Новый инструмент: instruct pix2pix (Stable Diffusion)
За последние несколько дней кто-то сделал инструмент под названием instruct pix2pix который позволяет переделывать картинки, указывая компьютеру, что с картинкой надо сделать. Словами. На английском.
Для использования нужно уметь ставить свои чекпоинты. Если возиться не хотите, пролистывайте сразу к "что умеет".
----------------
Где брать:
Если у вас NMKD, включается в настройках вверху в выпадающем меню выбираете instruct-pix2pix.
Если у вас automatic1111, идём на вкладку "Extensions", находим там "instruct pix2pix"

Устанавливаем.
Потом идём сюда:
Качаем модель либо *.safetensors, либо *.ckpt и устанавливаем её как обычный чекпоинт, т.е. в папку models\Stable-diffusion ... потом всё перезапускаем. Для работы нужно будет выбрать модель в выпадающем списке.

Иначе работать не будет.
-------------------
Что умеет:
Берём исходное изображение:

Идём на новую вкладку, "instruct pix2pix", вставляем туда картинку, выставляем следующие настройки:
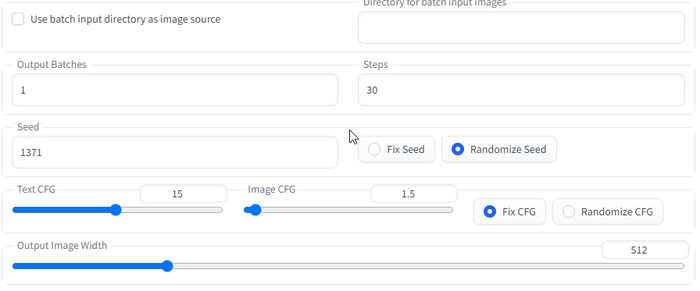
(Задрал TextCFG до 15, и количество шагов до 30), и даём команду:
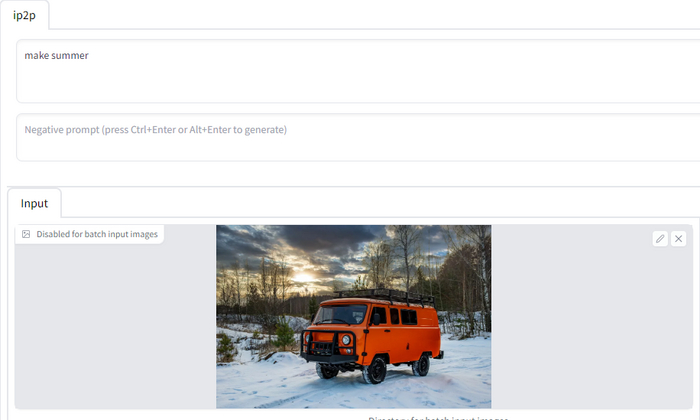
"Сделать лето" (make summer).
----------
Результат:

--------
"Сделать автомобиль серым" ("Make car gray")

(всё покрасило)
--------
Сделать небо чистым (make sky clear):

(ну, допустим, деревья нам не были сильно нужны были)
----
"Сделать пустыней" (make desert)

----
"Сделать другой планетой" (make alien planet)

-----
"Убрать колёса" (remove wheels)

(Ну... оно попыталось.)
-------
"Заменить машину на дом" (replace car with house)

----
"Сделать стимпанковым" (make car steampunk)

(Выглядит жутковато)
----
"Сделать футуристичным" ( make car scifi futuristic)

(Ну, гм. Похоже на масковский кирпич.)
-------
Теперь с людьми. Допустим, берём фото девушки с pixabay (кто под руку попался).

"Сделать блондинкой" (make blond)

-----
"Сделать моложе" (make younger)

-----
"Надеть пиджак"(wear suit)

(снизил textcfg до оригинального 7.5, иначе получалось 3 руки... и туловище всё равно мужское)
---
Т.е. в теории можно брать любую картинку, описывать словами как её переделать, и будет результат.
Проблемы/ ограничения:
* Документации по этой штуке по факту ноль. Вроде как понимает человеческий язык (английский), но это не точно. Оно с пылу с жару, только-только придумали и прикрутили.
* Нужно возиться с настройками и ползунками, некоторые запросы дают слабый эффект если не выкручивать Text CFG на максимум. Например попытка сделать уаз киберпанковским просто чуть-чуть картинку покрасит синим.
* При некоторых запросах сетка едет кукухой. Например, если попросить модель сделать кудрявой, можно получить вот это:

Но можно получить и вот это:

При некоторых запросах исходная картинка полностью отбрасывается. Например "сделать с короткой стрижкой" (make pixie cut) почти полностью заменяет картинку и получается вот так:

И чтобы это исправить надо возиться и тягать ползунки туда-сюда и не факт, что поможет.
* Визуальное качество, как можно заметить, проседает по сравнению со всякими протогенами и т.д.
* Никаких альтернативынх чекпоинтов на данный момент нет. Есть только instruct-pix2pix-00-2000 и всё. Как он работает, так и работает, без альтернатив. Самплеров тоже нет, работает с каким-то одним, и настроек только CFG и количество шагов.
А, и как сказал, штука очень новое, если что-то не запускается или не работает, ничем не смогу помочь. Кроме того, что если вместо частичной перерисовки вдруг начинает рисовать новые картинки, надо чекпоинт туда-сюда попереключать.
В общем, вот так вот. Развлекайтесь.
------
И небольшой бонус.
Исходник ( https://victorymuseum.ru/encyclopedia/technic/bronetankovaya-tekhnika/legkiy-broneavtomobil-ba-64b-sssr-/):

"Сделать автомобиль круглым" (make car round)

Вот теперь всё.