Приветствую, коллеги! Меня зовут @ProstoKirReal. Мне бы хотелось с вами обсудить как работает интернет от кабелей на витой паре, соединяющие простые локальные сети до подводных коммуникационных кабелей соединяющие между собой континенты и основные операторские сети.
Поскольку в одной статье невозможно охватить всю тему целиком, я разделю подготовленный материал на несколько частей. Сегодня мы начнем с базовых понятий.
Важно понимать, что разобраться во всех аспектах этой темы сложно, так как существуют узкие специализации и знания, недоступные обычному сетевому инженеру. Я не буду углубляться в историю интернета или рассказывать о классах IP-адресов и других устаревших концепциях. Вместо этого я сосредоточусь на том, как работает интернет в настоящее время.
В этом цикле статей я не стану учить вас настраивать оборудование и проектировать сети. Я расскажу об основных (и не только) принципах построения сети, а также о функционировании сети и сетевых протоколов в стеке TCP/IP.
Я буду часто ссылаться к предыдущим статьям, где уже описывал сетевые протоколы. Это позволит мне сократить объемный текст.
❯ Зачем нужна эта статья?
Данная статья нужна нам для того, чтобы разобраться в базовых знаниях и разобрать:
- что такое коммутатор, маршрутизатор, их основные различия и зачем они нужны; - примеры работы простых сетей, с помощью сетевых концентраторов (хабов) и коммутаторов.
❯ Что такое коммутатор, маршрутизатор?
Когда мы задаем вопрос в поисковике: «Чем отличается коммутатор от маршрутизатора?», то один из самых распространенных ответов, который можно найти в интернете (например, на Mail.ru), звучит так:
в функционале. маршрутизатор - маршрутизирует, коммутатор - коммутирует. все просто:)))
Это, пожалуй, самый краткий и ёмкий ответ на данный вопрос.
Однако если подойти к вопросу серьезно, необходимо разобраться в понятиях коммутации и маршрутизации.
Коммутация — это процесс перенаправления данных (кадров) в пределах одной сети, основанный на анализе адреса назначения. Она работает на канальном уровне модели OSI (L2), используя MAC-адреса устройств.
Маршрутизация — это процесс определения пути для передачи данных между разными сетями. Работает на сетевом уровне модели OSI (L3), используя IP-адреса.
Коммутаторы (switch) и маршрутизаторы (router) — это два ключевых устройства в сетевых инфраструктурах, которые выполняют разные, хотя и пересекающиеся, задачи. Разберемся в их функциях, особенностях и причинах появления, а также рассмотрим современные реалии, в которых их функциональность все больше пересекается.
Зачем появились маршрутизаторы
Исторически маршрутизаторы появились для соединения сетей с разными технологиями передачи данных. В начале эры сетей существовало множество локальных сетей (LAN) с различными стандартами: Ethernet, Token Ring, модемные пулы и другие. Эти сети были физически и логически разобщены, поскольку каждая из них использовала свои протоколы адресации и методы передачи данных.
Для решения этой проблемы была введена абстракция в виде IP-адреса — универсального протокола, не привязанного к физическому носителю. Маршрутизаторы стали устройствами, способными связывать сети с разными технологиями передачи данных, обеспечивая маршрутизацию на основе IP-адресов.
Основные функции
Коммутаторы:
работают преимущественно на уровне 2 модели OSI (канальный уровень);
создают таблицы MAC-адресов, которые определяют, через какой физический порт отправлять трафик;
обеспечивают коммуникацию внутри одной локальной сети (LAN).
Маршрутизаторы:
работают на уровне 3 модели OSI (сетевой уровень);
используют таблицы маршрутизации для определения оптимального пути передачи данных;
обеспечивают связь между разными сетями, в том числе с разными технологиями (Ethernet, Frame Relay, ATM, DSL);
используют протоколы маршрутизации, такие как OSPF, BGP, IS-IS.
Совместная работа коммутаторов и маршрутизаторов
Коммутаторы обеспечивают быстрый обмен данными внутри сети.
Маршрутизаторы соединяют локальную сеть с другими сетями, например, с интернетом, обеспечивая связь с серверами.
❯ Современные тенденции
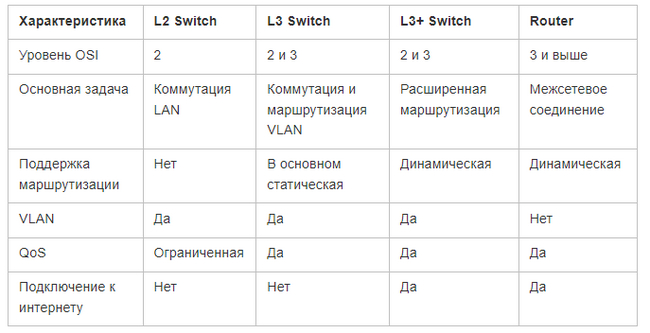
Раньше этих различий хватало для определения работы коммутатора и маршрутизатора, но в современных устройствах все эти функции часто объединяются в L3-коммутаторах, которые совмещают преимущества обоих типов устройств. На данный момент различия между ними размыто, так как коммутаторы L3 и L3+ (Multiplayer switch) могут выполнять часть функционала маршрутизатора и маршрутизатор может иметь дополнительные физические порты для подключения локальных сетей.
❯ Рассмотрим различия между устройствами
L2-коммутаторы (канальный уровень)
❯ Особенности
Рабочий уровень: работают на 2 уровне модели OSI (канальный уровень).
Функциональность: обеспечивают передачу данных внутри одной локальной сети (LAN), используя таблицу MAC-адресов для маршрутизации кадров Ethernet.
Ограничения: не способны маршрутизировать трафик между разными VLAN или подсетями.
поддерживают IP-адресацию и статическую маршрутизацию.
❯ Плюсы
Универсальность.
Встроенная поддержка маршрутизации.
❯ Минусы
Ограниченные возможности динамической маршрутизации (по сравнению с маршрутизаторами). Обычно используется «межвлановая» маршрутизация, когда ip-адрес назначается на VLAN, а не на саб-интерфейс.
Более сложная настройка по сравнению с L2-коммутаторами.
L3+ коммутаторы (расширенные возможности сетевого уровня)
❯ Особенности
Рабочий уровень: также работают на 3 уровне, но с функциями, приближенными к маршрутизаторам.
Функциональность:
полноценная поддержка динамических протоколов маршрутизации (OSPF, BGP, EIGRP);
расширенные функции управления трафиком: ACL, QoS, NAT;
некоторые модели поддерживают MPLS для оптимизации передачи данных.
❯ Плюсы
Возможности динамической маршрутизации.
Более высокий уровень управления сетью.
❯ Минусы
Стоимость.
Сложность настройки.
Маршрутизаторы (Router)
❯ Особенности
Рабочий уровень: работают на 3 уровне модели OSI и выше.
поддержка VPN, NAT и часть функций межсетевого экранирования.
❯ Плюсы
Поддержка работы в глобальных сетях (WAN).
Высокий уровень безопасности.
❯ Минусы
Не предназначены для высокоскоростного L2-коммутирования.
Могут вызывать дополнительные задержки в локальных сетях.
❯ Сравнительная таблица
L2-коммутаторы идеально подходят для небольших сетей, где маршрутизация не требуется.
L3-коммутаторы — оптимальное решение для сетей с VLAN и умеренной сложностью.
L3+ коммутаторы находят применение в крупных и сложных инфраструктурах с необходимостью динамической маршрутизации.
Маршрутизаторы — необходимы для соединения локальных сетей с внешними сетями, но не заменяют коммутаторы внутри LAN.
Каждое устройство имеет свои уникальные сильные стороны и применяется в зависимости от масштабов и требований сети.
