Краткий гайд по подключению МФУ. Для начала определим, что саму печать можно проводить по USB, а вот сканирование в серии Canon Image Runner идет только по сети LAN.
В ютюбе есть куча видео, где индусы настраивают сканирование через Mailbox. Как по мне - способ муторный и не удобный в последующем конвертировании документов.
Берем роутер. В моем случае -D-link DIR 615. Подключаем к нем через LAN МФУ и компьютер. Пример на фото:
(серый - компьютер, желтый -МФУ).
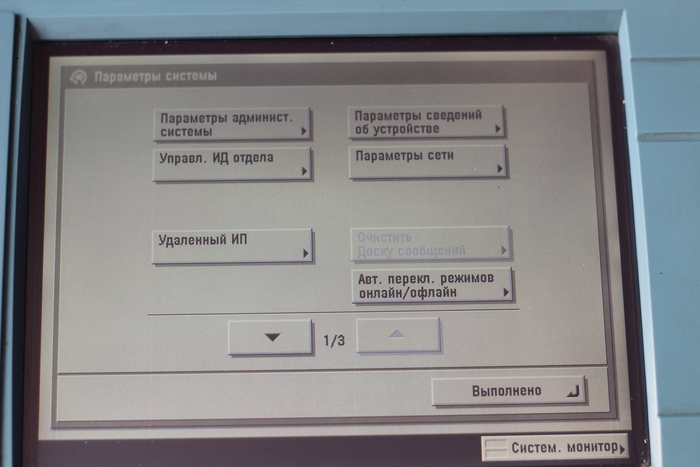
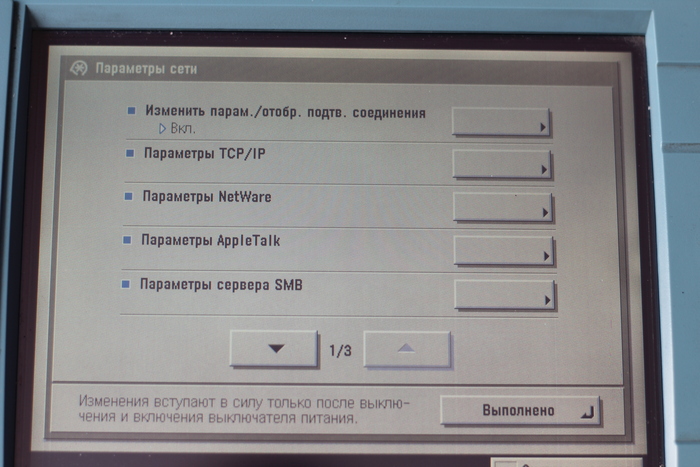
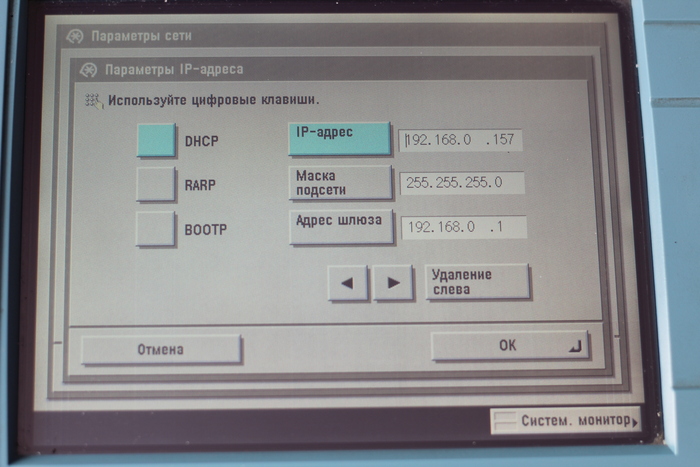
Теперь открывает в окне принтера настройки IP.
Обязательно включаем DHCP. Так же стоит запомнить IP, далее он нам понадобится. Везде нажимаем [OK]. Переходим на главной панели во вкладку сканера.
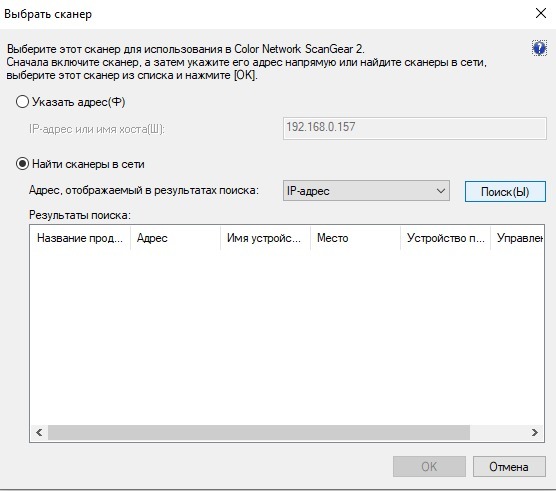
Теперь, нам понадобится программа - либо Color Network ScanGear tool, либо Advenced IP scanner.
