, вариаций использований данного инструмента может быть очень много. Тут все ограничивается вашей фантазией и необходимостью.
Все это подвело меня к следующему, революционному этапу (исключительно по моему мнению, на истину не претендую).
Gemini 3 Pro aka Nano banana PRO
Финальным и самым мощным дополнением к моей «фабрике изображений» стала модель Gemini 3 Pro. Если Imagen требовал четкого разделения запроса и стиля, а Gemini Flash отлично работал с визуальными референсами, то Gemini 3 Pro принес новую функцию - УМЕНИЕ ПИСАТЬ ТЕКСТ НА ИЗОБРАЖЕНИЯХ. Нельзя преувеличить важность этой функции. Да да, это открыло для всех новые дороги.
Раньше этот процесс был настоящей головной болью. Нужно было сначала сгенерировать идеальную картинку, сохранить ее, затем открыть в Photoshop или Canva, подобрать шрифт, добавить текст, выровнять его, наложить эффекты... Это был многоэтапный, ручной труд, который требовал навыков работы в графическом редакторе. Каждый раз, когда нужно было поменять текст — например, «Скидка 20%» на «Скидка 30%» — всё приходилось начинать заново.
Теперь всё изменилось. Я могу просто написать: «Сделай рекламный баннер с нашим защитным ботинком на фоне стройки, и добавь яркую надпись "НАДЁЖНАЯ ЗАЩИТА" в нижнем правом углу». И Gemini 3 Pro не просто генерирует картинку, он вписывает в неё текст, пытаясь сделать это гармонично.
Вот что было:
Умение работать с текстом и референсами привело меня к следующему и, думаю, самому важному инструментарию из всех перечисленных.
Генерация карточек для маркетплейсов с Nano Banana PRO
Умение Gemini 3 Pro работать с текстом на изображениях стало тем ключом, который открыл дверь к созданию, пожалуй, самого важного инструмента во всем проекте. Это превратило генератор из интересной «игрушки» в настоящую «производственную линию» для маркетинга. Я понял, что теперь могу автоматизировать не просто отдельные задачи, а целый цикл создания контента для маркетплейсов, и переписал логику, чтобы использовать три главные возможности этой модели.
Я добавил поле ввода описания продукта, поле ввода промпта, поле загрузки референса (пример того, как вы хотите, чтобы выглядело конечное изображение), поле загрузки вашего фото
1. Инфографика для маркетплейсов на основе текста
Первый и самый очевидный сценарий — это создание информативных карточек товаров. Раньше для этого требовалась последовательная работа дизайнера: взять фото товара, а затем в отдельном редакторе нанести на него преимущества, иконки и технические характеристики. Теперь этот процесс выглядит иначе.
Наше фото: (фото ботинка выше)
Наше описание:
Ботинки демисезонные
Материал : Натуральная кожа
Подкаладка: Типика
Материал верха - термоустойчивая водоотталкивающая кожа повышенной толщины (1,8 - 2,0 мм)
Подносок: термопласт
Подошва: Двухслойный полиуретан (ПУ+ПУ)
Соответсвует : ГОСТ 12.4.137-2001, ГОСТ 28507-99, ГОСТ 12.4.032-95.
Универсальная модель для тяжелых работ в различных отраслях промышленности: нефтегазовой, горнодобывающей, энергетической, в черной и цветной металлургии, на транспорте , в сельском хозяйстве и в строительстве.
Наш референс:
Наш промпт (сделаем его специально максимально простым):
Сделай карточку для маркетплейса
Модель не просто «лепит» текст поверх картинки. Она встраивает его в изображение, подбирая стиль и расположение. Текст может быть изогнут по форме объекта, на него могут быть добавлены тени, чтобы он выглядел органично. На выходе получается готовый слайд, который раньше дизайнер делал бы час.
2. Изображения на основе реальных данных
Но что, если информация на изображении должна быть не просто красивой, а технически верной? Здесь в дело вступает вторая возможность модели — связь с поиском Google.
К примеру, нам нужно разработать для производственного цеха плакат на тему «Правила использования страховочной привязи». Я задаю промпт: «Создай инфографику в виде плаката, показывающую по шагам, как правильно надевать трехточечную страховочную привязь. Покажи точки крепления: спинную, грудную, боковые».
Результат: Модель не выдумывает конструкцию привязи. Она обращается к поиску, находит реальные схемы и инструкции, и на основе этих данных рисует плакат.
3. Изображение для обучения
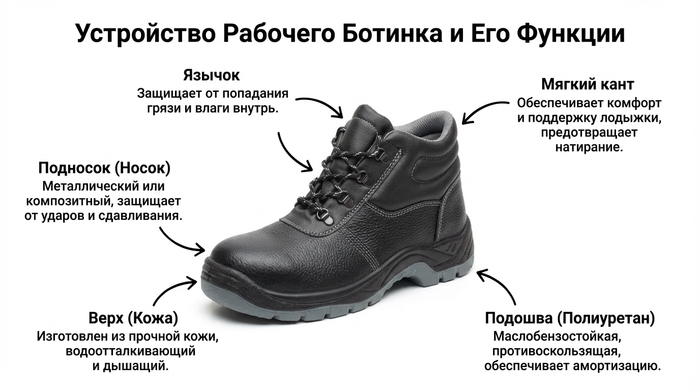
Изображение для обучения Есть задача сделать изображение для обучения? Тоже не проблема) Небольшой простой промпт (его конечно можно уточнять, но сейчас просто примеры) «создай изображение для обучающего материала. рабочий ботинок, на нем нужно указать все его детали и рассказать для чего они служат» и всё, смотрим результат:
Мой проект вырос из набора разрозненных скриптов в цельную рабочую среду. Теперь менеджер находит нужный товар в поисковике, тут же во вкладке «Генератор контента» создает для него презентацию для отдела продаж, а маркетолог в этой же вкладке делает для него карточку товара на сайт. Все происходит в одном окне и на базе единых данных. Я потратил на это ноль рублей на разработку, только время и средства на использование API, но взамен получил инструмент, который экономит часы рутинной работы и позволяет быстро тестировать маркетинговые гипотезы.
Оригинал моей статьи.
Всех благодарю за прочтение!