Хотя изначально коммутаторы и маршрутизаторы выполняли строго разные задачи, современное развитие сетевых технологий привело к значительному пересечению их функций.
Однако ключевые различия сохраняются: маршрутизаторы лучше подходят для связи между сетями с различными технологиями и для управления сложными топологиями, тогда как коммутаторы оптимизированы для высокой пропускной способности и коммутации в рамках одной сети. Выбор между этими устройствами зависит от конкретных задач и архитектуры сети.
❯ Что такое сеть?
Что же такое сеть? Если соединить два компьютера между собой, назначить им IP-адреса, будет ли это сетью? Ответ прост: да, это уже локальная сеть.
Сеть — это соединение двух и более компьютеров, устройств или других компонентов для обмена информацией.
Как только мы подключаем устройства к домашнему маршрутизатору, они становятся частью локальной сети. Маршрутизатор служит шлюзом по умолчанию для всех подключенных устройств и направляет пакеты данных для выхода в интернет.
Но пока не будем забегать вперед, начнем с самого простого — с двух соединенных между собой компьютеров.
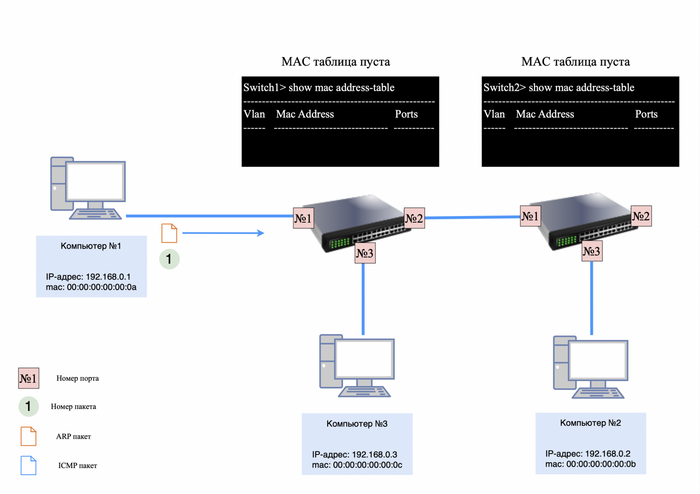
❯ Рассмотрим самую простую сеть
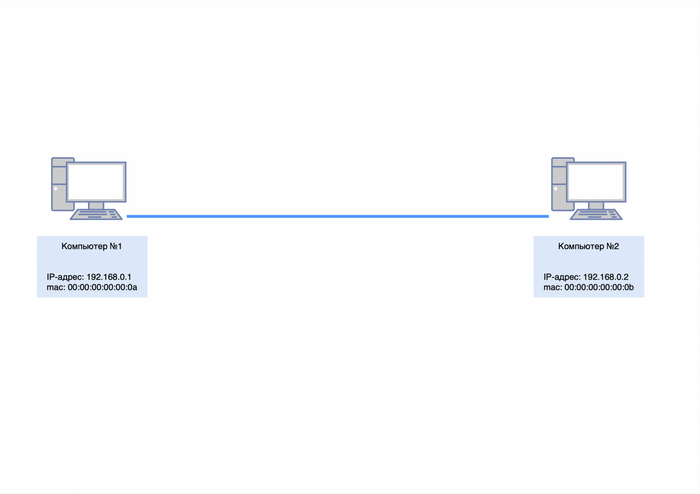
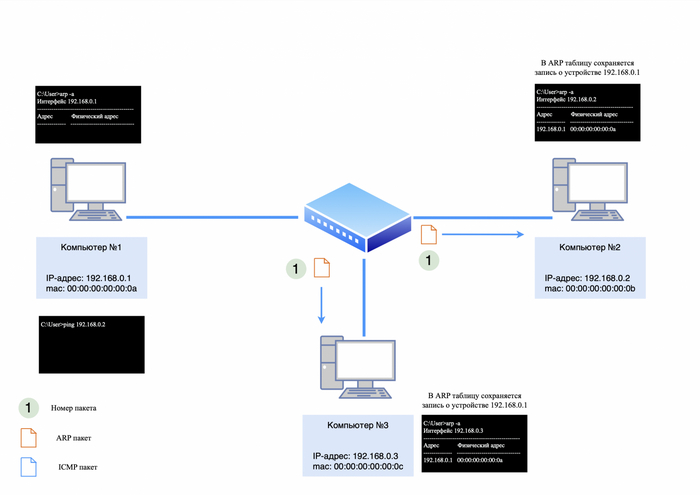
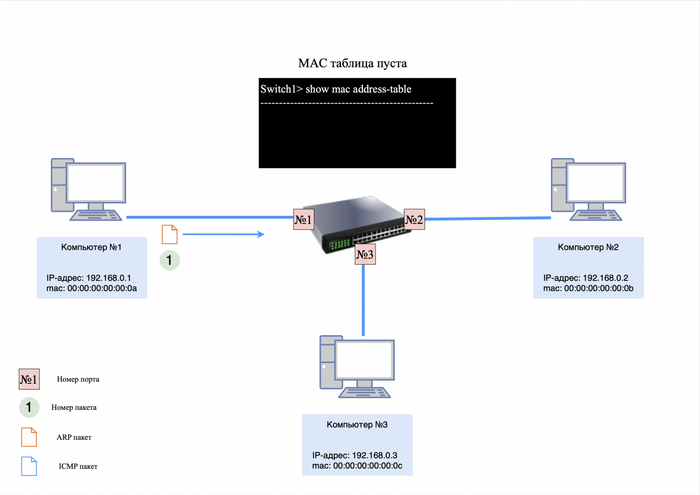
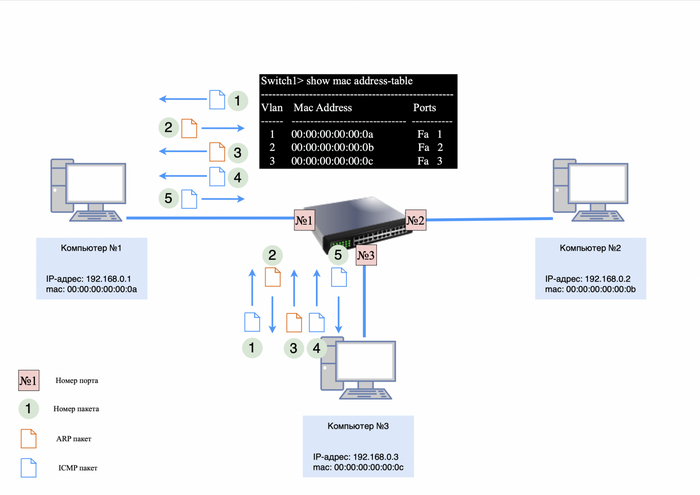
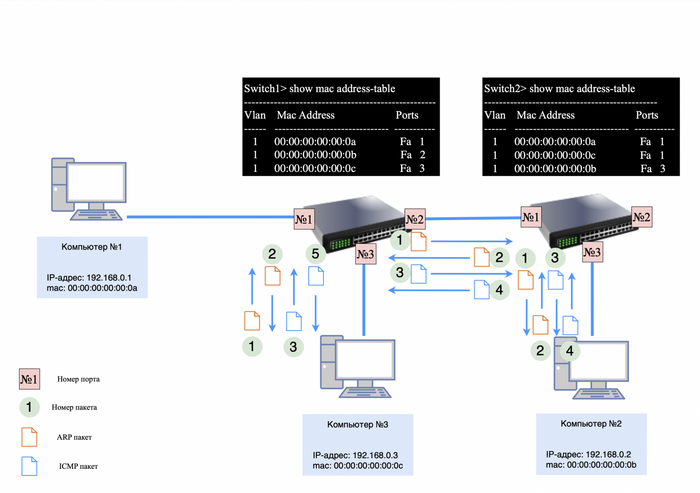
Предположим, у нас есть два компьютера. Компьютер №1 имеет mac-адрес 00:00:00:00:00:0a, а компьютер №2 — 00:00:00:00:00:0b.