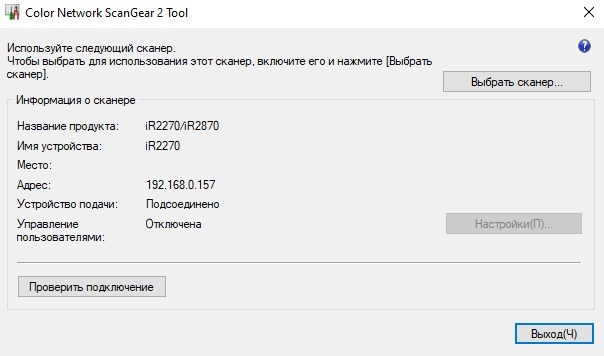
И тут есть два способа: указать адрес и найти. Вот здесь, если будем указывать в ручную, нам и понадобится IP адрес, который мы ранее запомнили. Если нигде нет повреждений(LAN, роутер, порты), то наше МФУ сразу обнаружится в сети. Далее нажимаем [OK] и проверяем соединение в этом окне:
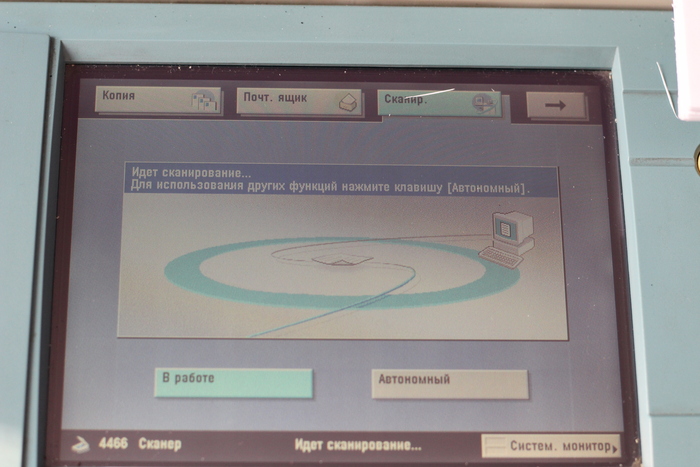
Вся основная работа сделана. Если вбить в поисковую строку IP принтера, то нас переведет на Mailbox.
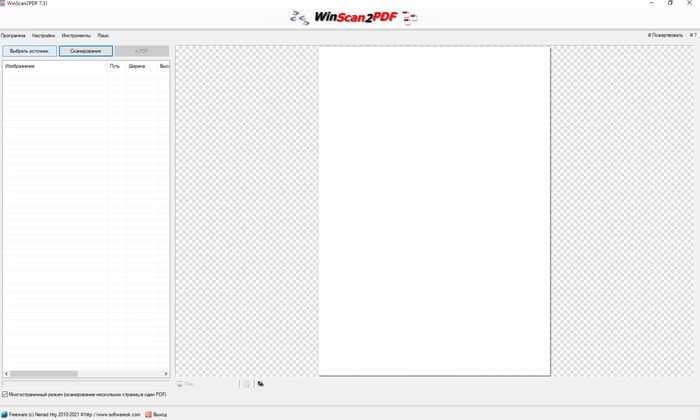
Далее нам понадобится программа для сканирования. Лично я использую Winscan2PDF (может кто лучше вариант подскажет, буду признателен).
Здесь выбиваем источник сканирования.
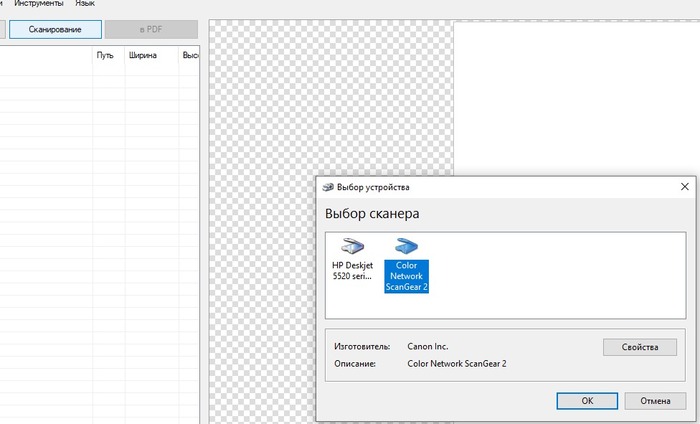
У нас появляется окно, где нужно выбрать Color Network ScanGear. Далее [OK].
Теперь можно полноценно сканировать! На этом все.
P.s. Передаю огромную благодарность @cybfh, очень отзывчивый пикабушник, без которого я не мог решить этот вопрос со сканером на протяжении 5-7 лет. Так как периодически работаю с машинами серии Canon IR.