Мы назначаем компьютеру №1 IP-адрес 192.168.0.1, а компьютеру №2 — IP-адрес 192.168.0.2. Затем мы соединяем их сетевые карты «напрямую» с помощью витой пары.
Адресация компьютера №1 и №2
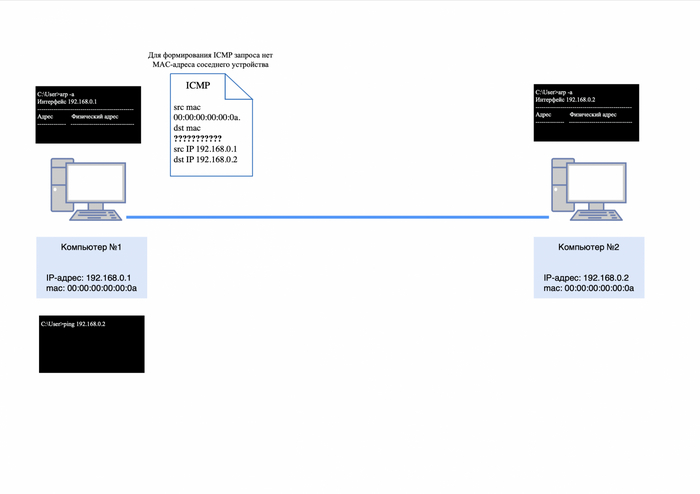
Чтобы проверить доступность соседнего компьютера, можно использовать утилиту «ping» и отправить запрос на него.
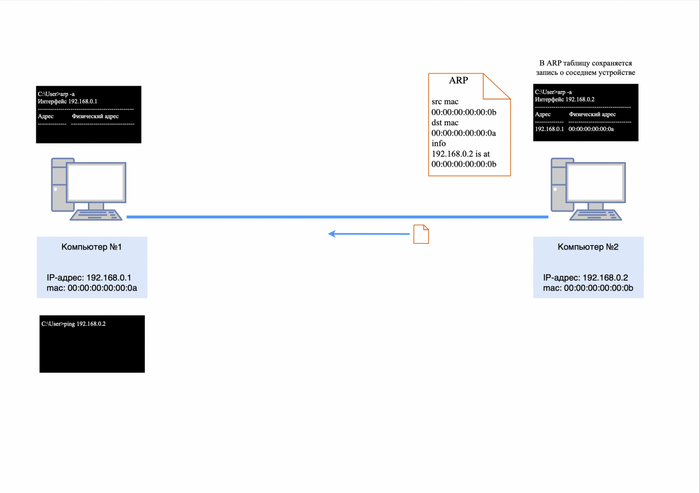
Однако есть проблема: компьютер №1 не сможет сразу отправить ICMP-запрос компьютеру №2, так как он не знает его mac-адрес. Это можно проверить, введя команду «arp -a» в командной строке (для Windows) и убедившись, что таблица ARP пуста.
Формирование ICMP-запроса невозможна
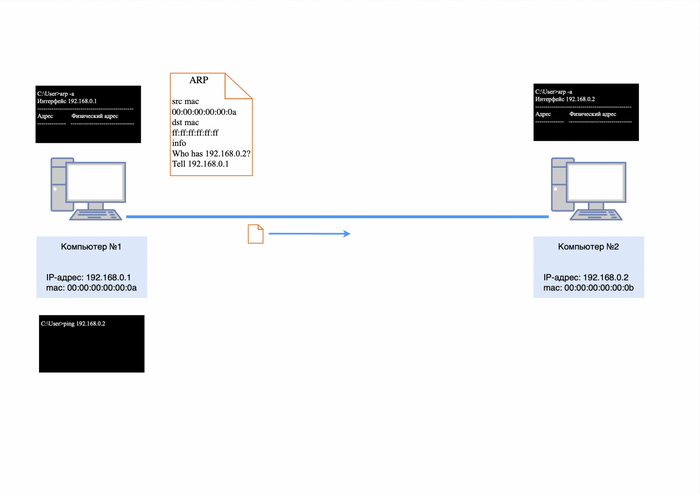
Как было сказано в предыдущей статье, ARP (Address Resolution Protocol) — это важнейший протокол в компьютерных сетях, который используется для определения MAC-адреса другого компьютера по известному IP-адресу.
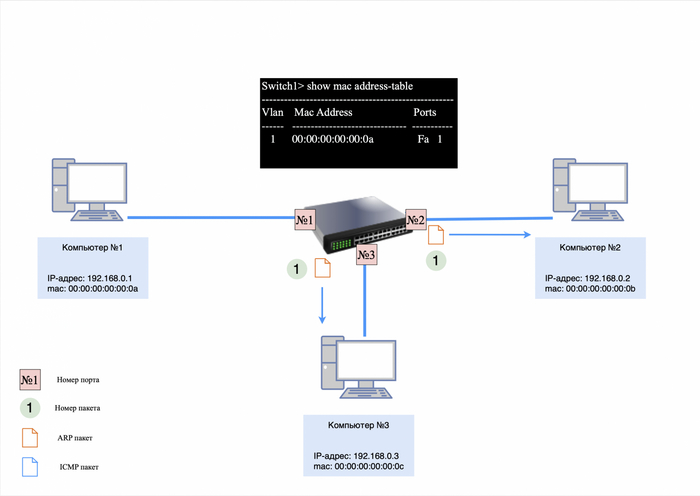
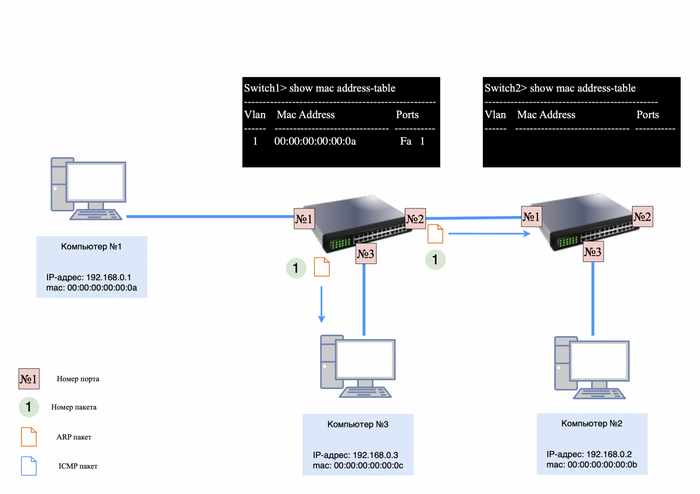
Первым делом компьютер №1 отправит широковещательный запрос в сеть, чтобы узнать, кто такой 192.168.0.2.
IP-адресов не будет, так как ARP работает на уровне L2;
в теле пакета будет информация: кто такой 192.168.0.2, спрашивает 192.168.0.1.
ARP-запрос
Подробнее о заголовках L3 уровня (ARP, ICMP и др.) я рассказывал в этой статье.
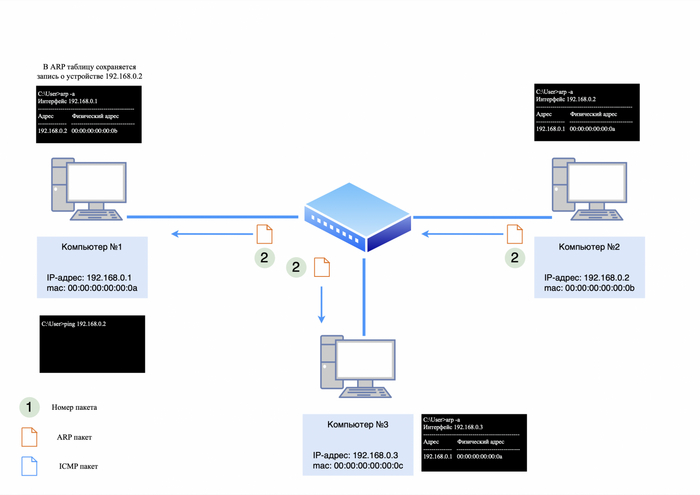
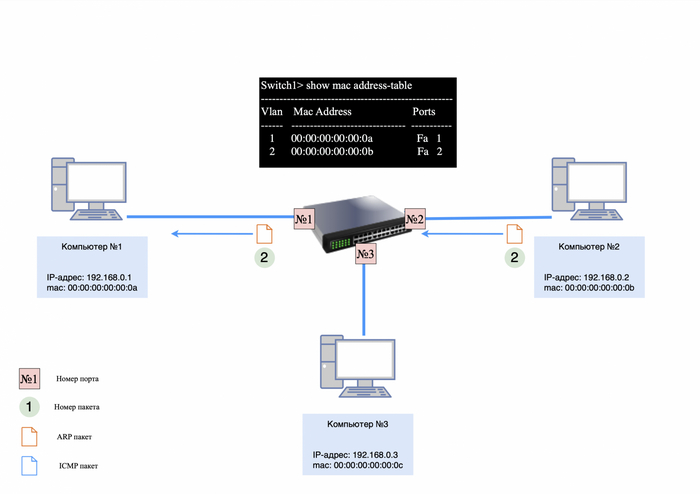
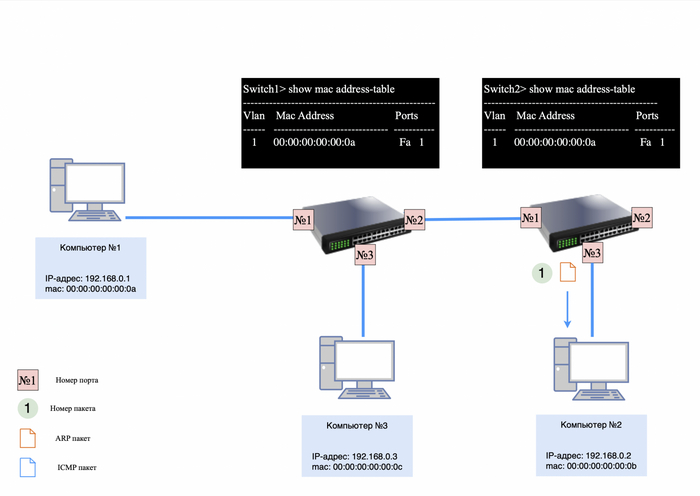
После того как ARP-ответ будет получен компьютером №2, он сохранит в своей ARP-таблице информацию о IP и mac-адресе компьютера №1.
Теперь компьютеру необходимо отправить ARP-ответ.
Пакет будет выглядеть следующим образом:
src mac-адрес 00:00:00:00:00:0b;
dst mac-адрес 00:00:00:00:00:0a;
IP-адресов не будет, так как ARP работает на уровне L2;
в теле пакета будет информация: у IP-адреса 192.168.0.2 mac-адрес - 00:00:00:00:00:0b.
ARP-ответ
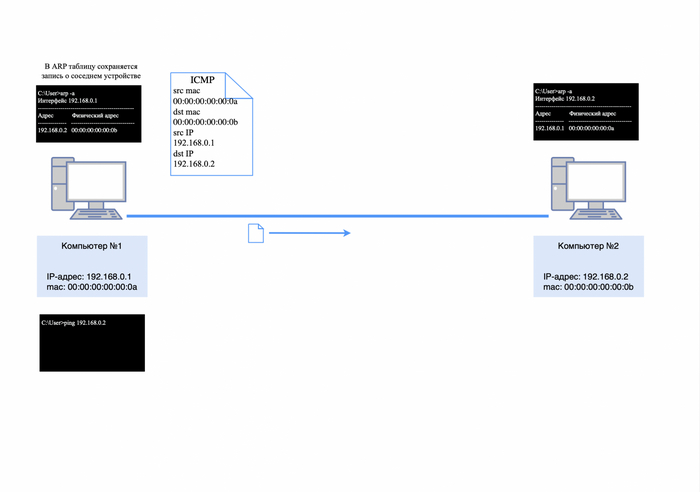
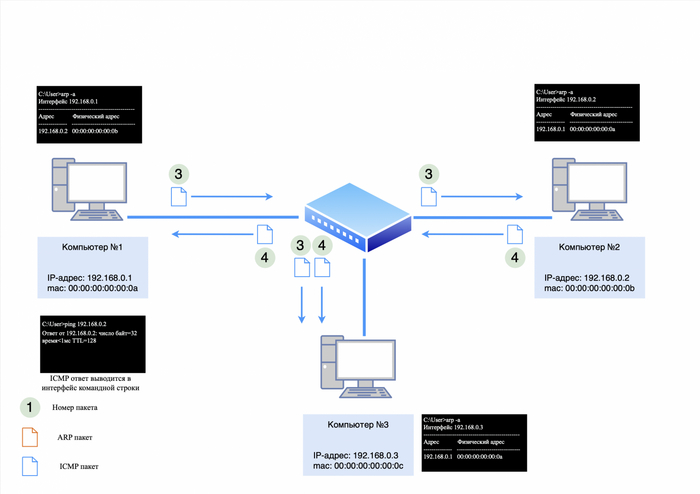
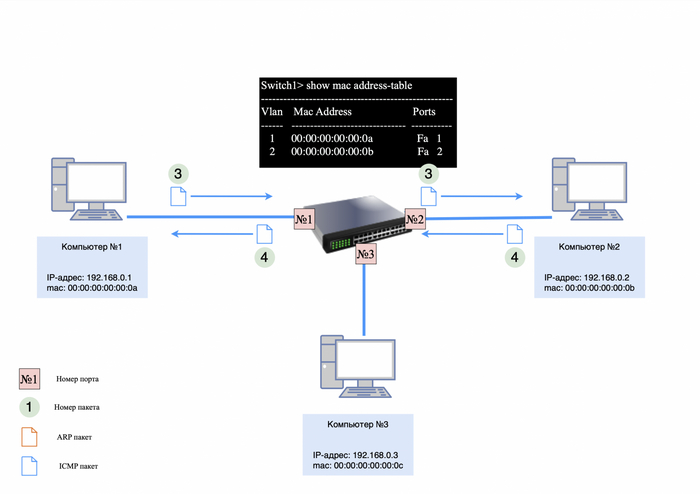
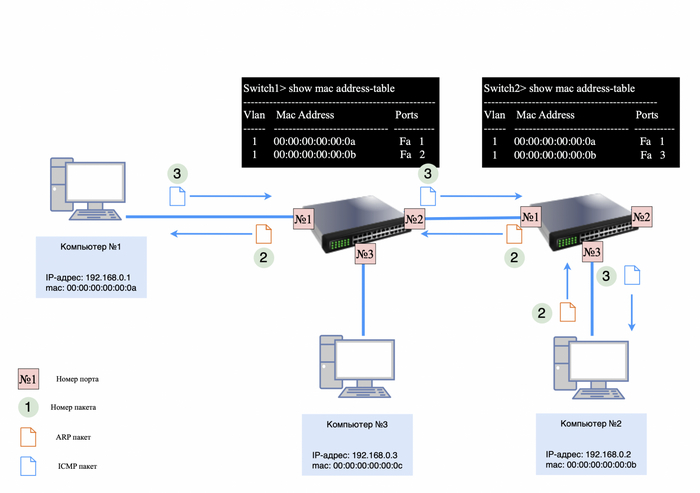
После того как ARP-ответ поступит к компьютеру №1, он сохранит в своей ARP-таблице информацию о IP и mac-адресе компьютера №2. Теперь для формирования ICMP-запроса известна вся информация, и от компьютера №1 будет сформирован следующий пакет:
src mac-адрес 00:00:00:00:00:0a;
dst mac-адрес 00:00:00:00:00:0b;
src IP-адрес 192.168.0.1;
dst IP-адрес 192.168.0.2
в теле пакета будет служебная информация для ICMP-протокола (подробнее в этой статье).
ICMP-запрос
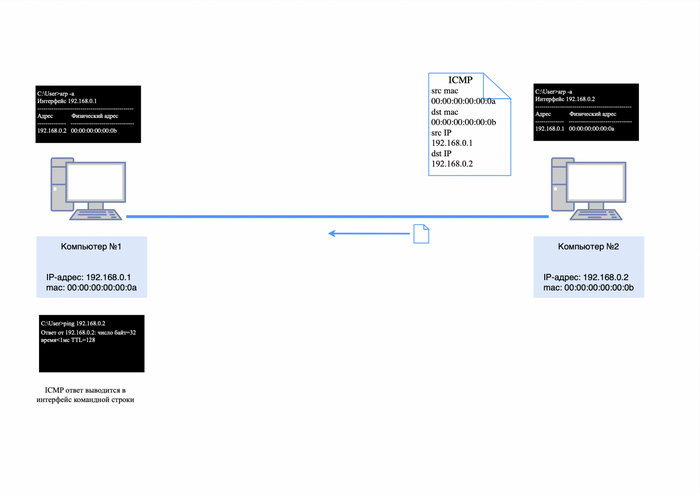
После того как ICMP-запрос поступит на компьютер №2, тот отправит ICMP-ответ, так как уже знает mac-адрес соседнего устройства из своей ARP-таблицы.
Ответ будет выглядеть следующим образом:
src mac-адрес 00:00:00:00:00:0b;
dst mac-адрес 00:00:00:00:00:0a;
src-IP-адрес 192.168.0.2;
dst-IP-адрес 192.168.0.1;
в теле пакета будет служебная информация для ICMP-протокола.
После того как все эти пакеты прошли свой не долгий путь, в утилите «ping» появится первое сообщение о доступности соседнего устройства.
ICMP-ответ
❯ Три компьютера и сетевой концентратор (Hub)
❯ Что если нам нужно подключить больше компьютеров к одной сети?
Хаб передает данные, поступающие на один из его портов, на все остальные порты, что позволяет устройствам в локальной сети обмениваться информацией без сложной настройки. Однако такой подход имеет свои плюсы и минусы.
❯ Плюсы и минусы использования хаба
Хаб — это недорогое сетевое устройство, которое подходит для соединения небольших локальных сетей. Однако, если в сети используется большое количество устройств, возникают проблемы.
Эффективность: хаб работает на уровне L1 модели OSI, что означает, что он не различает адреса. Все пакеты передаются всем устройствам, кроме отправителя, независимо от их назначения.
Конфликт пакетов: поскольку данные передаются одновременно всем устройствам, в сети могут возникать коллизии. Чем больше устройств подключено, тем выше вероятность коллизий.
Пропускная способность: каждый порт хаба делит общую пропускную способность сети, что приводит к её снижению по мере увеличения числа подключений.
Современные сети используют коммутаторы (switch), которые работают на уровне L2, что позволяет им направлять пакеты только устройствам-адресатам.
❯ Пример работы хаба
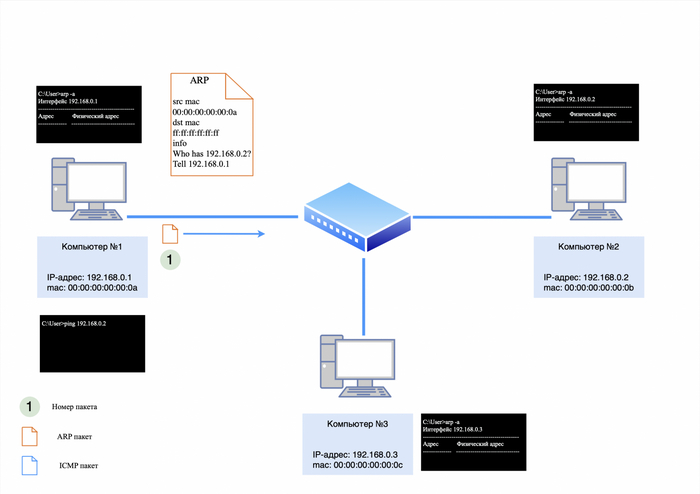
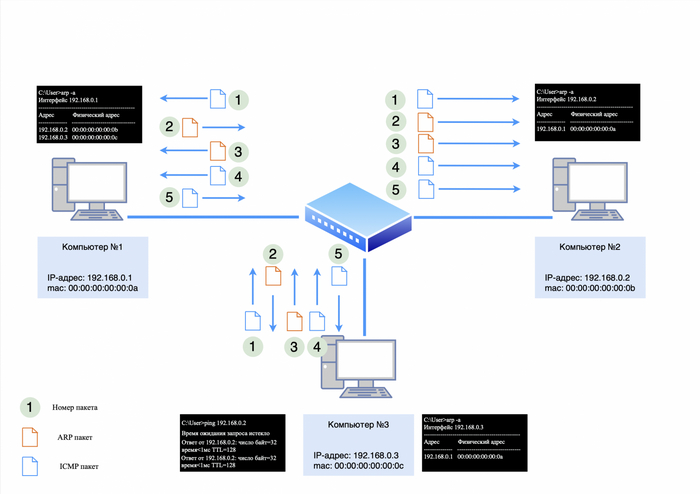
Предположим, у нас есть хаб и три компьютера с IP-адресами:
компьютер №1: 192.168.0.1;
компьютер №2: 192.168.0.2;
компьютер №3: 192.168.0.3.
Все три компьютера подключены к хабу. Теперь, если мы с компьютера №1 отправим запрос «ping» на компьютер №2, то процесс будет происходить следующим образом.
Шаг 1. ARP-запрос
Компьютер №1 сначала отправит ARP-запрос в сеть, чтобы узнать MAC-адрес компьютера №2. Этот запрос будет выглядеть так:
IP-адреса в пакете отсутствуют, так как ARP работает на уровне L2.
ARP-запрос к компьютеру №2
Действия хаба
Хаб получит этот пакет через порт, к которому подключен компьютер №1, и передаст его на все остальные порты, кроме порта-отправителя. Таким образом, ARP-запрос поступит как на компьютер №2, так и на компьютер №3. Компьютеры №2 и №3 сохранят в ARP-таблице запись о компьютере №1, так как запрос был широковещательным. Однако ответит на него только компьютер №2, так как IP-адрес в запросе соответствует его собственному.
Сохранение mac-адреса в arp таблицу
Ответ от компьютера №2
Компьютер №2 отправит ARP-ответ, который пройдет через хаб и будет доставлен компьютеру №1. Компьютер №3 проигнорирует этот ответ, так как он не предназначен ему.
ARP-ответ будет выглядеть следующим образом:
src MAC-адрес: 00:00:00:00:00:0b;
dst MAC-адрес: 00:00:00:00:00:0a;
IP-адреса в пакете отсутствуют, так как ARP работает на уровне L2.
ARP-ответ компьютеру №1
Шаг 2. ICMP-запрос и ответ
После завершения ARP-обмена компьютер №1 сформирует ICMP-запрос и отправит его на компьютер №2. Запрос и последующий ответ будут переданы аналогичным образом через хаб, но пакеты также дойдут до всех устройств в сети, создавая дополнительную нагрузку.
ICMP-запрос/ответ
❯ Особенности работы ARP в сети с хабом
В такой схеме:
Компьютеры №1 и №2 знают о существовании друг друга;
Компьютер №3 знает о компьютере №1, так как получил его ARP-запрос, но не знает о компьютере №2.
Небольшое пояснение почему:
Компьютер №3 знает о Компьютере №1 из своей ARP-таблицы, но не знает о Компьютере №2 по следующим причинам:
Обработка ARP-запросов.
ARP-запросы обрабатываются операционной системой компьютера, а не сетевой платой. Однако, поскольку ARP-запрос имеет широковещательный MAC-адрес назначения (ff:ff:ff:ff:ff:ff), он достигает всех устройств в локальной сети и принимается сетевой платой;
Сохранение записи в ARP-таблице.
Хотя Компьютер №3 получает ARP-запрос, адресованный другому IP-адресу (например, Компьютеру №1), он не отвечает на него. Однако информация из тела пакета (IP-адрес и MAC-адрес Компьютера №1) может быть сохранена в ARP-таблице Компьютера №3 как часть пассивного процесса обучения;
Отбрасывание ARP-ответа.
ARP-ответ, отправленный Компьютером №1, также достигает Компьютера №3. Однако, поскольку MAC-адрес назначения в этом пакете не совпадает с MAC-адресом сетевой карты Компьютера №3, пакет отбрасывается сетевой платой на аппаратном уровне. В результате информация о Компьютере №2 не попадает в ARP-таблицу Компьютера №3.
Если мы попытаемся «пингануть» с компьютера №2 компьютер №3, произойдет ARP-обмен, как в примере выше. Однако если мы попытаемся с компьютера №3 «пингануть» компьютер №1, процесс будет следующим:
Компьютер №3, зная MAC-адрес компьютера №1 из своей ARP-таблицы, сразу отправит ICMP-запрос;
Компьютер №1, не имея записи о компьютере №3, отбросит запрос и отправит широковещательный ARP-запрос;
После получения ARP-ответа от компьютера №3 компьютер №1 сможет ответить на ICMP-запрос;
Компьютер №3 отправит новый ICMP-запрос, на который компьютер №1 успешно ответит.
Когда мы запускаем утилиту «ping», некоторые пакеты теряются. Это происходит из-за того, что требуется ARP-обмен данными между всеми промежуточными устройствами. Именно поэтому возникает необходимость в обмене данными с использованием протокола ARP между всеми устройствами, находящимися между источником и получателем данных.
Обмен между компьютером №3 и №1
❯ Три компьютера и L2 коммутатор
❯ Как обеспечить стабильность работы сети и исключить коллизии?
Ответ прост: использовать L2-коммутатор.
❯ Принцип работы L2-коммутатора
Коммутатор работает на канальном уровне модели OSI и использует MAC-адреса для пересылки данных. Рассмотрим на примере, как это происходит.
Устройства в сети:
компьютер №1: 192.168.0.1;
компьютер №2: 192.168.0.2;
компьютер №3: 192.168.0.3;
коммутатор №1: MAC-таблица изначально пуста.
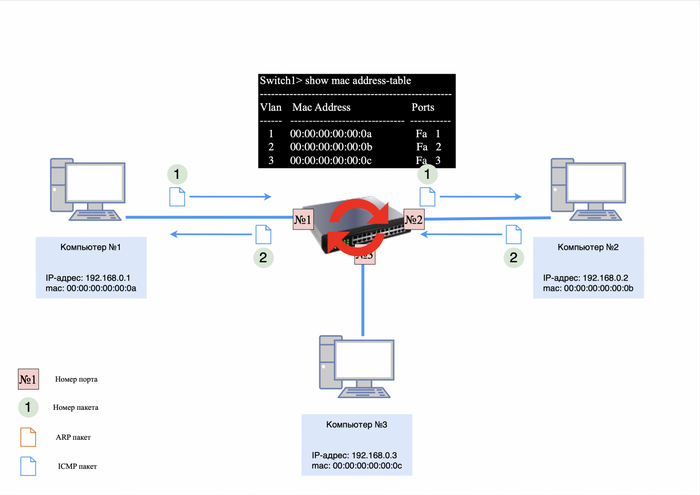
Шаг 1. ARP-запрос
Когда компьютер №1 отправляет запрос «ping» на компьютер №2, он сначала формирует ARP-запрос для определения MAC-адреса получателя. Этот запрос поступает на коммутатор, который, не имея записей в MAC-таблице, рассылает его на все активные порты, кроме порта-отправителя.
Пустая MAC-таблица на коммутаторе
Действия коммутатора:
Коммутатор добавляет в свою MAC-таблицу запись о компьютере №1, связав его MAC-адрес с портом, через который пришел запрос;
ARP-запрос доставляется компьютерам №2 и №3.
Первая запись в MAC-таблицу
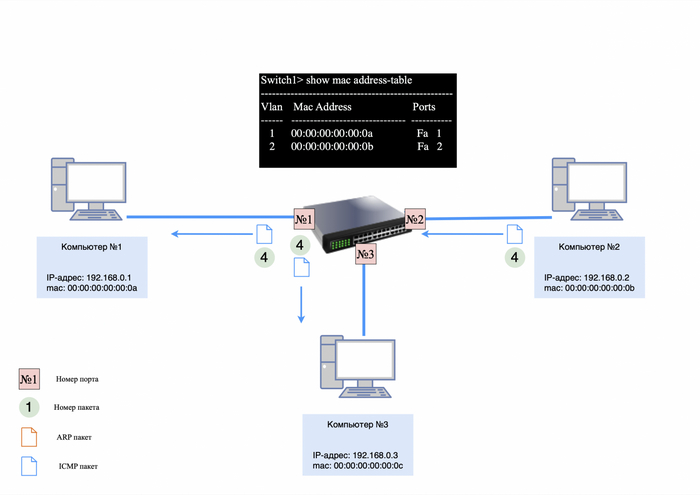
Ответы компьютеров:
Компьютер №2, распознав свой IP-адрес, отправляет ARP-ответ;
Компьютер №3 игнорирует запрос, но сохраняет запись о MAC-адресе компьютера №1 в своей ARP-таблице.
Коммутатор, получив ARP-ответ от компьютера №2, обновляет свою MAC-таблицу, добавляя запись о MAC-адресе компьютера №2.
Вторая запись в MAC-таблицу
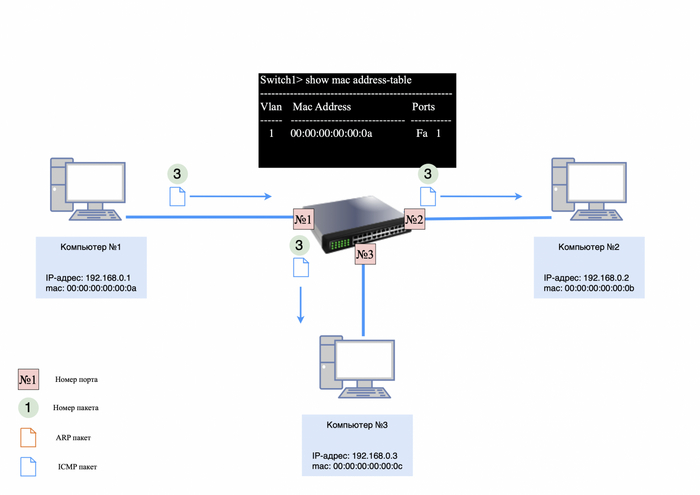
Шаг 2. ICMP-запрос и ответ
После завершения ARP-обмена компьютер №1 отправляет ICMP-запрос компьютеру №2. Благодаря MAC-таблице, коммутатор направляет пакеты только в порт, подключенный к компьютеру №2, избегая лишней нагрузки на другие устройства.
ICMP-запрос/ответ через коммутатор
❯ Особенности работы ARP в сети с коммутатором
Компьютеры №1 и №2 знают о существовании друг друга;
Компьютер №3 знает MAC-адрес компьютера №1, но не знает о существовании компьютера №2;
В MAC-таблице коммутатора нет записи о компьютере №3.
Если компьютер №3 отправит запрос «ping» на компьютер №1, процесс будет следующий:
Компьютер №3 сразу формирует ICMP-запрос, используя MAC-адрес из своей ARP-таблицы;
Коммутатор передает пакет на порт компьютера №1;
компьютер №1, не имея записи о компьютере №3, отправляет ARP-запрос;
после завершения ARP-обмена компьютер №1 отвечает на ICMP-запрос.
Третья запись в MAC-таблице
❯ Что будет если во время работы коммутатор перезагрузится?
Если коммутатор перезагрузится или его MAC-таблица очистится, он начнет временно работать как хаб, передавая пакеты на все порты, пока MAC-таблица не будет заполнена.
Очистка MAC-таблицы
В этой ситуации происходит следующее:
Пакет, адресованный компьютеру №2, поступает на коммутатор. Поскольку MAC-таблица коммутатора пуста, чтобы обеспечить корректную работу сети, коммутатор передает эти пакеты на все порты, кроме того порта, через который они были получены. Затем в MAC-таблицу коммутатора добавляется первая запись о компьютере №1;
Первая запись в MAC-таблицу
Затем коммутатор получит пакет, предназначенный для компьютера №2. Поскольку в MAC-таблице нет записи об этом компьютере, чтобы обеспечить корректную работу сети, коммутатор передаст эти пакеты на все порты, кроме того порта, через который они были получены. После этого в MAC-таблицу коммутатора будет добавлена первая запись о компьютере №2;
Далее сеть будет работать так же, как и до перезагрузки или очистки MAC-таблицы.
Вторая запись в MAC-таблицу
Ключевое отличие коммутатора от концентратора (хаба) заключается в следующем: хаб, независимо от обстоятельств, всегда будет пересылать пакеты во все порты, кроме того, из которого этот пакет был получен. В свою очередь, коммутатор передает пакеты на все порты до тех пор, пока в его MAC-таблице не появятся записи. Как только в таблице появляются записи, коммутатор направляет пакеты в соответствующие порты.
❯ Три компьютера и несколько L2 коммутаторов
Рассмотрим, как работает сеть с несколькими коммутаторами.
Устройства в сети:
компьютер №1: 192.168.0.1;
компьютер №2: 192.168.0.2;
компьютер №3: 192.168.0.3;
коммутатор №1 и №2: MAC-таблица изначально пуста.
Все три компьютера подключены к нескольким коммутаторам. Если с компьютера №1 отправить запрос «ping» на компьютер №2, ARP-запрос попадет на коммутатор и будет направлен во все активные порты, поскольку это широковещательный запрос.
MAC-таблица пустая у обоих коммутаторов
Шаг 1. ARP-запрос
Когда компьютер №1 отправляет ARP-запрос компьютеру №2:
Коммутатор №1:
передает запрос на все порты, кроме порта-отправителя;
сохраняет в MAC-таблицу запись о компьютере №1.
Первая запись в MAC-таблицу коммутатора №1
Коммутатор №2:
получает запрос от коммутатора №1 и передает его на свои порты;
добавляет в MAC-таблицу запись о MAC-адресе компьютера №1.
Компьютеры №2 и №3 сохраняют запись о MAC-адресе компьютера №1.
Первая запись в MAC-таблицу коммутатора №2
Шаг 2. ICMP-запрос и ответ
Когда компьютеры начинают обмениваться ICMP-пакетами, каждый коммутатор использует свои MAC-таблицы для передачи пакетов только на целевые порты.
Вторая запись в MAC-таблицу коммутатора №1 и №2
Если с компьютера №3 отправить запрос «ping» на компьютер №2, произойдет ARP-обмен данными между устройствами. Коммутаторы сохранят необходимые записи в своих MAC-таблицах, и ICMP-пакеты будут передаваться в соответствии с этими таблицами.
Третья запись в MAC-таблицу коммутатора №1 и №2
❯ Особенности работы с несколькими коммутаторами
У каждого коммутатора своя уникальная MAC-таблица.
Коммутатор №2 может иметь одну запись для порта с несколькими устройствами, подключенными через другой коммутатор.
Каждый коммутатор формирует свою MAC-таблицу, основываясь на трафике, проходящем через его порты. Чем больше устройств подключено за одним портом, тем больше записей будет ассоциировано с этим портом. Однако даже в сложных сетях коммутаторы эффективно справляются с передачей пакетов, минимизируя нагрузку на сеть.
❯ Заключение
Подводя итоги, мы рассмотрели ключевые устройства и их функции в сетях, такие как коммутаторы и маршрутизаторы, их различия и области применения. Также мы разобрали базовые принципы работы сетей на примере нескольких подключенных устройств, ARP-запросов, ICMP-протокола и их взаимодействия.
Важно отметить, что в этой статье мы не рассматривали работу маршрутизаторов в более сложных сетевых топологиях. В следующей статье мы разберем, как работают маршрутизаторы, как сегментировать сеть, зачем это нужно и как это влияет на масштабируемость и управление.
Эти знания помогут глубже понять основы проектирования сетей и взаимодействия их компонентов.
Написано специально для Timeweb Cloudи читателей Пикабу. Больше интересных статей и новостей в нашемблоге на Хабре и телеграм-канале.
Хочешь стать автором (или уже состоявшийся автор) и есть, чем интересным поделиться в рамках наших блогов — пиши сюда.
Как пелось в одной песне - We're going down, down, all the way down We're heading deeper down going down > Ph'nglui mglw'nafh Cthulhu R'lyeh wgah'nagl fhtagn
Все началось с того, что мне прислали очередную ссылку на разговор в российской майнинг-группе. Некий юзер начал плакать – как так, у меня NVME не дает в raid больше 100к IOPS, как страшно жить, ведь отдельный Samsung обещает : Samsung 980 Pro SSD Random Write 4K QD32 Up to 1,000,000 IOPS Samsung 990 PRO - while 4TB even higher random read speed of up to 1,600K IOPS.
Samsung обещает. Не забывая про то, что там стоит памяти 4 гб - Samsung 4GB Low Power DDR4 SDRAM Но есть нюанс. Давать то дает, но не под постоянной нагрузкой, и поэтому для бизнес-задач с нагрузкой 24*7 не годится – будут непредсказуемые падения скорости, когда контроллер решит заняться внутренними операциями.
Дальнейшая дискуссия между сторонами показала, что ни ноющему, ни основному составу майнинг-группы не понятно, зачем ему нужно именно столько, и куда он будет их девать.
Я, в свою очередь, очень удивился – откуда у людей руки растут. Пошел спросил результаты тестов у других коллег на одиноких NVME, без всяких железных raid. Seq WR, все такое.
Блок 4к, зеркало, очередь 16 , 100% чтение – 1600к IOPS Блок 4к, зеркало, очередь 16 , 70/30 чтение – 850k IOPS на чтение, 350k IOPS на запись Блок 64к, зеркало, очередь 16 , 100% чтение – 650к IOPS Блок 64к, зеркало, очередь 16 , 70/30 – 250k / 100 k IOPS Блок 64к, зеркало, очередь 16 , 100% запись – 150 k IOPS
Результаты, конечно, не показательны - разве что для того, чтобы было с чего разговор начинать. Значимо (в 1.5 раза) влияет и число потоков на файл (точнее, соотношение числа ядер процессоров и потоков на файл – как пишут в руководствах, In general it is recommended to use 1 CPU for testing and use the same number of threads), и количество файлов, точнее используемых в тесте разделов, и тонкие или толстые диски, и так далее. В тестах выше был MS Server 2019, это тоже имеет значение – в MS Server 2025 обещали улучшить работу с NVME
На все это намазывается не только размер блоков, но и число выделяемых дескрипторов\очередей \прочего (внутри СХД, внутри системы, внутри везде, как тех же буферных кредитов – от которых можно получить Slow-Drain), особенно если у вас не локальные диски, а СХД. И все равно в реальном мире можно нарваться на, цитата:
Setup: Dorado 18000, iSCSI, ESXi 7.0.3 (2x25Gb)
На виртуальном диске 100 ГБ запускаю нагрузку FIO 70% read, IO Size 32 KB, вижу на datastore и на dorado одинаковый Read IO Request Size 32 KB.
На виртуальном диске 1024 ГБ тот же тест, та же нагрузка. На ВМ вижу 32 KB, на Datastore уже 25-26 KB на чтение. Запись идёт так же 32 KB. На Dorado соответственно тоже видно на чтение блок стал 25-26 KB.
Решение: Причина мультипликации IO и несоответствия размеров блоков установлена!
Проблема возникает при превышении объёма в 32 ТБ открытых VMDK файлов на хосте.
Накладные IO вызваны нехваткой кэша указателей блоков для открытых vmdk файлов.
Этот кэш необходим для быстрого обращения к открытым блокам VMFS без дополнительного доступа к метаданным из файловой системы.
При утилизации кэша больше 80% включается механизм вытеснения блоков указателей.
Вытесняются наименее активные блоки указатели и включаются (с чтением метаданных с vmfs) новые блоки. Отсюда возникает полученный нами overhead, т.к. нагрузочное тестирование, что FIO, что vdbench запрашивает блоки хаотично и по всему объёму.
Размер кэша задаётся advanced параметром:
VMFS3.MaxAddressableSpaceTB = 32 - Maximum size of all open files that VMFS cache will support before eviction mechanisms kick in
Его максимальное значение 128. При установке 128 - проблема с накладными IO в тестах уходит. Можно для целей тестирования выставить его в 128.
Увеличение кэша ведёт к накладным расходам по памяти, при значении по умолчанию 32 используется 128 МБ памяти. При максимальном значении 128 используется 512 МБ оперативной памяти.
В прод нагрузке вряд ли стоит увеличивать этот кэш, но посмотреть по хостам можно занятые объёмы кэшей командой:
esxcli storage vmfs pbcache get
В реальной жизни нет нагрузки со 100% активными блоками, как в синтетических тестах. Если, к примеру, активны только 20% всех блоков открытых VMDK и их указатели, соответственно попадают в кэш, то мы сможем иметь 160 ТБ открытых VMDK на хосте, при этом активные блоки указателей по-прежнему кэшируются без особого снижения производительности.
Поэтому ответ на исходный вопрос «Но хотя-бы 400k IOPS почему никак не вытаскиваются из одного сервера с 10 дисков-то?» - простой. Наймите специалиста, если сами не можете. Все вытаскивается.
Дальше мне стало интересно, что же используют чуть более богатые фирмы, которые могут себе позволить потратить денег. Оказалось, достаточно много всего, но, как всегда – есть нюансы.
Пропустим ту часть, где обсуждается «зачем столько». Сын маминой подруги сказал что можно, и дальше по классике - НЕТ ДЕНЕГ НЕТ @ НЕТ Я АДМИН @ Я НИЧЕГО В ЭТОМ НЕ ПОНИМАЮ @ ЭТО ГОСКОНТОРА ВЗЯЛИ МЕНЯ
Проблема применимости, про нее не стоит забывать. Если у вас хотя бы 3-4 сервера с дисками, то зачем вам локальный RAID при наличии S2D и vSAN? Что с S2D, что с vSAN на 6-8 серверов можно получить 1-5 миллионов IOPS на чтение блоком 4к, при этом имея (с оговорками) и erasure coding, и, для S2D, ReFS Mirror-accelerated parity, и Data Deduplication, и в vSAN тоже много чего есть, и будет больше.
Но, к делу.
Что может выдать контроллер Broadcom MegaRAID 9670W-16i ? Посмотрим. Broadcom MegaRAID 9670W-16i RAID Card Review. Выглядит неплохо – до 240 SAS/SATA, до 32 NVME. Но, как только дело доходит до записи, все становится не так неплохо: для RAID 10 – Optimal 4KB Random Reads (IOPs) - 7,006,027 4KB Random Writes (IOPs) - 2,167,101
Но, есть нюанс. Broadcom MegaRAID 9670W-16i - Storage controller (RAID) - 16 Channel - SATA 6Gb/s / SAS 24Gb/s / PCIe 4.0 (NVMe) 05-50113-00 – 1500$.
В соседнем тексте упомянули Adaptec 3258upc32ix2s Cc 3258upc32ix2s Smartraid - 2000$. Тоже не очень дешевое решение для старого сервера.
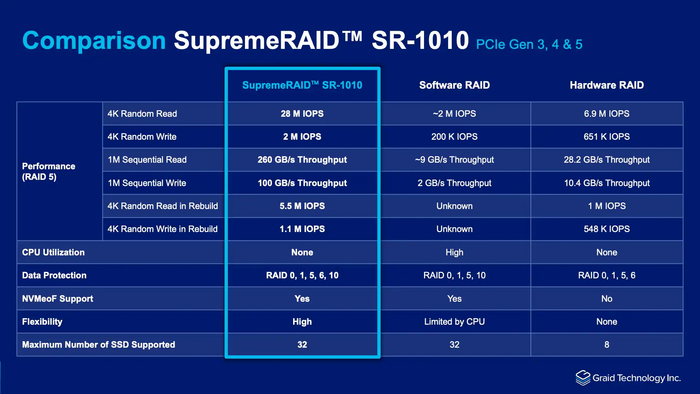
With a single SupremeRAID™ card, users can achieve extraordinary results, boasting up to 28M IOPS and 260GB/s. Supporting up to 32 native NVMe drives, it empowers exceptional NVMe/NVMeoF performance while enhancing scalability, server lifespan, and cost-effectiveness. Supermicro and SupremeRAID™ Data Protection Solution
Performance results with SupremeRAID™ software version 1.5 on SupremeRAID™ SR-1010 2 миллиона IOPS в R5 на запись, пожалуйста.
Performance results with SupremeRAID™ software version 1.5 on SupremeRAID™ SR-1010
Но, есть нюанс. Graid SupremeRAID GRAID-1000 - 2600 $. Graid SupremeRAID SR-1010 - 4000 $.
Да при том. Graid SupremeRAID™ SR-1010 – это RTX A2000 (Ampere), и ее еще 70 ватт сверху, к и так не холодным NVME и CPU.
Вы, конечно, спросите, зачем это все?
И правильно сделаете. Идут такие решения, и подобное для тех, кому слишком дорого взять Nvidia DGX (Deep GPU Xceleration). Дело не только в «дорого». Набор для начинающих «по взрослому» - Nvidia DGX GB200 NVL72: 120 киловатт. 1.4 тонны. Водяное охлаждение. На 1 (одну) стойку. Поэтому Equinix уже год рассказывает, какие они молодцы, и они на самом деле молодцы – столько электричества подвести, и столько тепла вывести, это вам не стойки по 5 киловатт на луч продавать.
У кого же денег не просто много, а неприлично много, и так знают те три слова, что я узнал в сегодня лет: weka, vastdata, vast.ai.
Раньше Kaspersky писал, что VPN не доступен в этой стране. А теперь спокойно включает. Есть настойки, как для устройств так и на комп. Цена 2100 рублей в год, это 175 рублей в месяц.